这次被狠狠的砍了60🔪,由于早上还要上课,晚上还要玩一玩isc/asc,陪npy,所以是没什么时间读paper,都是直接现场听的,只听了自己感兴趣的,同事和未来老板聊了聊他提问了的talk。
3.2 Accelerators
TaskStream
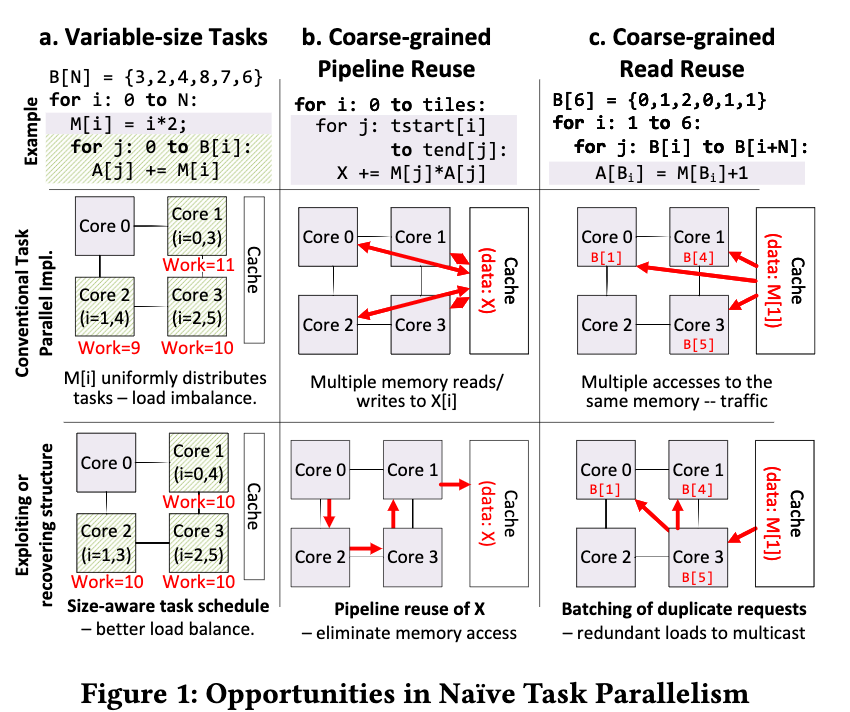
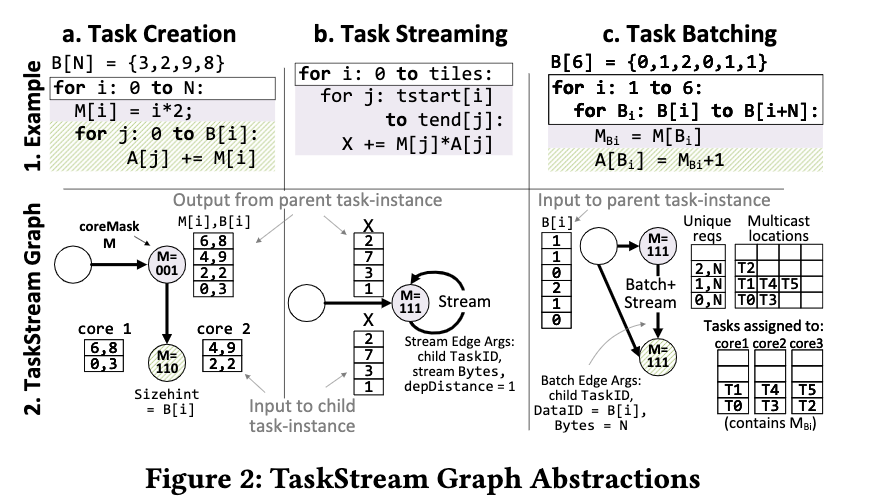
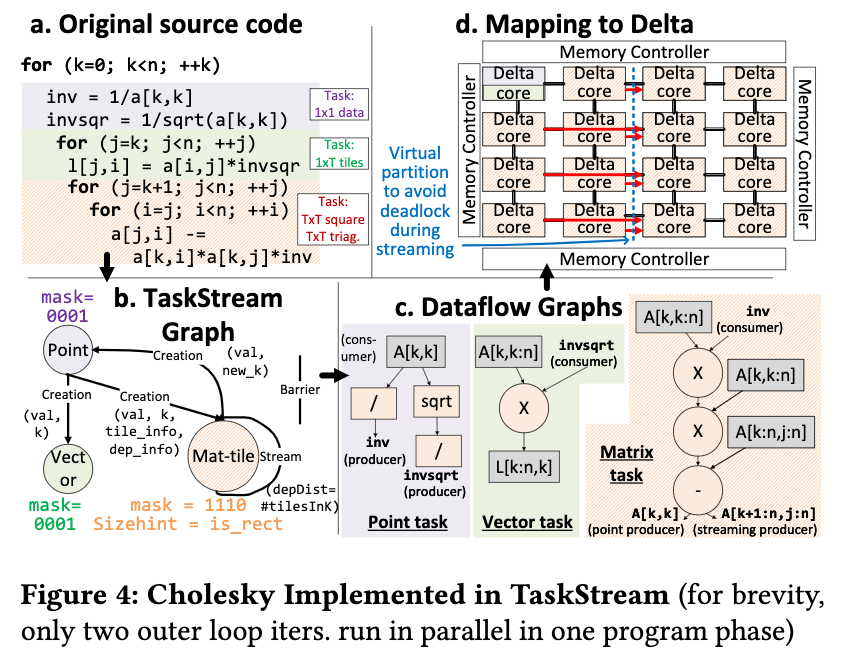
用batch+stream 的方法调度算法。主要是矩阵乘法。
3.2 Address and Memory
Parallel virtualized memory translation with nested elastic cuckoo page tables
Joseph 大师的,同时也是南联盟大师jovan的
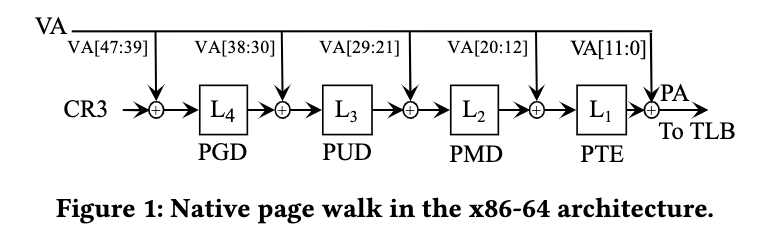
Native page walk in the x86-64 architecture requires 4 memory access for 1GB+ overall page sizes.
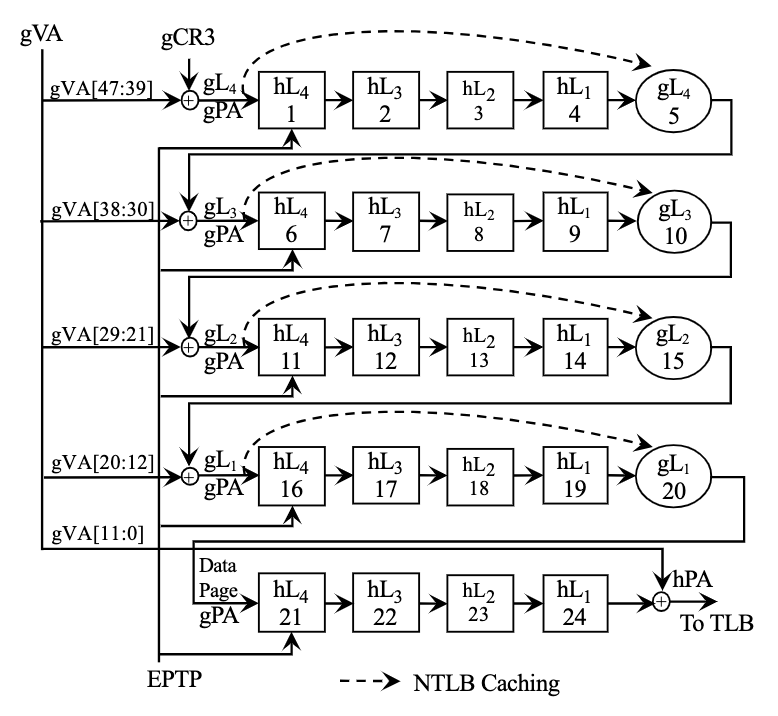
Virtualized EPT. guested VA 需要多加一次translate gVA 到 $gL_i$ table 的memory access和一次$hL_i$ 到 $gL_i$的walk,若是没找到需要遍历上述过程4倍,最多24次reference。对于 huge page 来说,内部的 $hL_2$ 和 $hL_3$ 的部分不用访问。 $64GB/1M< 2^{9*3}$。Hashed Page Table 是Radix Page Table的替代,在risc/IA-64架构中使用。
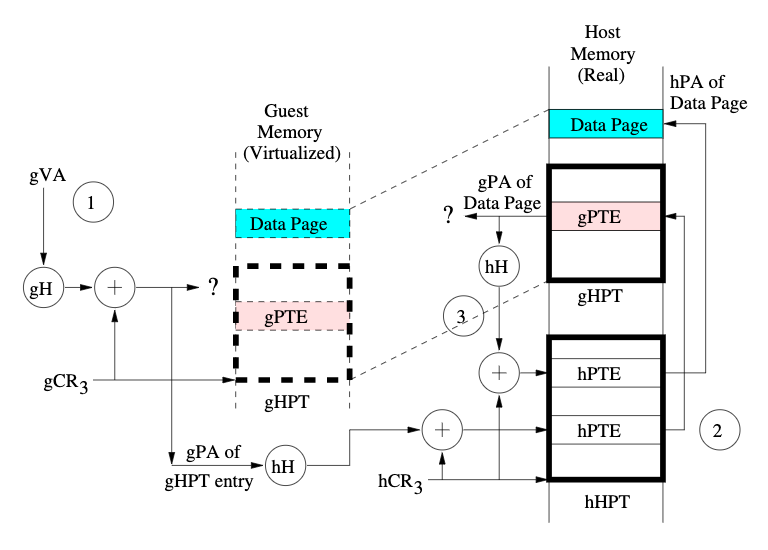
只需要 hHPT->gVA, gVA->gHPT->gPA(虚实),gPA->hHPT->hPA 三次即可获得地址当然内部还要走一次4步,问题是 HPT的碰撞成本太高,single HPT不能支持多页表。

他们设计了基于cuckoo hashing限制walk 步数的多页表,保证多个HPT,也不容易碰撞。
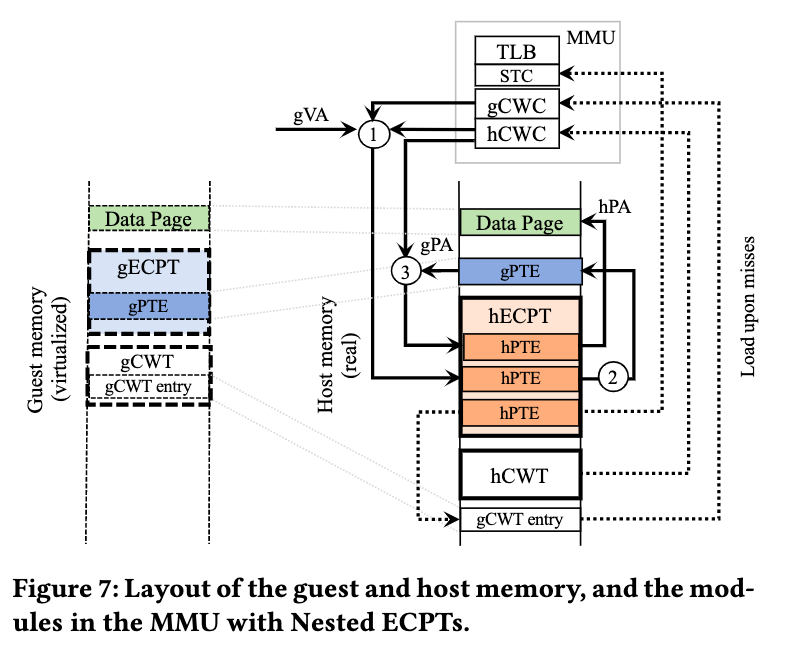
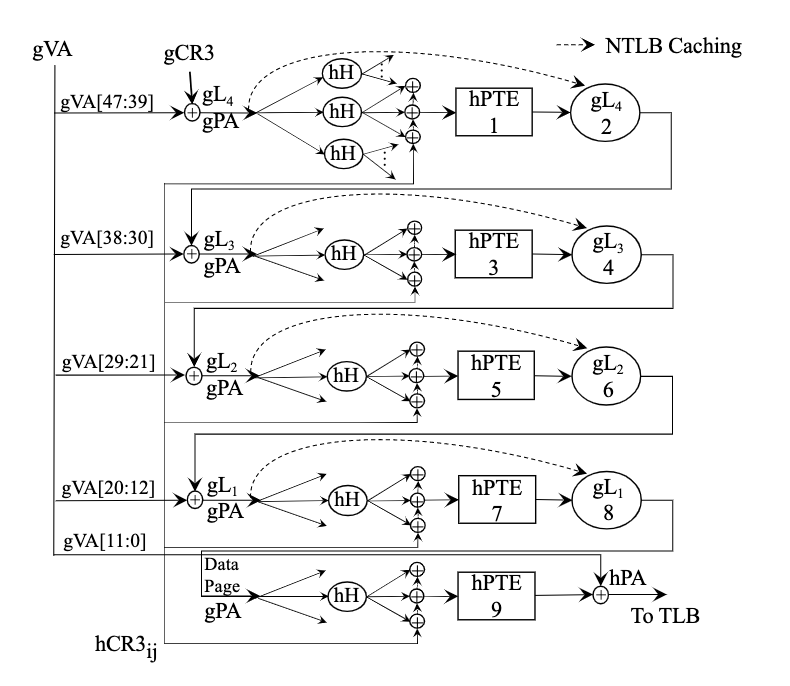
Linux kernel 需要改the memory management code and underthe page table handling 其他都不用动。
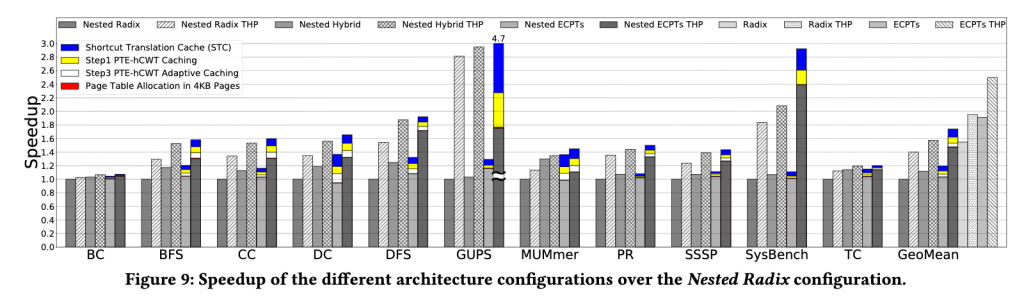
实验结果在pagefault 多的bench上表现良好。
3.3 GPU cloud Session
GPM: Leveraging Persistent Memory from a GPU
之前群里的陈平同学一直就在安利GPU+PM在超算领域非常有作为,现在终于见到一篇。
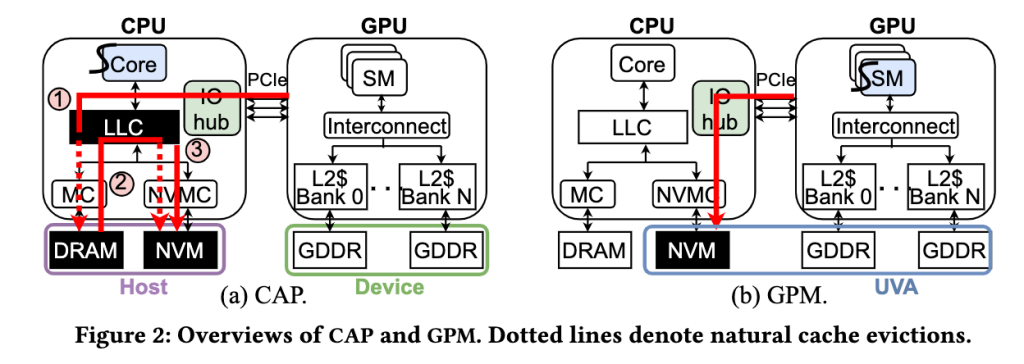
CXL的话是 over PCIe 通道,所以还挺快的。
我感觉对PM特性用的不多。反倒是序列化内存的功夫。
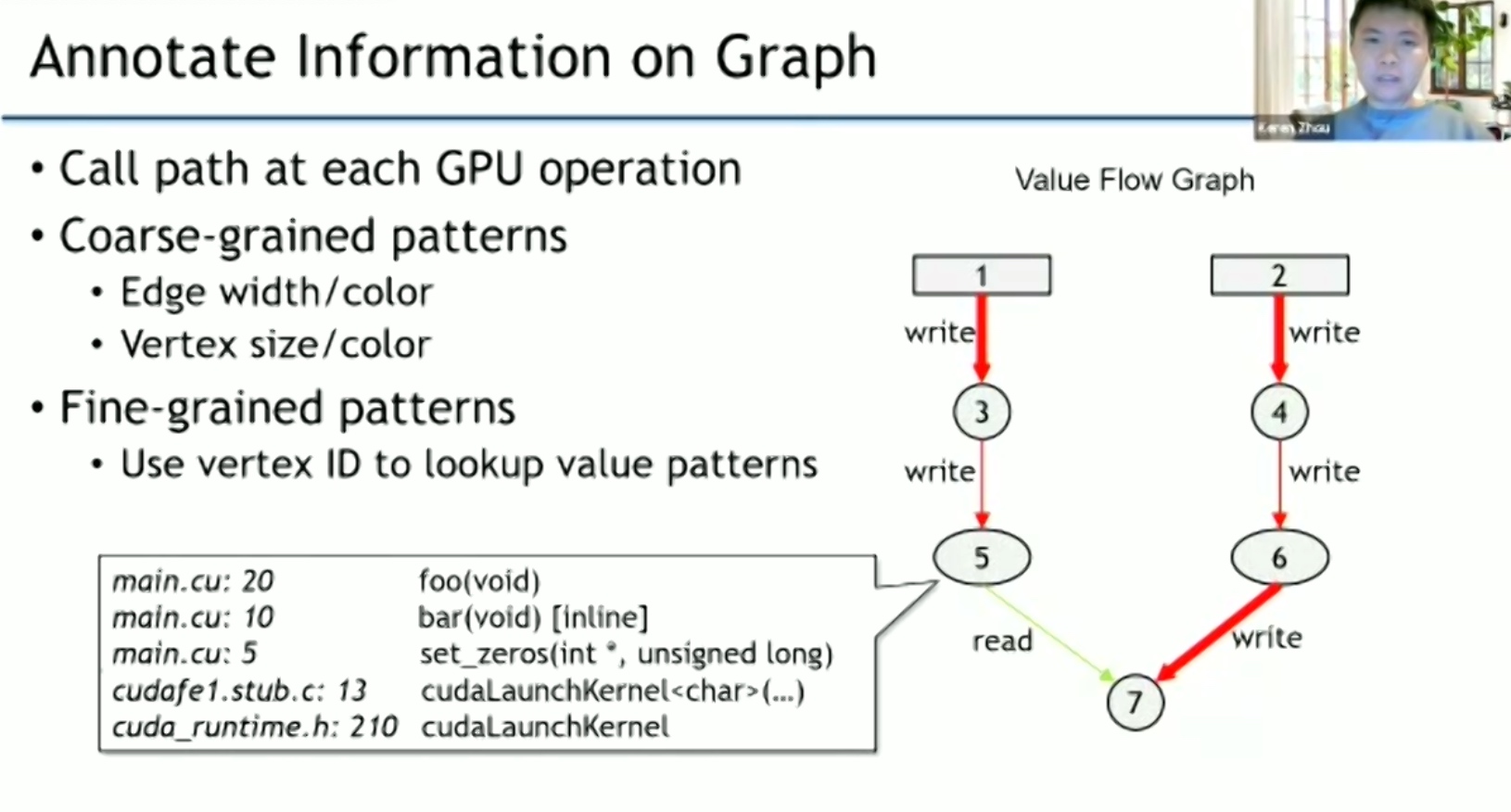
ValueExpert: Exploring Value Patterns in GPU-accelerated Applications
这篇是分析GPU的
GPM: Leveraging Persistent Memory from a GPU
3.4 Operating System Session
Cilo

通过微内核化NIC/L1/L2 做memory的抽象(take care of MR/OS PF)+fast path(硬件关键路径路径)来offloading。实验在ARM SoC FPGA上做的。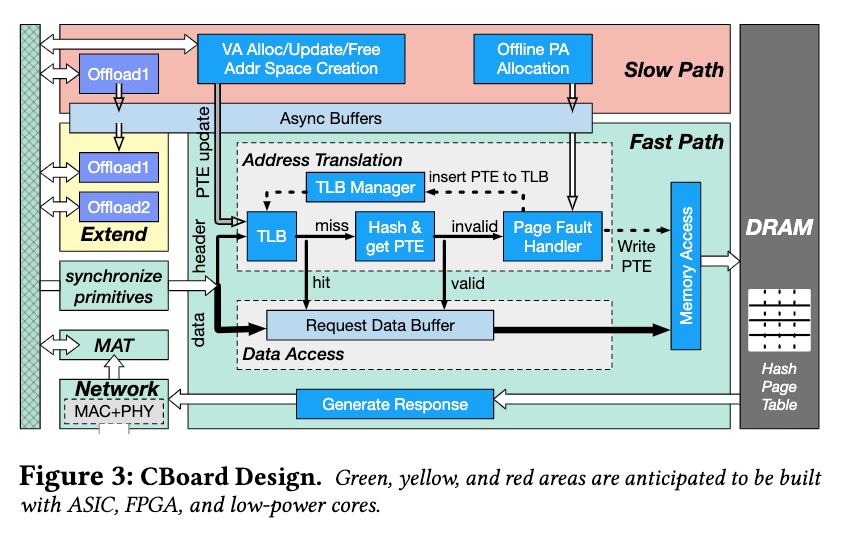
Enzian

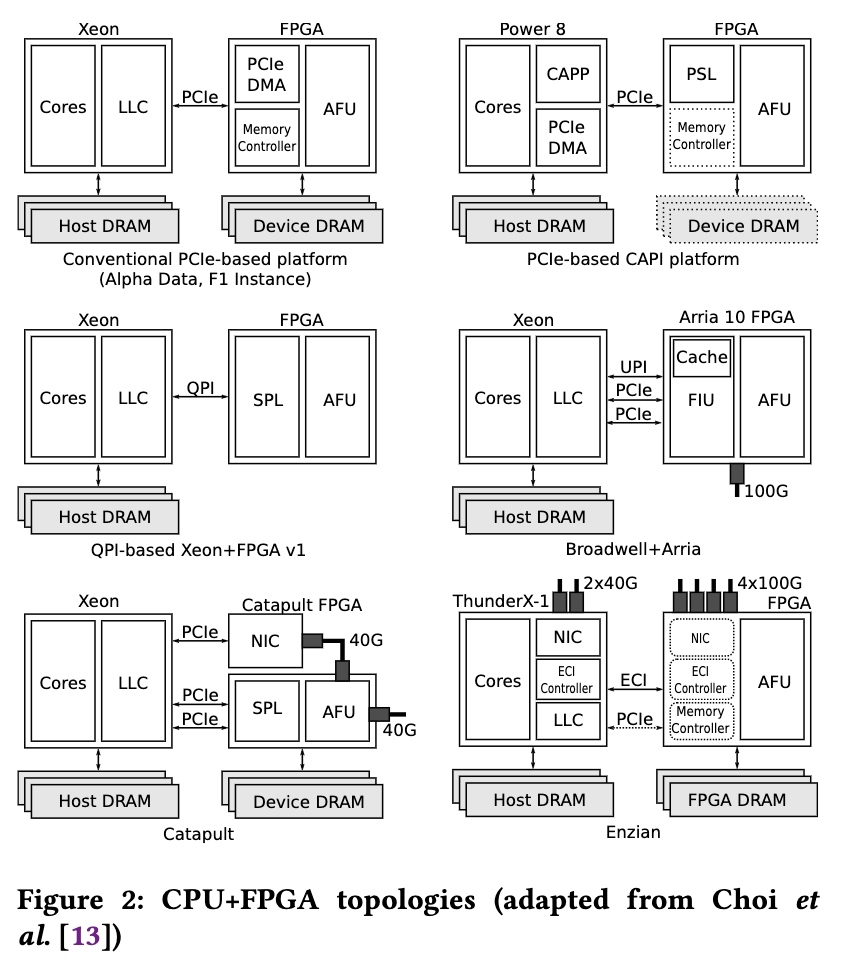
PCIe/CXL + FPGA + DRAM direct
ARM SoC + FPGA
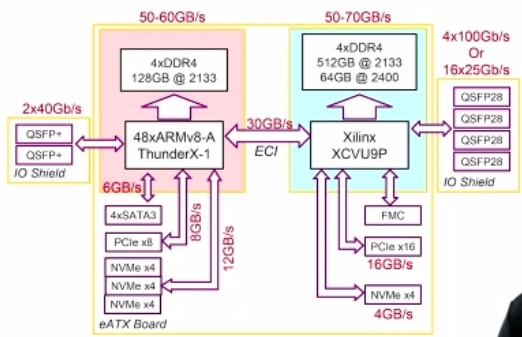
Adapt to emulate all the topology above.
不过马厂ThunderX实在用不了。
- Xuhao luo from UIUC: remote Memory access & distributed memory cache coherency like CXL? Not implemented.

M3v

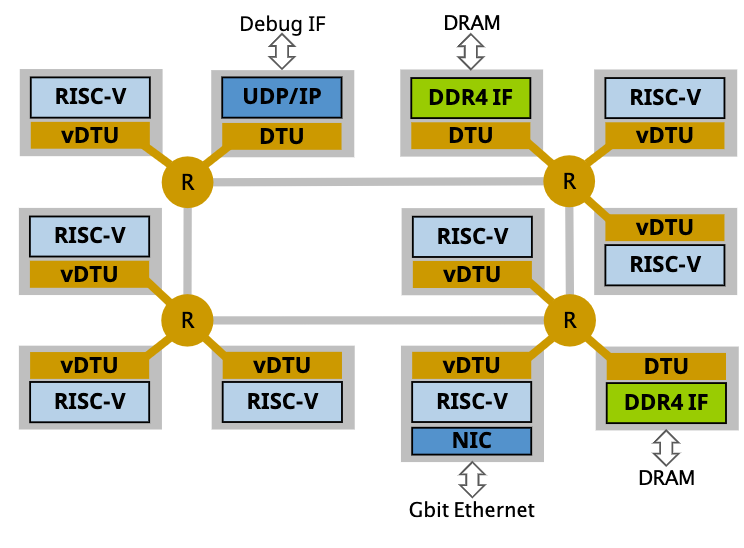
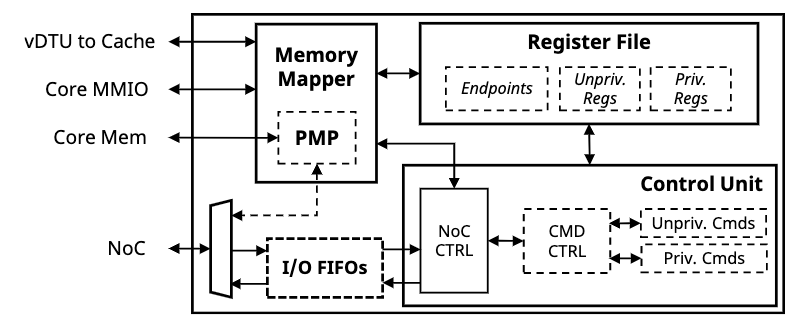
这设计反尔更像可以随意配置的NoC众核,每个vDTU+Core可以模拟多个多种设备。然后在上面会跑BOOM测试性能。
需要考虑Isolation的问题。PMP/ALU/reg/Buffer都需要隔离,很难。
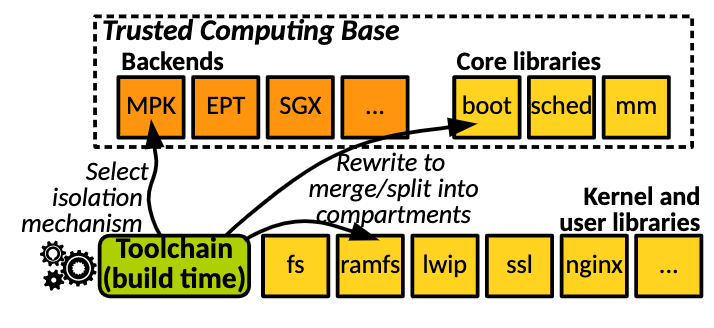
Flex OS
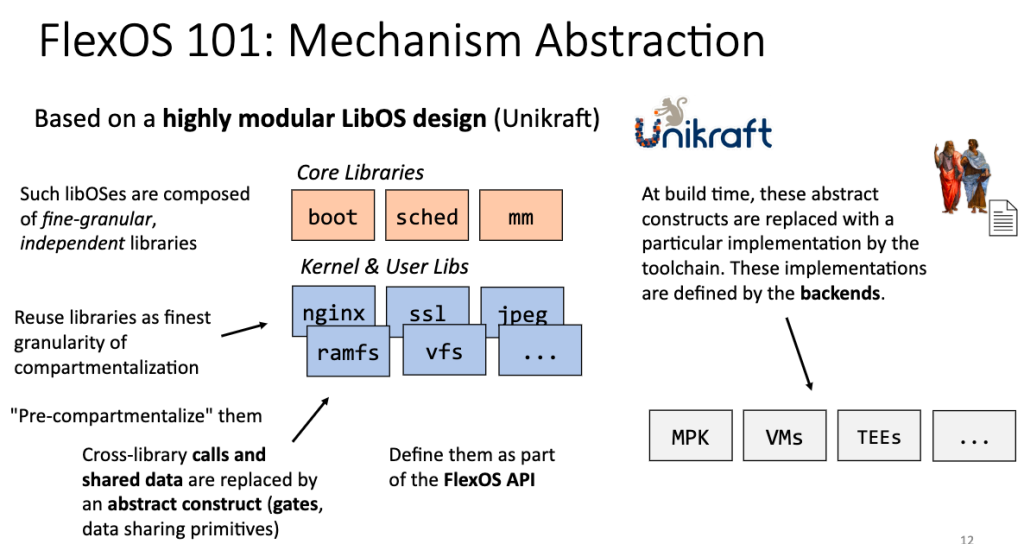

基于1 Unikraft/lib OS 的把安全模块模块化,可接入的设备和core library也模块化。(intel 新出的TDX不就干这个的吗。好吧就是包了个MPK的感觉)

Adelie
关注driver code 不被 JIT ROP/Meltdown/Spectre Variant 2 attacks,需要做ASLR
3.4 Bugs(1)
dead code Optimization
这篇拿了best paper。Su Zhendong真厉害。instrument可能被优化的点,主要是call和control flow,到稍微偏后的位置分析一下,插回来。

3.5 Security(1)
RSSD
大致是用额外的空间来做硬件级别的备份。难点在
paper
问了两个问题:
3.5 Bugs(2)
这个session是我最想听的。
Yashme
通过预设的pre-crash的condition 找对应的post crash execution 是否满足,但是大多数的bug被eADR解决了。下面是一个eADR存在也会有的bug。
比如有一个变量的写被分成两个写 x 和 y,被编译器和CPU弄成下述顺序,如果我的程序执行到x,然后在y之前崩溃了。
…
x
——— Program crash
Y
…x 会在 cache 里, 但 y 不会。因此,恢复程序需要正确处理x存在而y不存在的情况,这非常困难。在这种情况下,Yashme 才是有用的,如果加上这个,感觉这个工作才算完整,虽然才找出来24个bug我觉得做这个没什么意思。
Path-Sensitive and Alias-Aware Typestate Analysis for Detecting OS Bugs
这篇是Path based alias 做 kernel 里的 null pointer dereference 的检测。这是一个可能出现npd的案例。

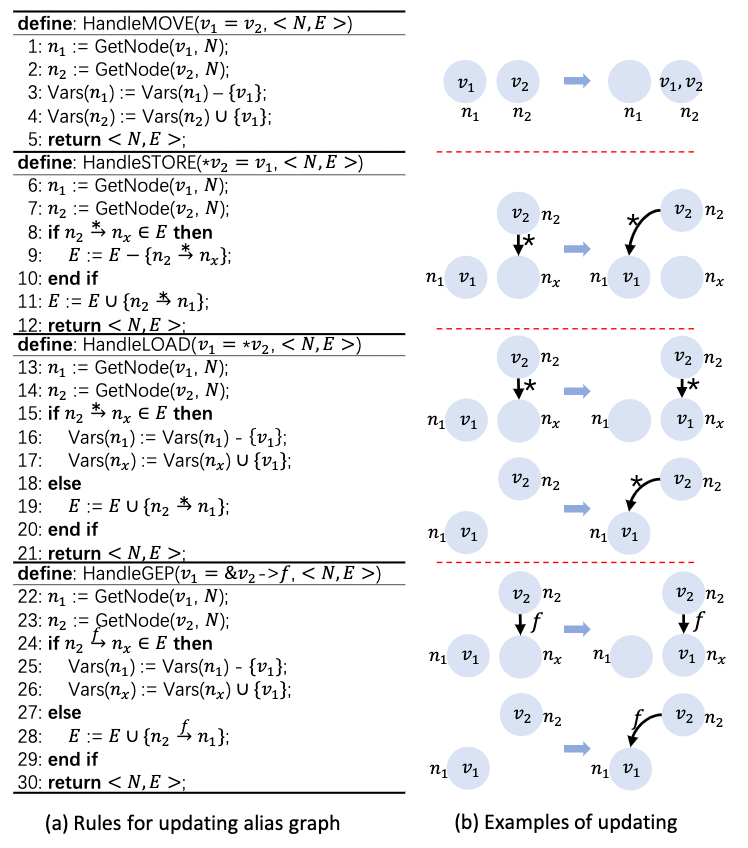
定义完了过程丢进Z3求解path feasibility。
A Tree Clock Data Structure for Causal Orderings in Concurrent Executions
这篇也是 best paper,来自UIUC,用树结构记录fork join 的clock,文中最多三倍thread数复杂度。

可以拓展更多的可能性。RPC co-rountine programming都能用这个。
Efficiently Detecting Concurrency Bugs in Persistent Memory Programs



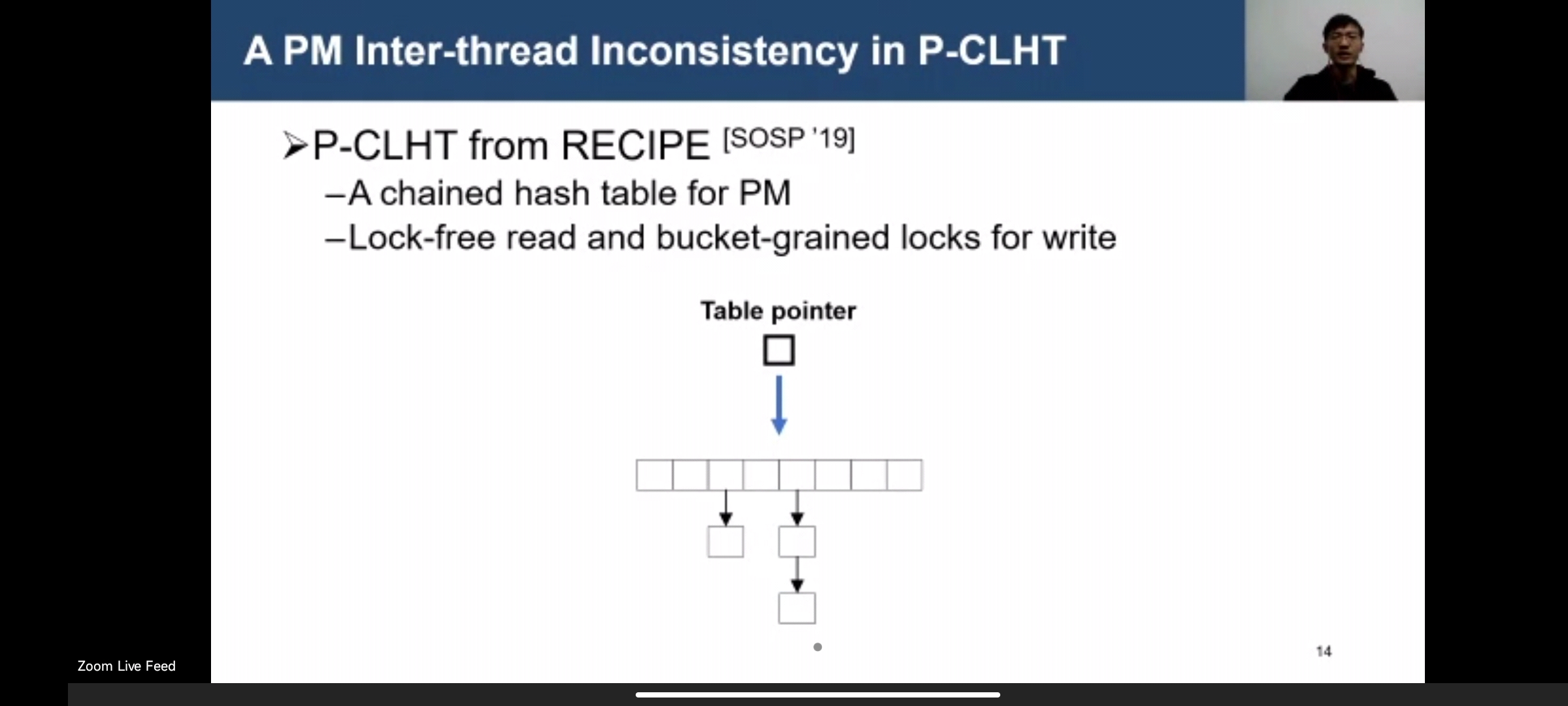
都是很老生常谈的bug。但是实验在比较新的project中找。
Go concurrency bug.
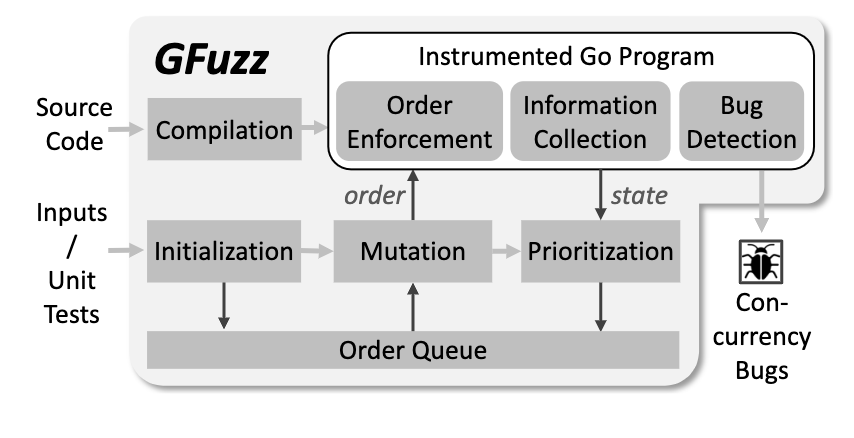
在go channel里面bug来自message ordering,所以需要block+reorder。所以fuzz基于order的mutation。然后就开始玄学了。

3.5 Reconfiguratble Hardware
Debug in FPGA
老板和家晨的文章。用software的思维fix FPGA的bug
FPGA的bug分为Data Mis-access Bugs(buffer overflow/Bit Truncation/Misindexing/Endianness Mismatch)/Communication Bugs(Deadlock/Producer-Consumer Mismatch/Signal Asynchrony/Use-without-Valid)/Semantic(Protocol Violation/ API Misuse/Incomplete Implementation/Erroneous Expression.)
绝大多数上述的bug都可以通过mutation变量的方法,找到并修复。可以把所有bug simulate 出来,pattern matching上述可能出现的bug。
First, FSM Monitor statically detects FSM variables and records them at runtime, automatically reconstructing FSM state-transition traces to aid developers in debugging. Second, Dependency Monitor statically analyzes the dependencies of user-specified variables and dynamically records the updates to each dependency, allowing developers to backtrace and localize the source of an incorrect output-of-interest. Third, Statistics Monitor provides counters for user-specified events, helping users identify bugs reflected in statistical metadata (e.g., data loss is often indicated by fewer outputs generated than inputs received). Finally, given the commonality of data loss in our bug symptoms, we develop an additional tool for the event that a developer suspects or detects data loss.
SIgnalCat Logging design with a printf-like statement and support simulation and on-FPGA debugging with a single code-base.
大家可以去看看他们的code
3.5 Serverless
FaasFlow
Function as a service 对于serverless的机器再一步进行细分(Worker side workflow schedule pattern),一个函数或者一个process作为一个workflow,算出DAG后有调度器进行细粒度调度,同时有数据依赖的储存调度。(Slurm docker 化?)
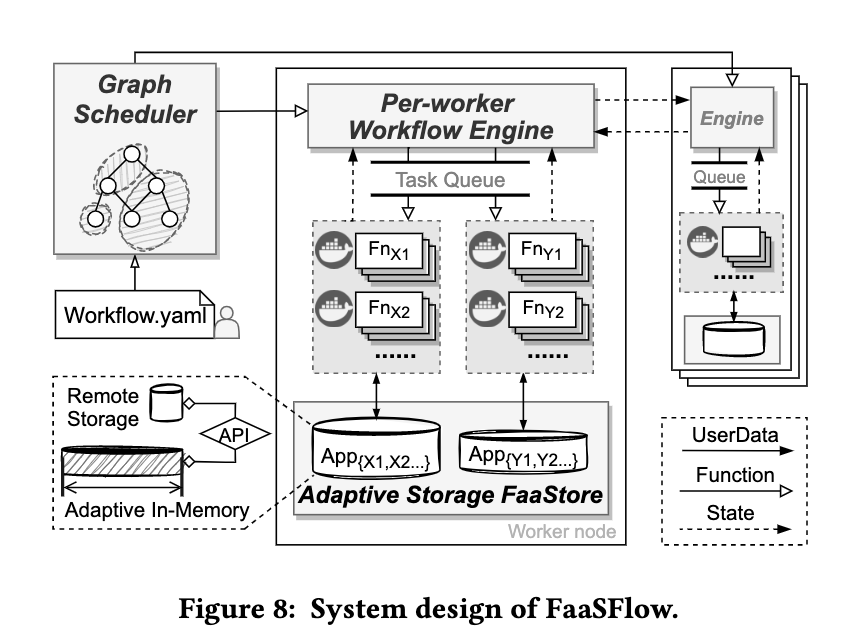
Serverless Computing on Heterogeneous Computers
这篇是杜东大师的。
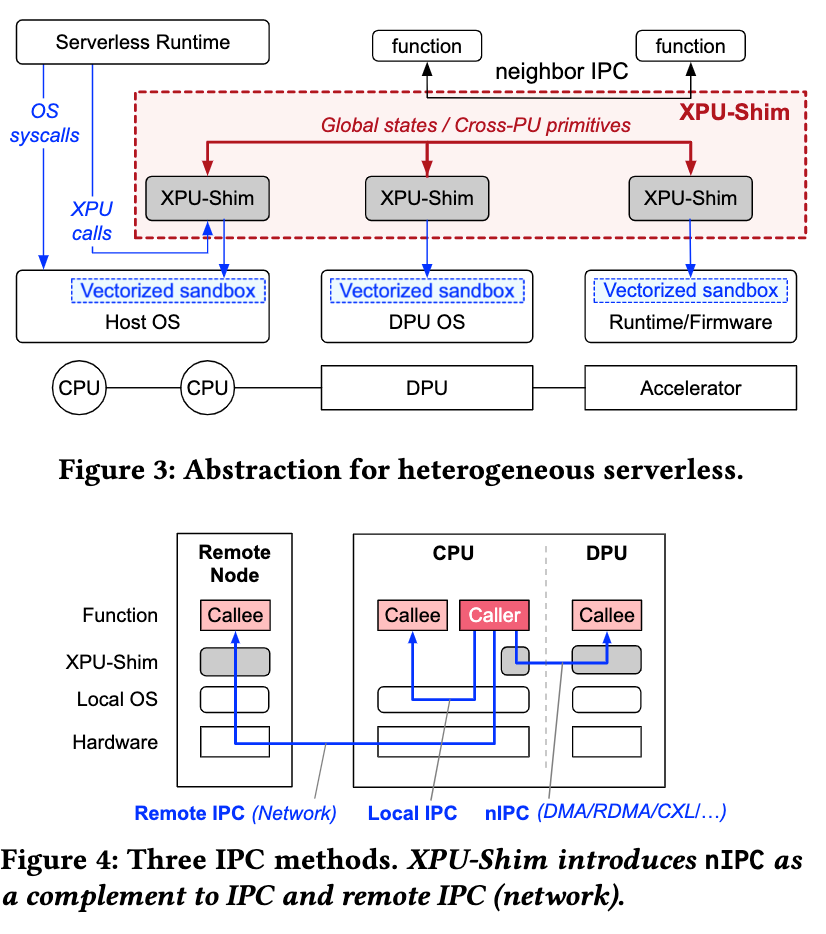
Heterogeneous 设备serverless抽象 XPU-shim
3.5 Hardware Security (2)
ShEF
对FPGA的enclave,把所有对内存的访问过程(数据流)有类似SGX加密/解密操作

The SGX ISAextensions allow users to directly access hardware mechanisms toboot an enclave (ECREATE, EADD, EXTEND, and EINIT), generatean attestation report and provision secrets (EREPORT), and pro-vide isolated execution (EENTER and EEXIT, and SGX MEE). Similarly, Keystone relies on a security monitor running in the RISC-V machine mode with control over ISA-defined Physical Memory Protection registers in order to enforce memory isolation. 对于 Cloud FPGA来说,只能通过远端验证来实现经过untrusted shell之后验证key的过程。
3.5 Smart Networking
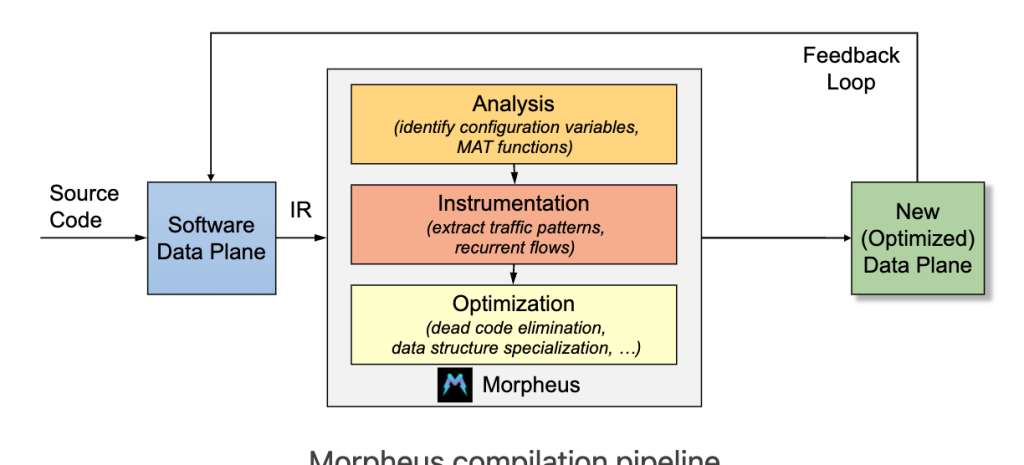
Morpheus
这篇真的闭门红,做的非常好。 动态把MAT functions 编译到 eBPF 和 DPDK 高性能代码。用pcap trace验证正确性。