The code can be viewed on http://victoryang00.xyz:5012/victoryang/sniper_test/tree/lab3
false sharing
For the false sharing test cases. We've given the lab3 cfg file that the cache line is 64B. So that we just need to set the false sharing variable under that cache size.
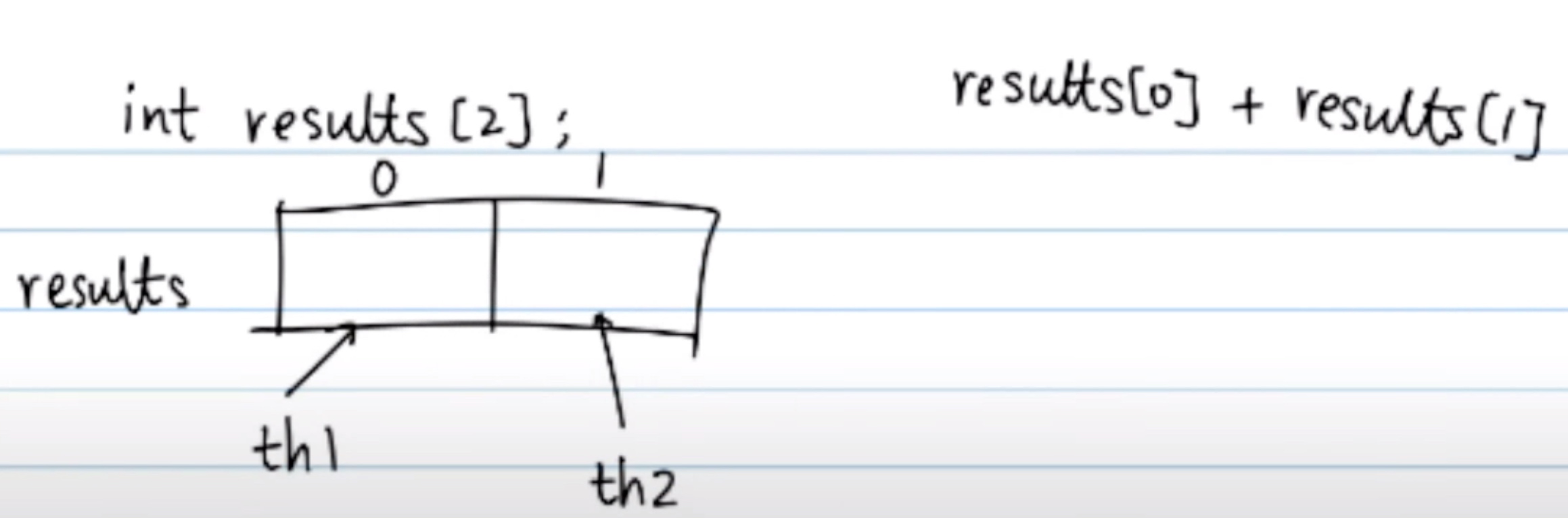
In the false_sharing_bad.c, we open 2 thread to store global variable results with first part th1 visits and the second part th2 visits.
void* myfunc(void *args){
int i;
MY_ARGS* my_args=(MY_ARGS*)args;
int first = my_args->first;
int last = my_args->last;
int id = my_args->id;
// int s=0;
for (i=first;i<last;i++){
results[id]=results[id]+arr[i];
}
return NULL;
}
The result of this in the sniper.
[SNIPER] Warning: Unable to use physical addresses for shared memory simulation.
[SNIPER] Start
[SNIPER] --------------------------------------------------------------------------------
[SNIPER] Sniper using SIFT/trace-driven frontend
[SNIPER] Running full application in DETAILED mode
[SNIPER] --------------------------------------------------------------------------------
[SNIPER] Enabling performance models
[SNIPER] Setting instrumentation mode to DETAILED
[RECORD-TRACE] Using the Pin frontend (sift/recorder)
[TRACE:1] -- DONE --
[TRACE:2] -- DONE --
s1 = 5003015
s2= 5005373
s1+s2= 10008388
[TRACE:0] -- DONE --
[SNIPER] Disabling performance models
[SNIPER] Leaving ROI after 627.88 seconds
[SNIPER] Simulated 445.0M instructions, 192.9M cycles, 2.31 IPC
[SNIPER] Simulation speed 708.8 KIPS (177.2 KIPS / target core - 5643.3ns/instr)
[SNIPER] Setting instrumentation mode to FAST_FORWARD
[SNIPER] End
[SNIPER] Elapsed time: 627.79 seconds
In the false_sharing.c, we open 2 thread to store different local variable s with th1 visits and th2 visits.
void* myfunc(void *args){
int i;
MY_ARGS* my_args=(MY_ARGS*)args;
int first = my_args->first;
int last = my_args->last;
// int id = my_args->id;
int s=0;
for (i=first;i<last;i++){
s=s+arr[i];
}
my_args->result=s;
return NULL;
}
The result of this in the sniper.
[SNIPER] Warning: Unable to use physical addresses for shared memory simulation.
[SNIPER] Start
[SNIPER] --------------------------------------------------------------------------------
[SNIPER] Sniper using SIFT/trace-driven frontend
[SNIPER] Running full application in DETAILED mode
[SNIPER] --------------------------------------------------------------------------------
[SNIPER] Enabling performance models
[SNIPER] Setting instrumentation mode to DETAILED
[RECORD-TRACE] Using the Pin frontend (sift/recorder)
[TRACE:2] -- DONE --
[TRACE:1] -- DONE --
s1 = 5003015
s2= 5003015
s1+s2= 10006030
[TRACE:0] -- DONE --
[SNIPER] Disabling performance models
[SNIPER] Leaving ROI after 533.95 seconds
[SNIPER] Simulated 415.1M instructions, 182.1M cycles, 2.28 IPC
[SNIPER] Simulation speed 777.3 KIPS (194.3 KIPS / target core - 5145.9ns/instr)
[SNIPER] Setting instrumentation mode to FAST_FORWARD
[SNIPER] End
[SNIPER] Elapsed time: 533.99 seconds
The reason of false sharing:
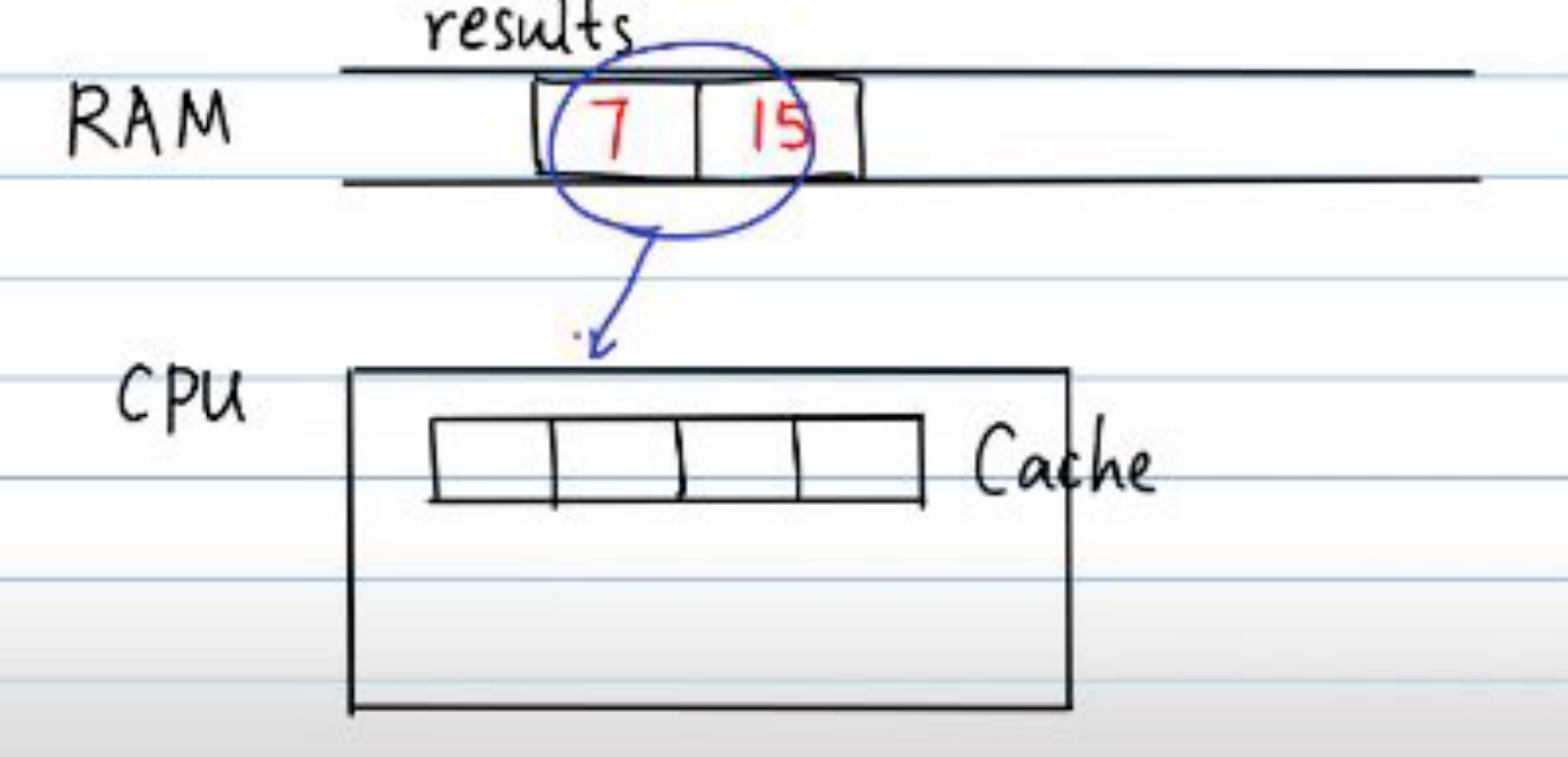
Every time the thread may let the results to get into the CPU cache.
The Cache may check whether the cache part and memory are the same or not, thus trigger the latency, which is false sharing.
The solution of the false sharing:
Just let the adjacent data's distance larger than the one cache line, say 64B. so set FALSE_ARR to 200000.
The result changed to:
[SNIPER] Warning: Unable to use physical addresses for shared memory simulation.
[SNIPER] Start
[SNIPER] --------------------------------------------------------------------------------
[SNIPER] Sniper using SIFT/trace-driven frontend
[SNIPER] Running full application in DETAILED mode
[SNIPER] --------------------------------------------------------------------------------
[SNIPER] Enabling performance models
[SNIPER] Setting instrumentation mode to DETAILED
[RECORD-TRACE] Using the Pin frontend (sift/recorder)
[TRACE:1] -- DONE --
[TRACE:2] -- DONE --
s1 = 5003015
s2= 5005373
s1+s2= 10008388
[TRACE:0] -- DONE --
[SNIPER] Disabling performance models
[SNIPER] Leaving ROI after 512.28 seconds
[SNIPER] Simulated 445.1M instructions, 158.1M cycles, 2.82 IPC
[SNIPER] Simulation speed 868.8 KIPS (217.2 KIPS / target core - 4604.2ns/instr)
[SNIPER] Setting instrumentation mode to FAST_FORWARD
[SNIPER] End
[SNIPER] Elapsed time: 512.22 seconds
multi-level cache
The non-inclusive cach is to remove the back-invalidation and fix one.

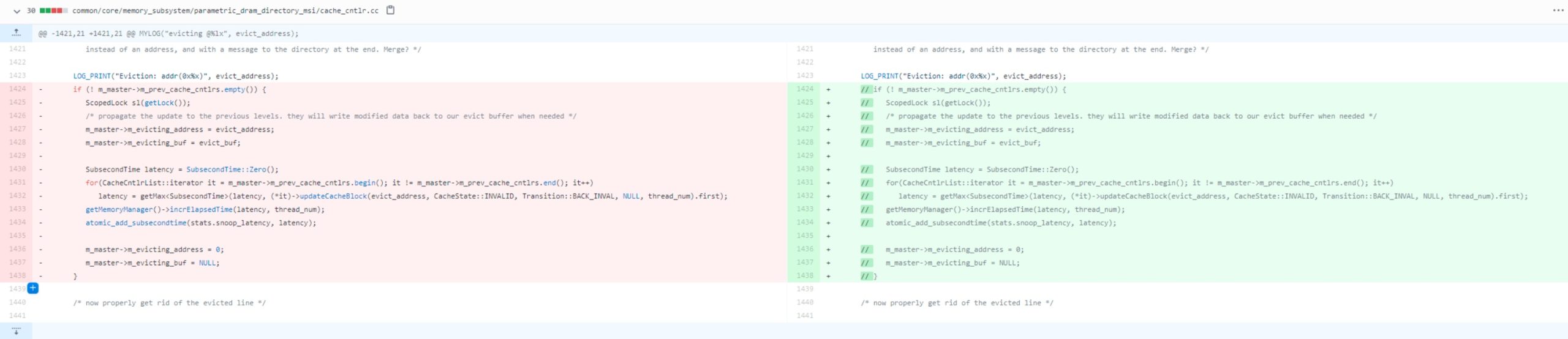
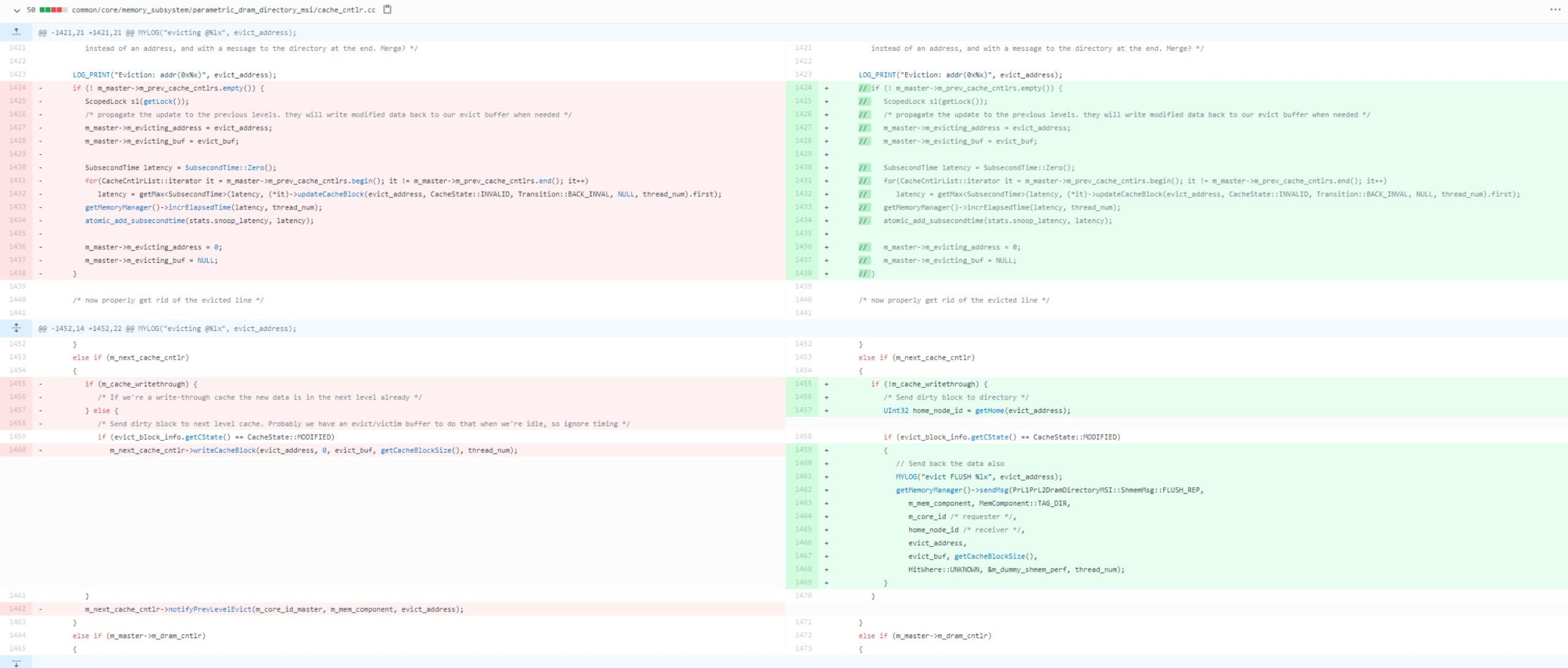
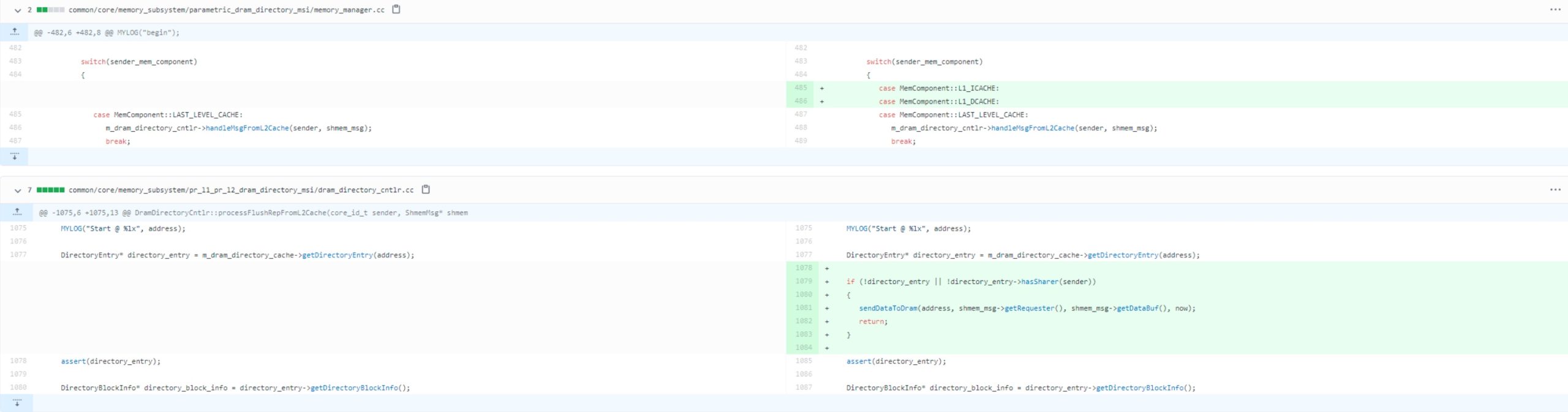
Then I found https://groups.google.com/g/snipersim/c/_NJu8DXCVVs/m/uL3Vo24OAAAJ. That the non-inclusive cache intends to directly write back to the memory. We have to fix some bugs for inclusive cache during the L1 eviction and L2 have to evict, but L2 may not be found, thus the L1 should WB to memory, in this time.
I add a new configuration in the cfg. to make the L1 non-inclusive or not and deployed different Protocol in cfg.
[caching_protocol]
type = parametric_dram_directory_msi
variant = mesif # msi, mesi or mesif
I didn't do a result with a small granularity but with lock_add lock_fill_bucket reader_writer and bfs, I got num of write backs and some WB test for inclusive and non inclusive caches.
Test
Lock Add: In this test all the threads try to add ‘1’ to a global counter using locks. We see lower number of memory writebacks in MOSI because of the presence of the owner state.
Lock Fill Bucket: This tests makes buckets for numbers, so that it can count how many times each number is present in the array. This is done using locks. The dragon protocol is performing much worse here compared to others. This is probably because updates to the buckets are not always needed by other processors, hence the updates on the writes do not help.
Result
Protocol
| Protocol\IPC |
lock_add |
lock_fill_bucket |
reader_writer |
bfs |
| MSI |
1.31 |
1.32 |
1.27 |
1.39 |
| MESI |
1.35 |
1.36 |
1.29 |
1.39 |
| MESIF |
1.35 |
1.36 |
1.30 |
1.39 |
The MESIF protocol enhances the performance for teh multicore systems. MESIF protocal enhances the performance for multicore system. It may be aware of the micro arch.
CPI stack
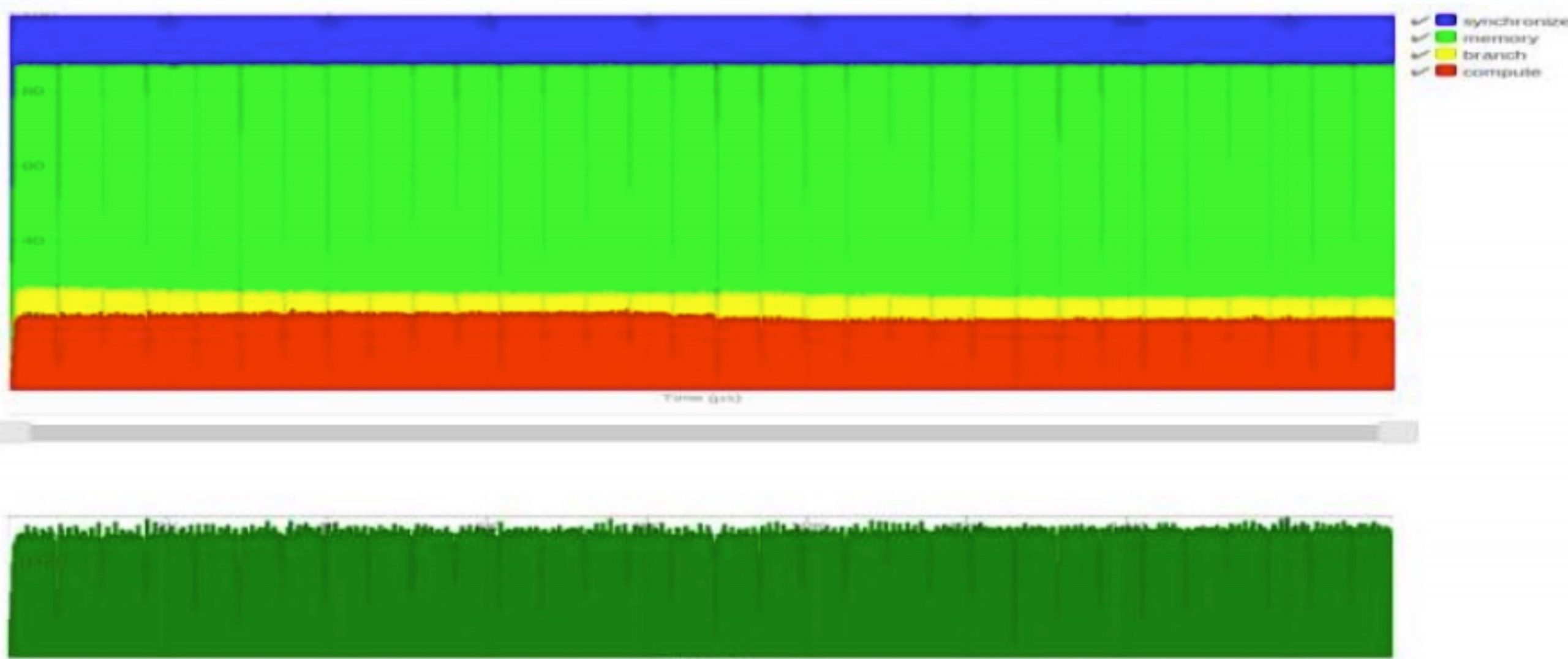
The CPI stack can quantify the cycle gone due to memory branch or sync. literally all of the protocal has similar graph as above. The MESIF shows the lowest time in mem and sync.
| Protocol\L2 miss rate |
lock_add |
lock_fill_bucket |
reader_writer |
bfs |
| MSI |
49.18 |
20.13 |
27.12 |
42.24 |
| MSI (with non-inclusive cache) |
47.98 |
20.01 |
29.12 |
42.13 |
| MESI |
46.21 |
21.13 |
31.29 |
41.31 |
| MESI (with non-inclusive cache) |
45.13 |
21.41 |
26.41 |
42.15 |
| MESIF |
45.71 |
20.12 |
25.14 |
41.39 |
| MESIF (with non-inclusive cache) |
46.35 |
23.14 |
24.14 |
41.13 |
The non-inclusive cache have a better score than inclusive ones in L2 miss rate and MESIF & MESI are better than the MSI.
Summary
Interesting Conclusions
Adding ‘E’ state:
To measure the performance differences caused by adding the Exclusive state to the protocols, we can look at the differences in metrics in MSI vs MESI and MESIF. The main benefit of the Exclusive state is in reducing the number of snooping bus transactions required. If we consider a parallel program where each thread works on a chunk of an array and updates only that chunk, or if we assume a sequential program that has a single thread, then in these cases, there will be a lot of cases where a program is reading a cacheline and updating it. In MSI, this would translate to first loading the cacheline using a BusRd moving to the S state, and then performing a BusRdX and moving to the M state. This requires two snooping bus transactions. In the case of MESI, this can be done in a single transaction. The cache would perform a BusRd moving to the E state and then since no other cache has the cacheline, there is no need of a BusRdX transaction to move to the M state. It can just silently change the status of the cacheline to Modified.
This gives a significant boost in programs which access and modify unique memory addresses.
Write-Invalidation vs Write-Update
Since we have implemented both write invalidation and write update protocols, our simulator can also tell whether for a given program or memory trace, write invalidation protocols will be better or write update.
For a write-invalidation protocol, when a processor writes to a memory location, other processor caches need to invalidate that cacheline. In a write-update protocol, instead of invalidating the cachelines, it sends the updated cacheline to the other caches. Therefore, in cases where the other processors will need to read those values in the future, write-update performs well, but if the other processors are not going to be needing those values, then the updates are not going to be of any use, and will just cause extra bus transactions. Therefore, the effects of the protocol would be completely dependent.
From our tests, we saw lesser number of bus transactions This would explain why updating rather than invalidating reduced the number of bus transactions.
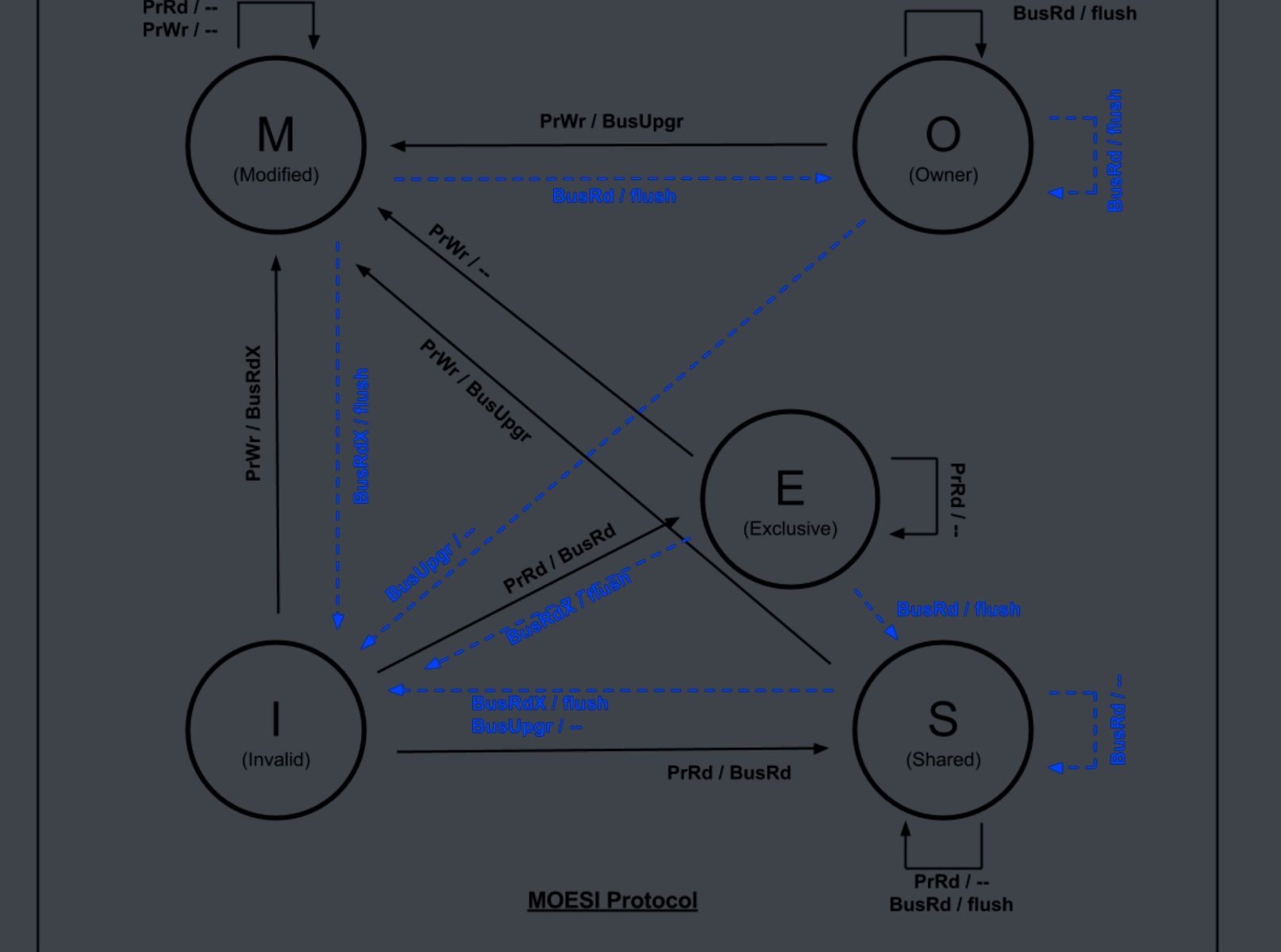
MOESI (Unchecked)
I refer to the graph of
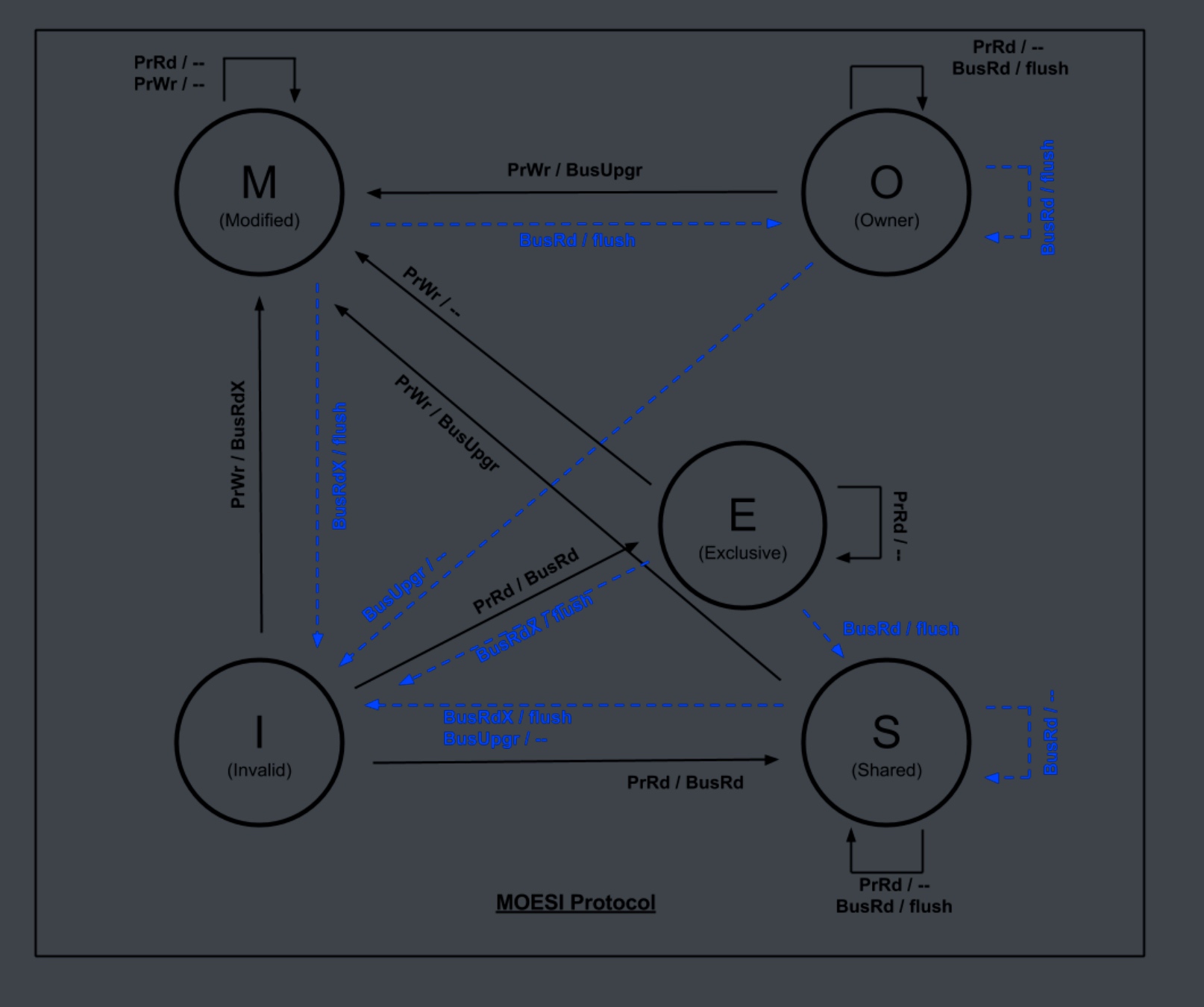
The code is in dir_moesi directory with one state added.
I just make it runnable and not yet tested.
Reference
- https://www.youtube.com/watch?v=3DoBCs7Lyv4
- https://kshitizdange.github.io/