


文章目录[隐藏]
- BEACON: Scalable Near-Data-Processing Accelerators for Genome Analysis near Memory Pool with the CXL Support
- Page Size Aware Cache Prefetching
- Merging Similar Patterns for Hardware Prefetching
- Treebeard: An Optimizing Compiler for Decision Tree Based ML Inference
- OCOLOS: Online COde Layout OptimizationS
- CRONUS: Fault-Isolated, Secure and High-Performance Heterogeneous Computing for Trusted Execution Environments
- GenPIP: In-Memory Acceleration of Genome Analysis by Tight Integration of Basecalling and Read Mapping
- Designing Virtual Memory System of MCM GPUs
- PageORAM: An Efficient DRAM Page Aware ORAM Strategy
- DaxVM: Stressing the Limits of Memory as a File Interface
- Networked SSD: The Flash Memory Interconnection Network for High-Bandwidth SSD
- ASSASIN: Architecture Support for Stream Computing to Accelerate Computational Storage
- ALTOCUMULUS: Scalable Scheduling for Nanosecond-Scale Remote Procedure Calls
- OverGen: Improving FPGA Usability through Domain-specific Overlay Generation
- pLUTo: Enabling Massively Parallel Computation in DRAM via Lookup Tables
- 伟大的香山
- Translation-optimized Memory Compression for Capacity
- Horus: Persistent Security for Extended Persistence-Domain Memory Systems
去是去不了了, 但是还是看了一下paper list.然后发现只要去就能提前看到paper list,这种传统还挺有意思的。
BEACON: Scalable Near-Data-Processing Accelerators for Genome Analysis near Memory Pool with the CXL Support
xieyuan和三星出品的文章,用CXL模拟器(ramulator)做了个CXL PIM,把genomics alignment 的 task map到CXL DIMM(BEACON-D) 和 CXL Switch(BEACON-S)上,后者可以比前者快87%。
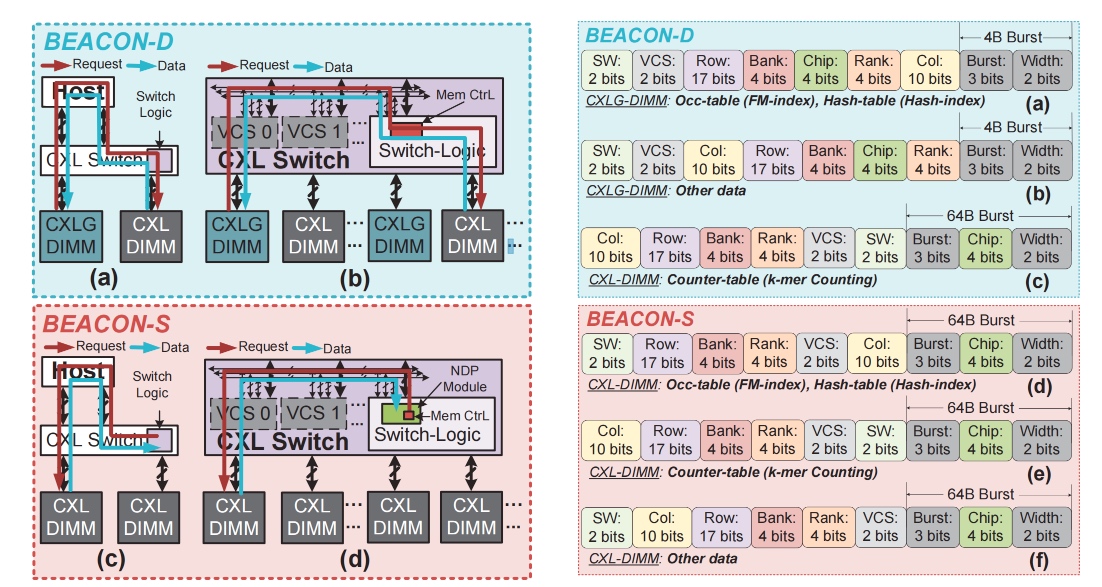
主要是DIMM allocation, Data Migration, Data de-allocation 的策略。
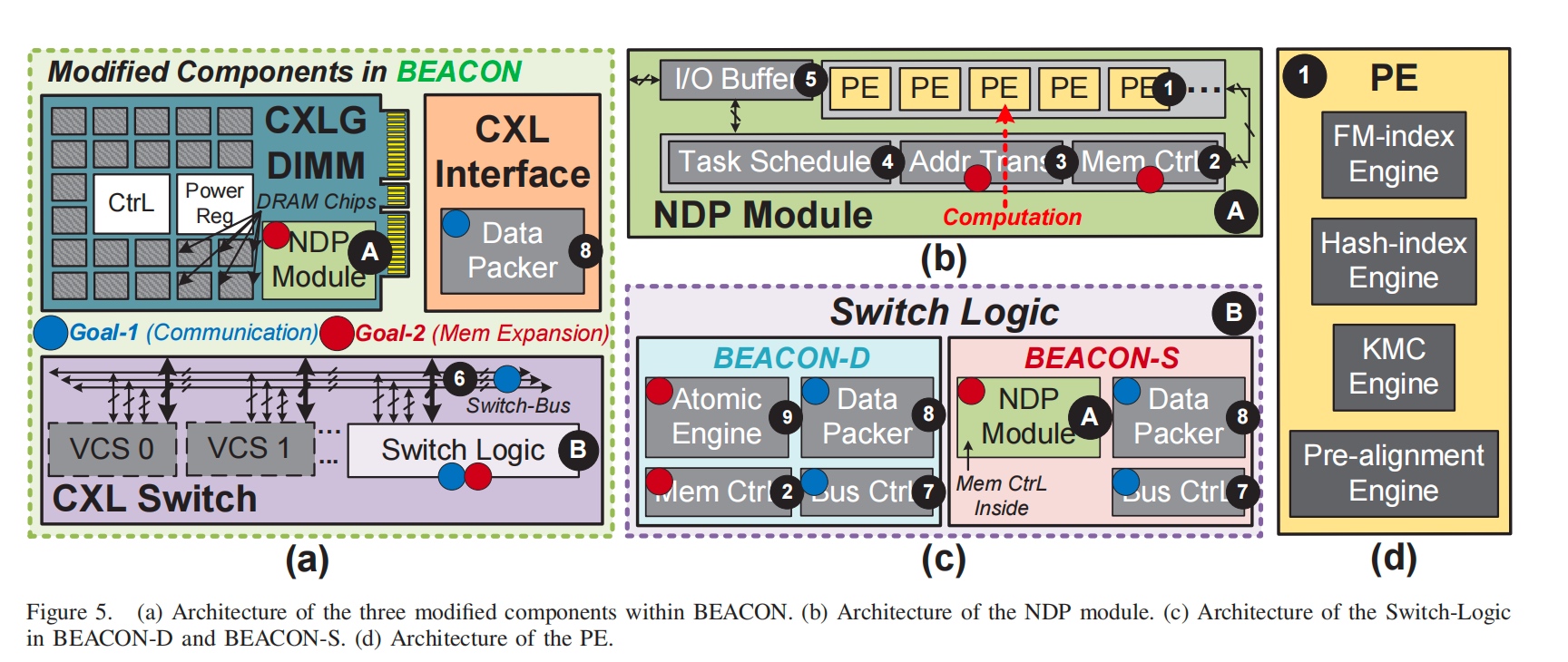
BECON-D是直接点对点的传输,而BEACON-S在CXL板子上利用多加了一个NDP Midule,用于对ACTG数据的reorder和align,处理完之后, 多记录了CXL Switch 的route,,到switch了以后还能最快的寻址。(这里包含了MC/Address Translator。
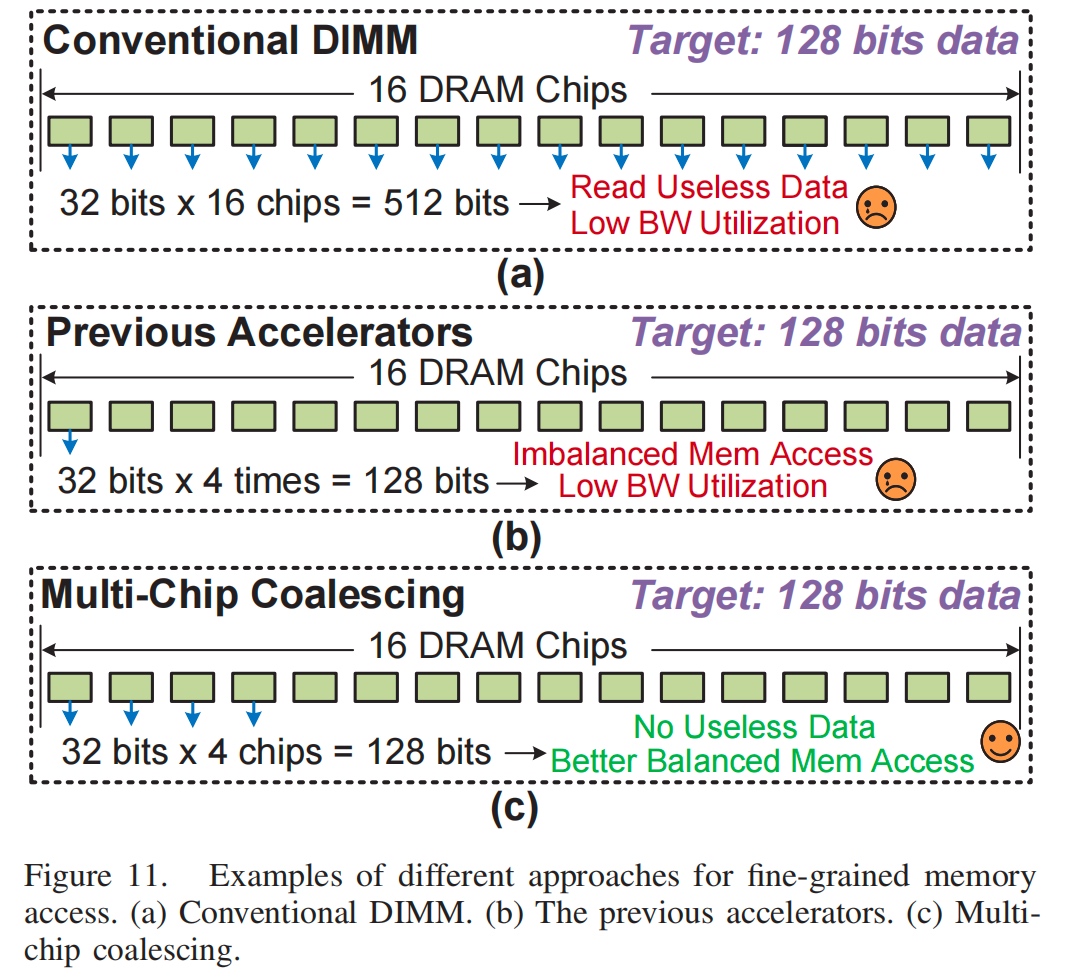
由于genome 分析需要 FM index based DNA seeding, 这里直接用类似NoC mux index的方式(multi-chip coalescing)来顺序存放数据,每个chip 存一部分,每个chip要取,就去对应的chip上取。这对balancing来说是很有用的设计。其次是k-mer counting,大概就是一个Bloomber filter 做counting,(我怎么记得之前mhm2是用dht k-mer。)总之这里也需要independently distribute 这个 BF.
Page Size Aware Cache Prefetching
这篇文章第一作者单位是Barcelona Supercomputing Center。想在page level 做到fine-grained prefetcher, which augments the MSHR to implement PPM.
(Jim Keller 说过现在的处理器可以prefetch 500条指令,但是哪些预测错了,panelty也挺高的,至少你失去了这500个数slot 的cost opportunity。下图是一个4k pages和large pages的access pattern,可以见到两者都需要更好的prefetcher that knows the semantic of page size(permission/size)。
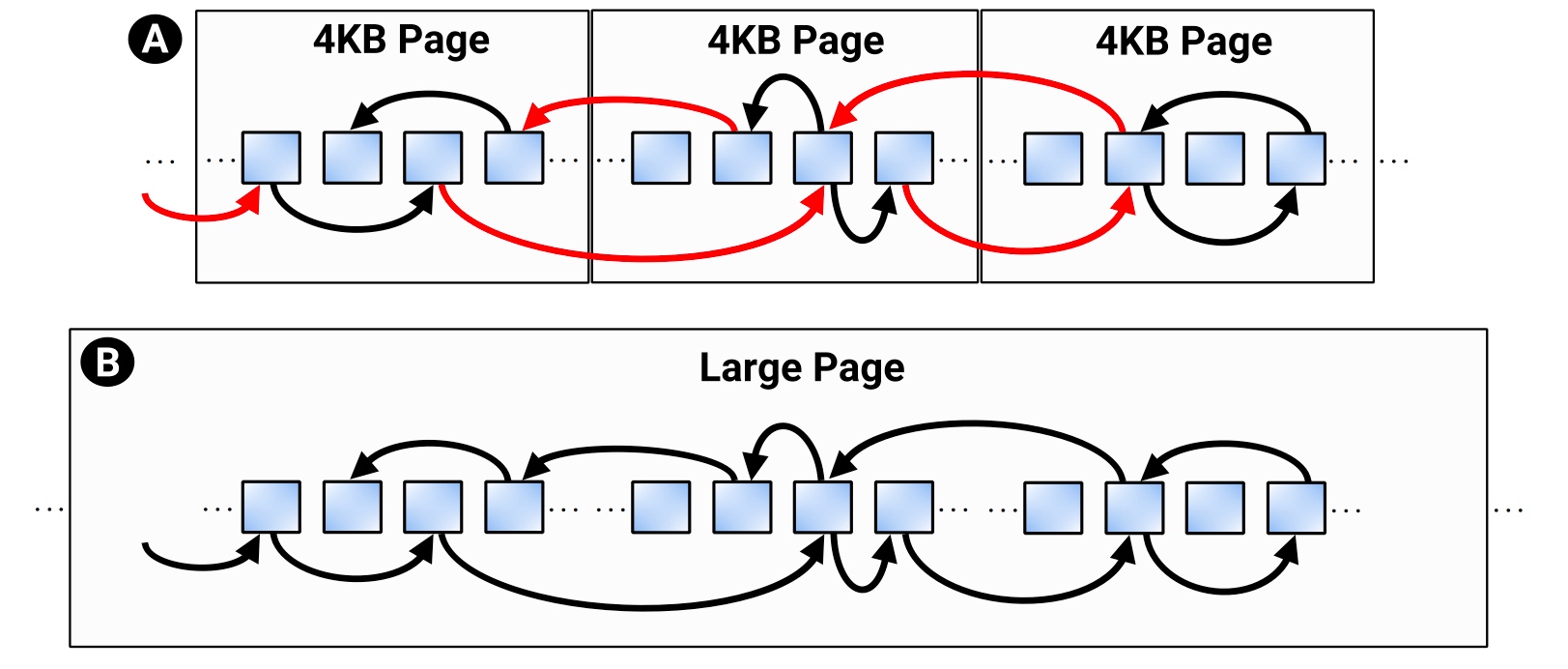
这种事spatial prefetcher,以前的4KB physical page boundary 是被non-contiguous physical memory 限制住的,large page的prefetch也有side channel的问题。他们的实现是一个TLB加一个address translator。translator和cache size传入MSHR,prefetcher 还是用以前的Signature Path Prefetcher(a prefetcher that uses
throttling confidence threshold, is a part of DMP(data memory-dependent prefetcher))。下面是整个流程图。
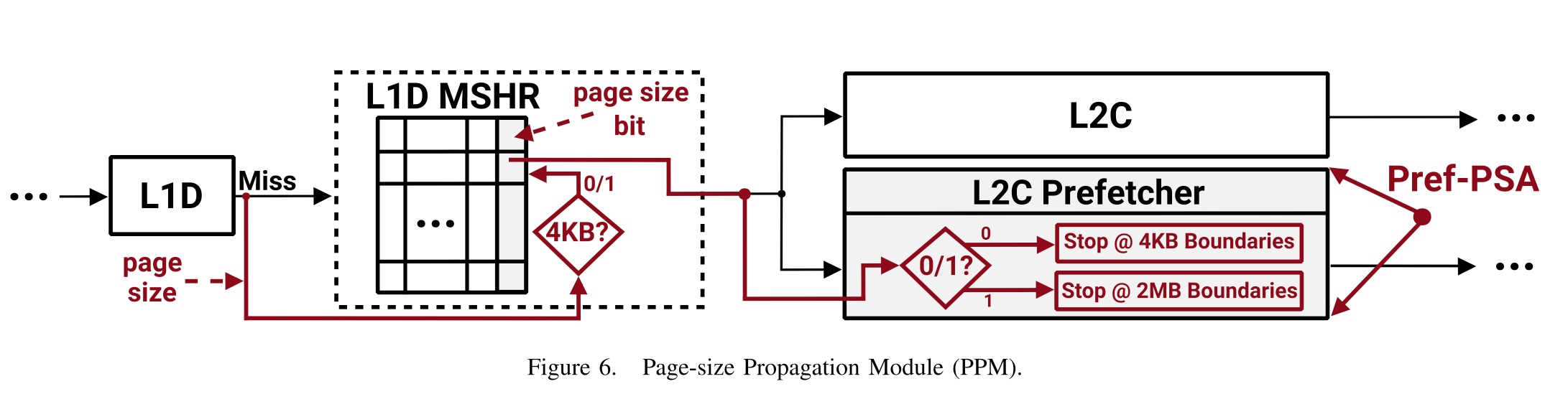
在L1D上的prefetcher有一个page boundary因为VIPT,index是小于page size的,有一个时机的问题,如果在L1D TLB里太久了过一会儿就miss了。
在L2C(have no idea they add a C for cache)/LLC上的prefetcher是直接物理地址,原因是PIPT。
Safe prefetching的意思就是通过拿到TLB的VA-PA mapping,但是逆过程比较烦。然后同时支持2MB hugepage也是可行的,因为硬件上要存的地址大小没有alignment的问题,只是需要多一个metadata bit记录大小,这个可能affect性能。claim是safe的是因为这个直接防御了DMP AoP M1 Max 攻击。
Ref
- https://staff.fnwi.uva.nl/a.d.pimentel/artemis/icpp19.pdf
- https://www.cse.iitb.ac.in/~biswa/ISPASS22.pdf
- https://github.com/FPSG-UIUC/augury
Merging Similar Patterns for Hardware Prefetching
这篇做的是pattern merging prefetching。中科院感觉这块一直在pipeline地出work(是想integrate进香山吗)。上一篇《俄罗斯套娃》是recursive lookup to prefetch,相当于利用到了历史信息。这篇用4个bit记录pattern(总共16个pattern1),做多个cacheline相同的patter,做同时用相同硬件取。
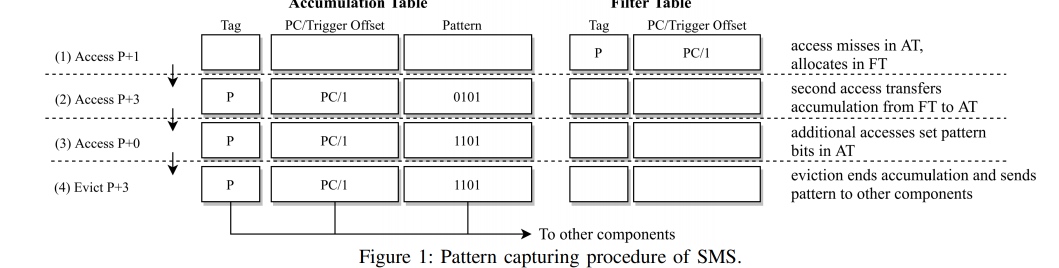
相当于prefetcher也有了ROB,可以tomosula。
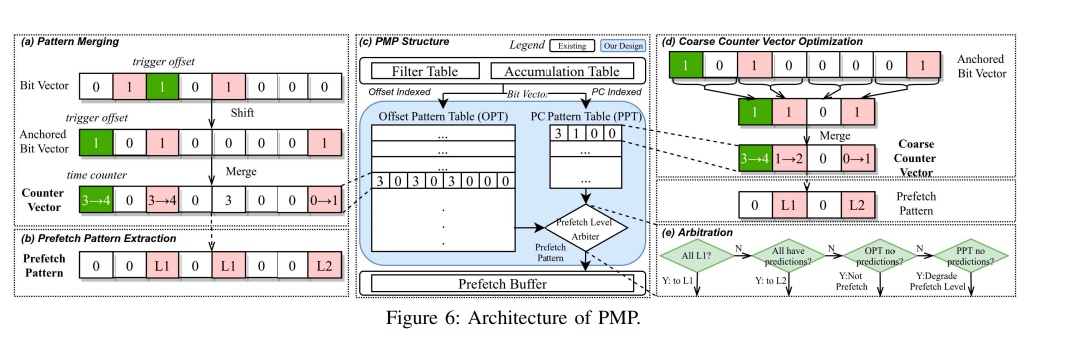
Ref
- https://dl.acm.org/doi/pdf/10.1145/3472456.3473510
- https://lca.ece.utexas.edu/pubs/ispass_jiajun.pdf
Treebeard: An Optimizing Compiler for Decision Tree Based ML Inference
OCOLOS: Online COde Layout OptimizationS
Tanvir 老板的,故事的开头是说L1I在过去几年内完全没有什么增长,原因是icache的时延没怎么增长,profiling还是用老的topdown的方法。Online给出PGO的最佳code摆放位置。现在ML(新出的库都有static code optimization)和数据库的code align 是irregular in terms of online fetching的,所以需要PGO开搞。(其实JVM在知道输入的情况下也有类似的code重排机制,所以可以说这东西把JIT code realignment 放到了静态做。本篇文章主要对标的是Meta 的BOLT,然后性能吊打。( 
)
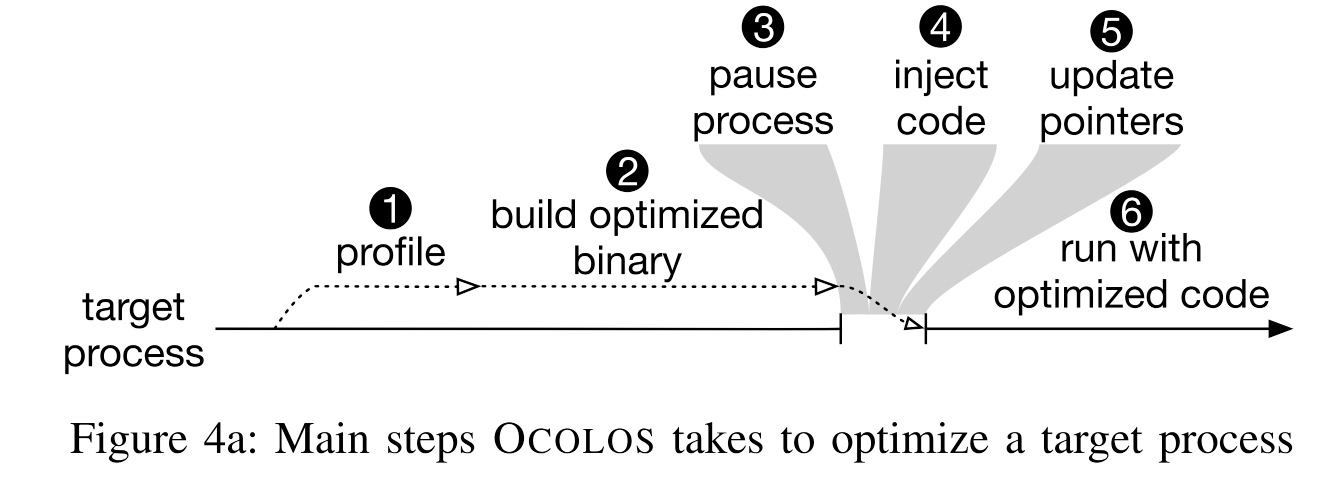

这篇的motivative example有这么几个,之前的PGO code alignment不是最优(possibly 局部最优) 而且不是determinist。经典的Pettis-Hansen(PH)算法为贪心实现不区分调用者,而C3算法是调用者和被调用者aware的。如果A call B 频繁,而B不call A, move the target of a function call closer to the call instruction itself, improving L1i and iTLB locality beyond what PH can provide.

还有code replacement。可能会引入fixed开销,但是可以避免重复访问。
OCOLOS 方案需要preserve addresses of the $C_0$ instruction,尤其是下面的vtable的情况。
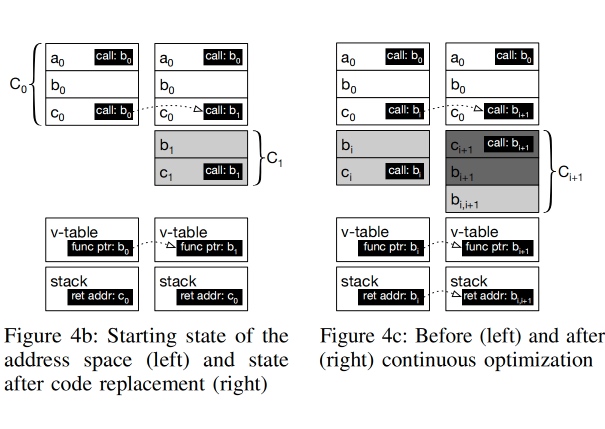
OCOLOS executes code from $C_0$ instead of $C_1$ occasionally to ensure correctness. However, the more frequently OCOLOS executes code from C0, the more it reduces the potential performance gains C1 can provide. Therefore, we seek to make $C_1$ the common case.
Continuous Optimization:$C_1$到$C_2$是连续优化的,利用之前的replacement code 算法但同时也需要GC dead code,这样寻址性能会更快,更容易被icache自动fetch到,对ra PC relative的指令,需要优化后update。对函数指针会points to$C_i$的invariant再point回$C_0$
jump table(多重跳转表) 暂时不支持,无法使用简单的invariant表示,反而会增加复杂度,于是gcc加上了-fno-jump-table
Ref
- https://arxiv.org/pdf/2101.04808.pdf
- https://zhuanlan.zhihu.com/p/550895670
- 被打败的谷歌AutoFDO/Propeller(google is unbreakable),添加支持了链接器每一个 section 放一个 basic block,通过在链接期间基于 profile 信息进行整个程序的 basic block 重排、函数划分、函数重排。 https://www.phoronix.com/news/BOLT-Optimizer-RFC-LLVM 现在被 [email protected] 这个人接手跑了几个和BOLT相关的测例 https://github.com/shenhanc78
CRONUS: Fault-Isolated, Secure and High-Performance Heterogeneous Computing for Trusted Execution Environments
这篇从头到尾都很legacy,H100+CCA应该已经有实现了,不过build from scratch值得借鉴, OPTEE+arm core,对CPU部分抽象,加了一个对GPU访问的的HAL enclave,也不是很SHIM,menclave还是挺微内核的感觉。中间传输的都是密文,从启动GPU, device tree开始喵,到MMI remapping/interrupts都需要包操作。感觉overhead如果没有它后面几个优化,overhead极大,
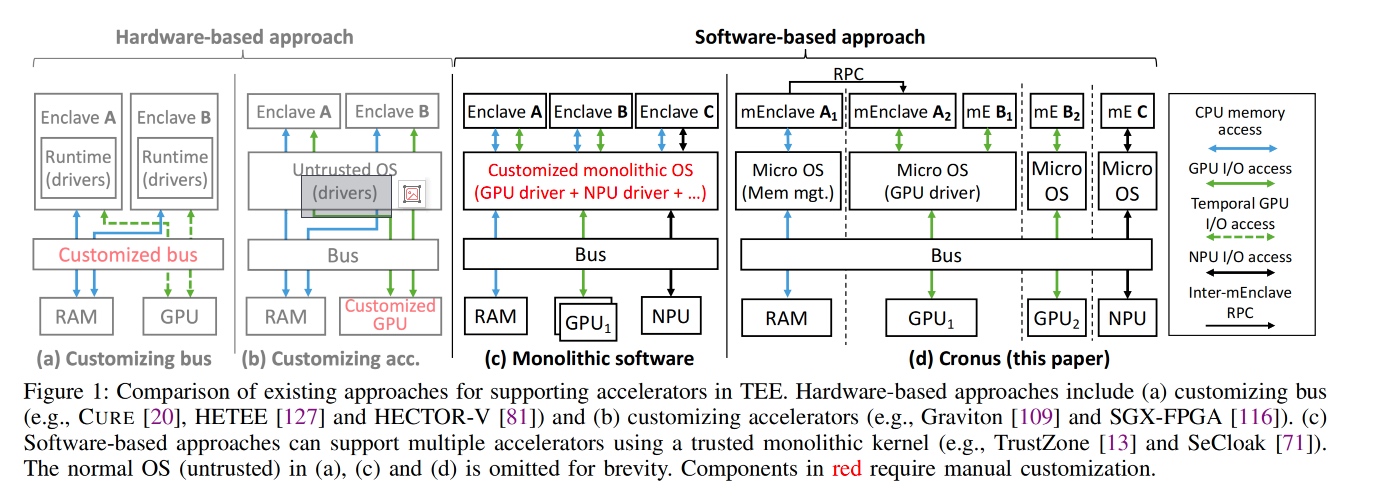
RPC有一个streaming RPC的优化,防止Message Que被exploit。(core内RIDL防御也可以吗
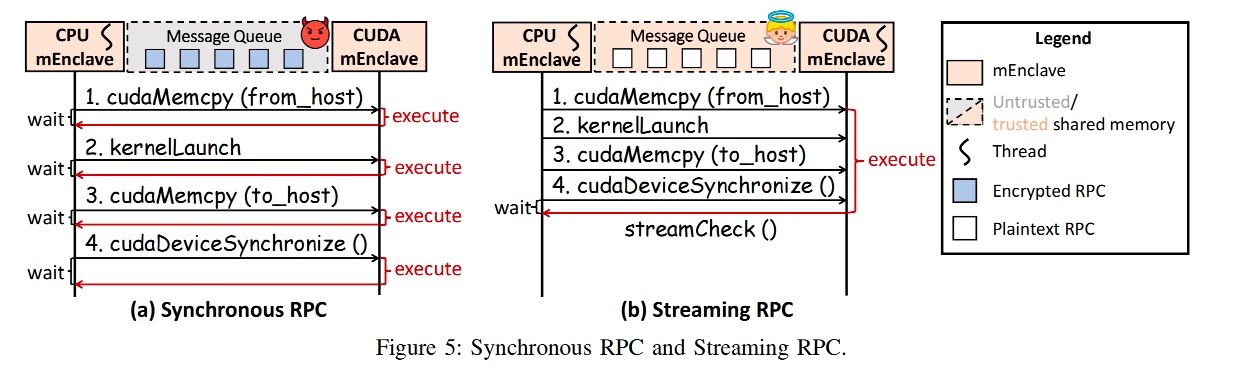
在fault tolerent 部分,对于shared memory of 2 menclaves。先看是什么类型, 1. untrusted OS proactively requests a restart of $P_a$'s mOS to the SPM. 2. panic and transfers the control to the SPM due to HW/SW failure. 3. SPM knows $P_a$ hangs.
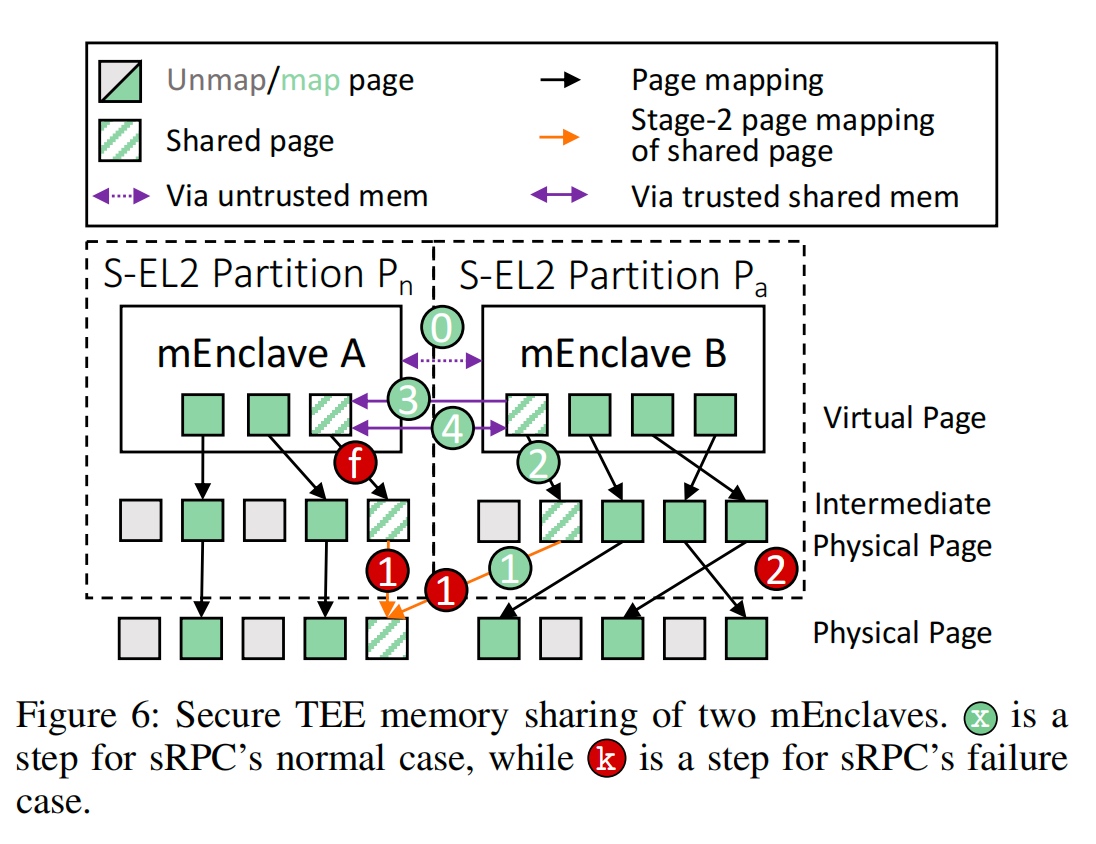

这边所说的TOCTOU window 挺有意思的,是fault以后,其他kernel thread 还没被notify到,需要先add一个hang的窗口。
最后hanlding trap to a different scenario(no trap like world change because all world stays below SEL2。
Ref
- https://blog.csdn.net/Rong_Toa/article/details/108997226
- 纯Driver based和eurosys那篇有点像 https://www.microsoft.com/en-us/research/blog/powering-the-next-generation-of-trustworthy-ai-in-a-confidential-cloud-using-nvidia-gpus/
GenPIP: In-Memory Acceleration of Genome Analysis by Tight Integration of Basecalling and Read Mapping
Onur Mutlu版本的genome analysis PIM。他们之前有一个genstore是在mqsim上写的。(感觉H100的DP指令集很适合做这个运算,但是这篇还是搞在CPU上了。(VRAM放不下


PIM做的主要是string machine,之前TCAM 谈过论文里说的CAM+NVM的。这篇的insight是PIM Chunk based pipelining。
Designing Virtual Memory System of MCM GPUs
GPM组的后续。 MCM GPU的background是说Monolithic GPU不能很好的适应当今的深度学习需求,于是想CPU一样加一个Interconnect连起多个GPU就很有必要
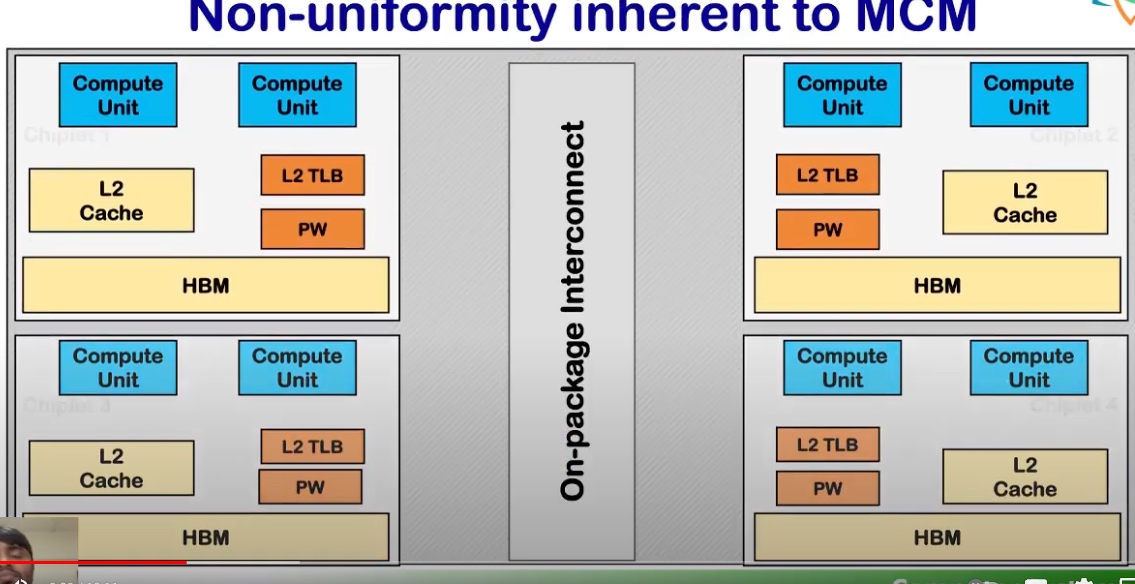
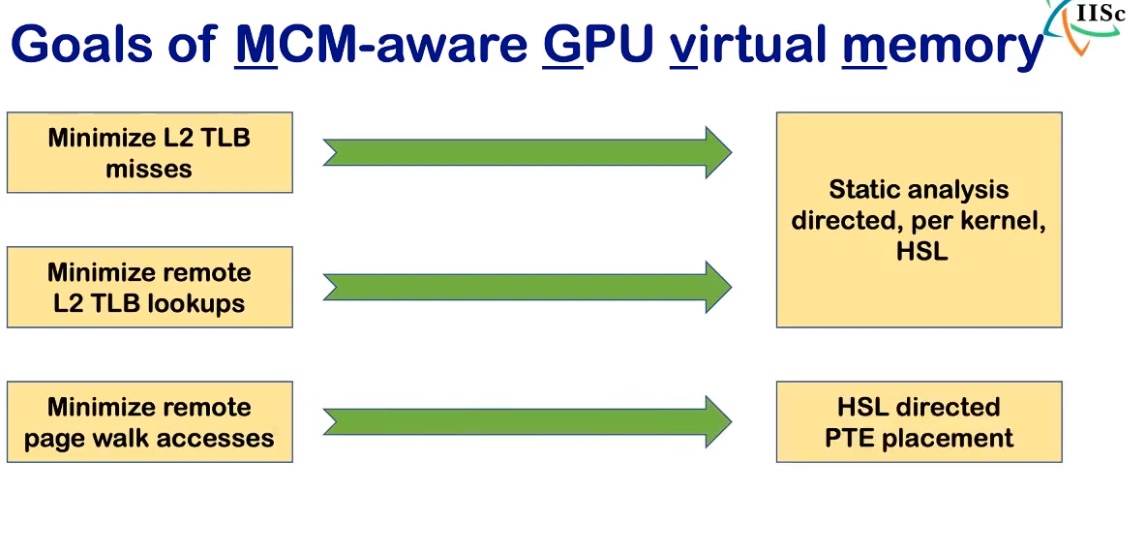
其实这也不是很新的设计,AMDCPU上有一套CCX、RDNA3的infinity cache其实解决的就是interconnect、还有Intel、苹果的M1 ULTRA完全就是interconnect连接起来的(当然其GPU TLB设计完全失误了。) 对于一个VM based的设计要解决下面三个问题。然后就是静态分析。

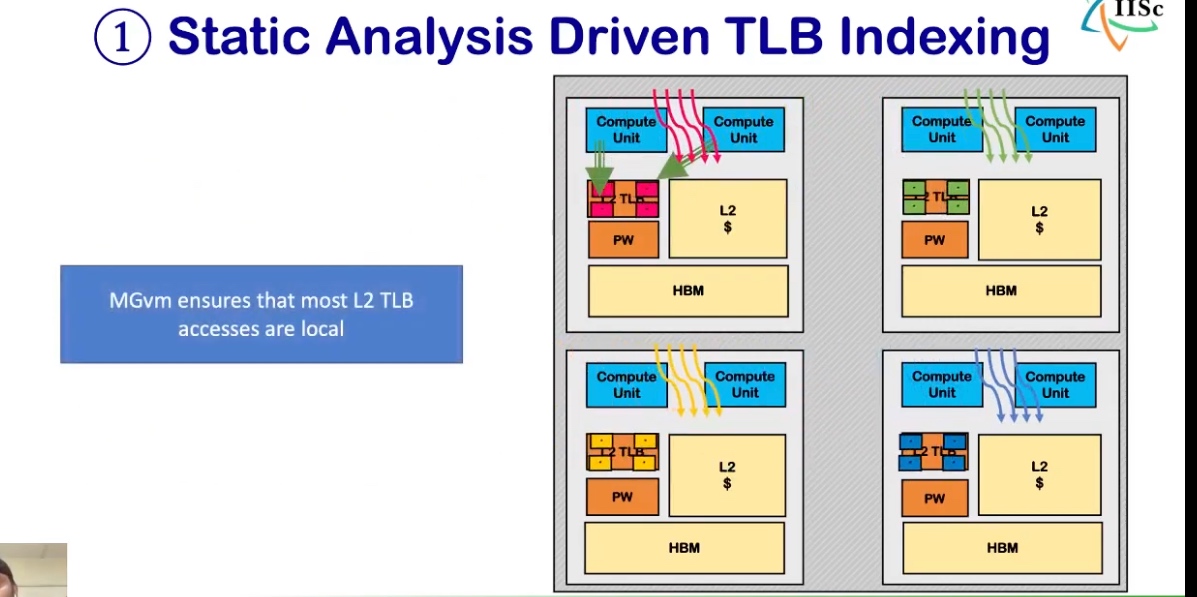
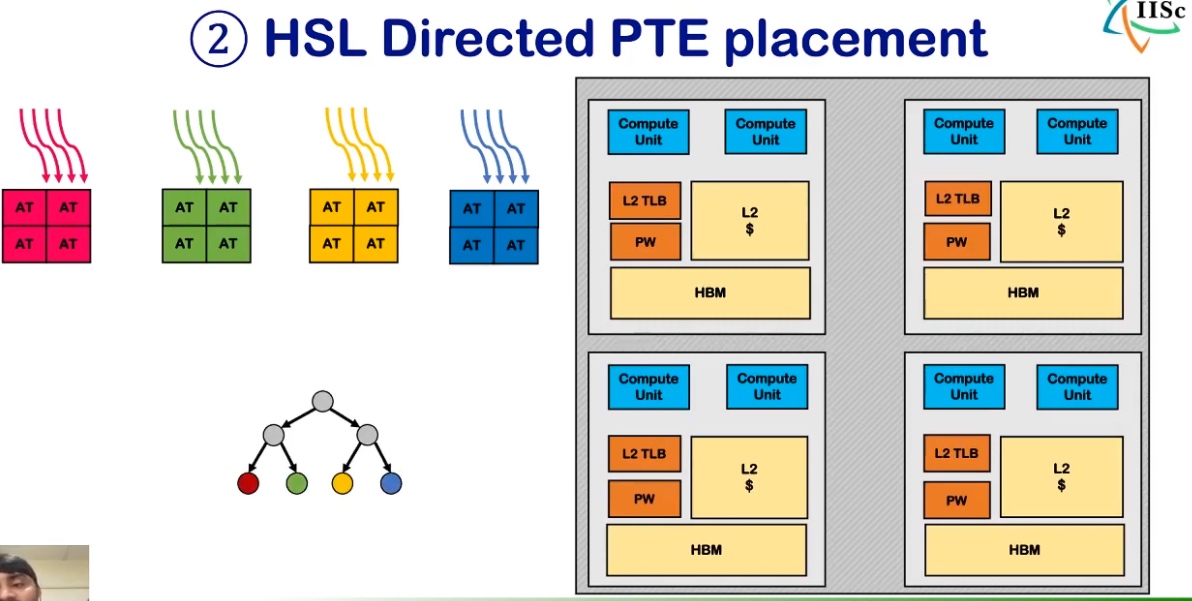
HMM解决不了这个问题,因为是in core 共享的,不需要加一个时延更高的agent(host),但是可以做一个带bias的IOMMU?
Ref
- https://www.youtube.com/watch?v=5CB7liZ531Y
- https://www.tomshardware.com/news/nvidia-exploring-various-multi-chip-gpu-designs
PageORAM: An Efficient DRAM Page Aware ORAM Strategy
Oblivious RAM是保护memory access addresses的。目的是优化使得DRAM page access的时延有个bias。
DaxVM: Stressing the Limits of Memory as a File Interface
Wisc Micheal Swift和NV做的,看题目像Rethinking File Mapping for Persistent Memory那篇的延伸,对比的是上次看过的ctFS,但感觉和CC学长的把B+tree的kv放在VM下面有些类似。我们知道,一个PMem based DAX fs,基本上都是mamp一大块内存,然后当一个大缓存用。但是DAX-mmap在改操作系统页表的时候还是有如ephemeral mappings,asynchronous unmapping, bypassing kernel-space dirty-page tracking等问题。
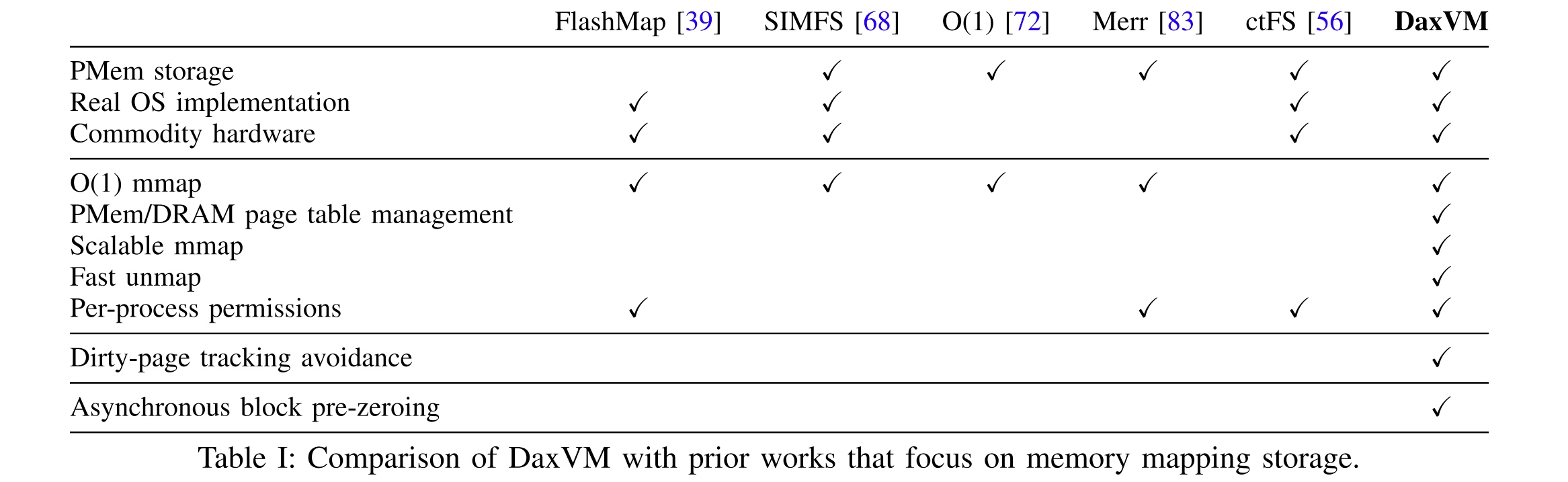
pre-populated file tables: 一个O(1) file-memory mapping(FILE DAX Virtual Memory)就可以实现上面吹的几个功能
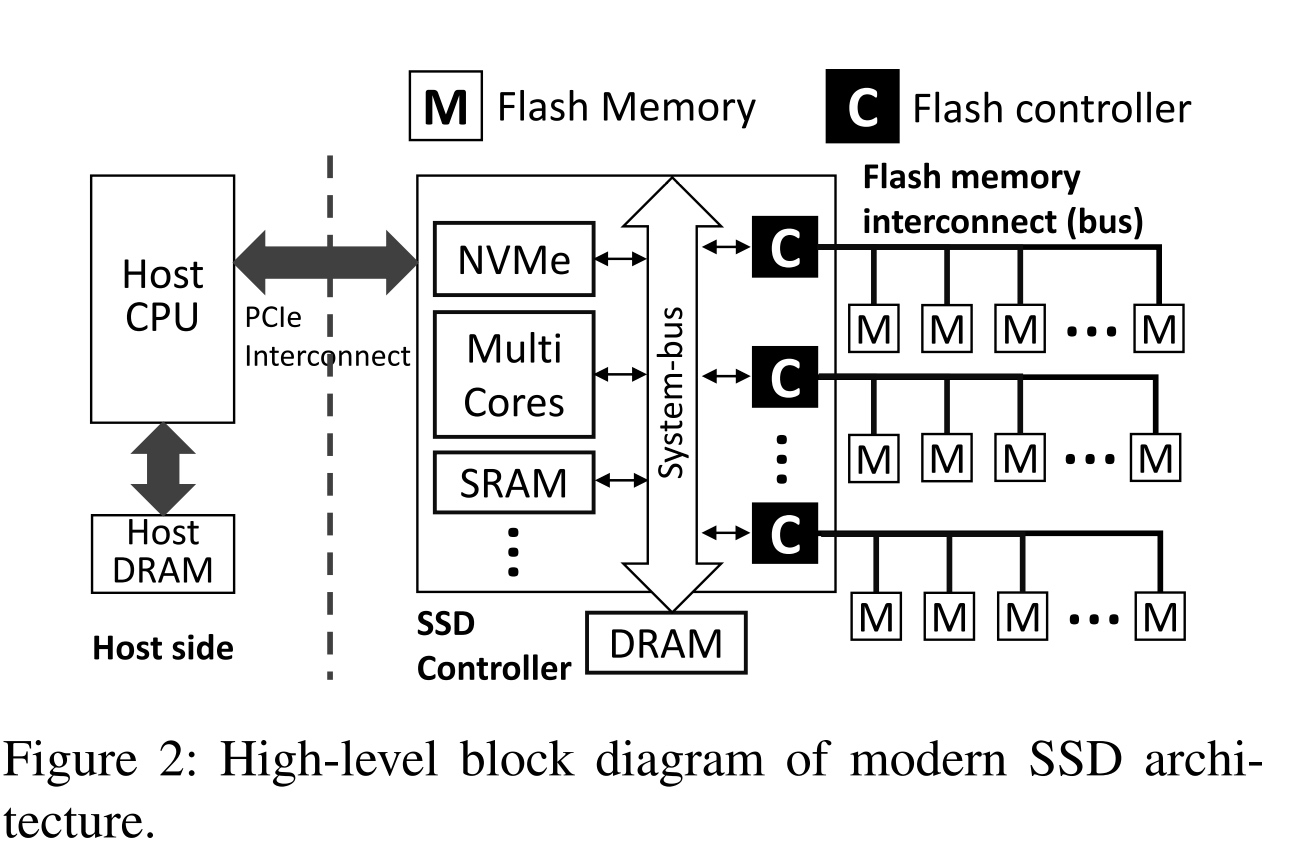
Networked SSD: The Flash Memory Interconnection Network for High-Bandwidth SSD
这篇的想法是memory的2D mapping 太慢,一个 packetized SSD+spatial GC可以优化性能
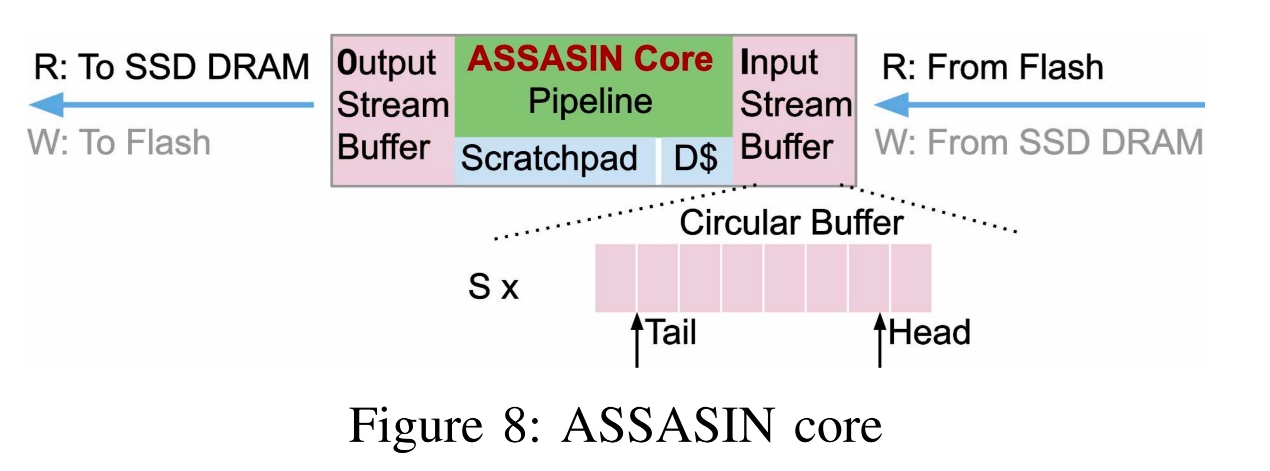
ASSASIN: Architecture Support for Stream Computing to Accelerate Computational Storage
这篇是Stream 方向的Computational Storage,目的是通过iMC+Flash controller+driver结合的方式hot data aquiry从而减少memory wall带来的性能陡降。
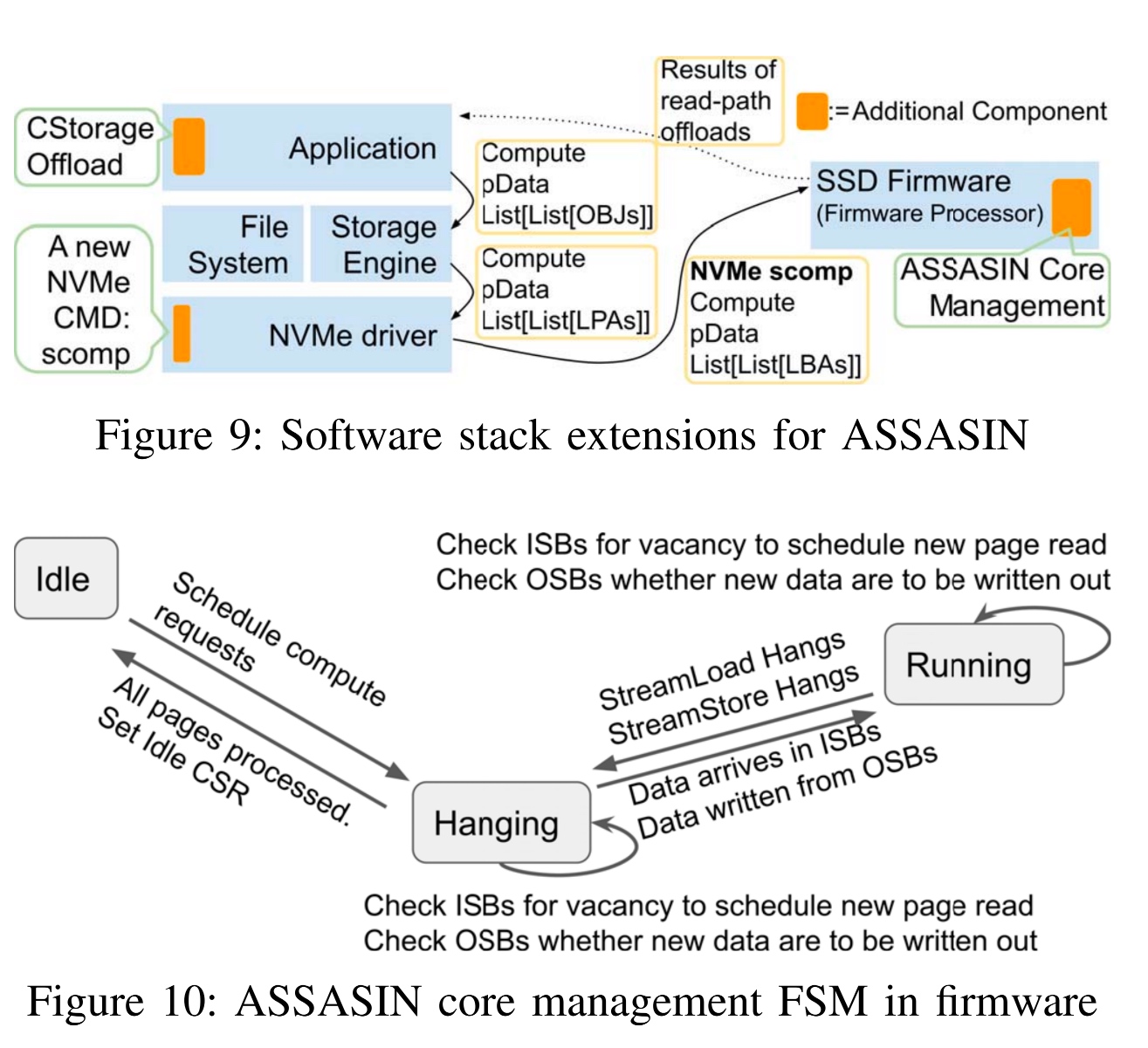
这个像是个TCP load balancer的自动机。
ALTOCUMULUS: Scalable Scheduling for Nanosecond-Scale Remote Procedure Calls
对比了现有的几个网络包怎么传的model,就kernel driven FCFS,work stealing和NIC-driven
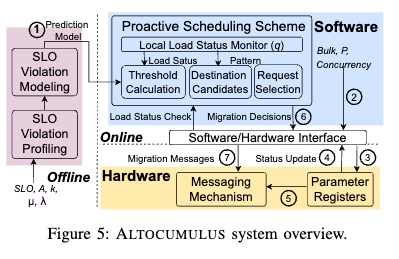
有很多很多延时优化的细节。
OverGen: Improving FPGA Usability through Domain-specific Overlay Generation
这篇是LSH和WJ老板的paper,像是RVSC21的LSH的那个followup
pLUTo: Enabling Massively Parallel Computation in DRAM via Lookup Tables
又是一个增加TLB访问DRAM的故事。
伟大的香山

Translation-optimized Memory Compression for Capacity
这篇和Compress object not cacheline 那篇差不多。object 表这边变成Compression Translation Entries。
Horus: Persistent Security for Extended Persistence-Domain Memory Systems
有点意思地提到了the persistence domain(eADR) is extended to include a battery-backed Write Pending Queue (WPQ) inside the processor chip. 想法是Enclave merkle tree read/write的metadata存下来,能安全地恢复。所谓persistency security其实就是persistency+failure recovery。但是实验在Gem5上做的,(真机想做模拟真难。