

引入
首先,我们为什么需要一个PCIe attached memory or cache协议,重点是CPU上memory channel的局限性,你无法多加过多的并行的Memory Bus。虽然这对memory的随机读写有好处,现在的channel个数大概满足了CPU-memory Ratio,开多少线程跑load&store都能满足CPU的需求。
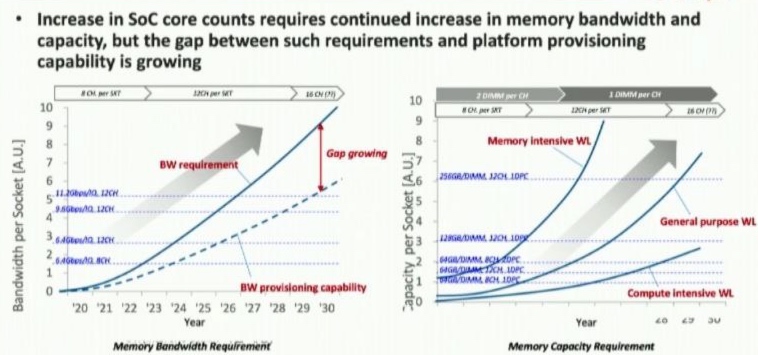
过多的线程会在核内空转也不会issue超过CPU频率和算力的内存指令。大家可以想象一个roofline model x轴为什么是arithmatic density的原因。同时淘汰浪费内存带宽的3D Xpoint也成了必然。那么串行的PCIe协议访问memory就非常有意义了,Meta的workload告诉我们80%的互联网应用是capacity bound,意思是我有一个很大的data warehouse,需要low latency访问的,也即是用户即将要显示在终端设备上的其实很少。只需要保证在短时间内load到private DRAM,就满足了。
例子
让我们从两个实际例子开始。
-
如果今天有人要创建一个基于PCIe的内存扩展设备,并希望该设备能够暴露相干字节寻址的内存,那么实际上只有两个可行的选择。一个人可以通过基础地址寄存器(BAR)暴露这个内存映射的输入/输出(MMIO)。如果没有Hack,唯一合理的方法是需要有CPU支持,将MMIO映射为未缓存(UC),这对性能有明显的影响。关于对GPU的连贯性内存访问的更多细节,可以看看Nvidia 的Hack。对设备内存的访问不受协议的限制,而我们还没有设法完成这个目标。事实上,NVMe 1.4规范引入了持久性内存区域(PMR,区别于C++20的pmr),它可以做到这一点,但仍然是有限的。
-
如果创建一个基于PCIe的设备,其主要工作是进行网络地址转换(NAT)(或其他一些IP数据包修改),这将由CPU完成,为此需要关键的内存带宽。这是因为CPU将不得不从设备中读取数据,对其进行修改,并将其写回,而通过PCIe的唯一方法就是通过主内存来完成。
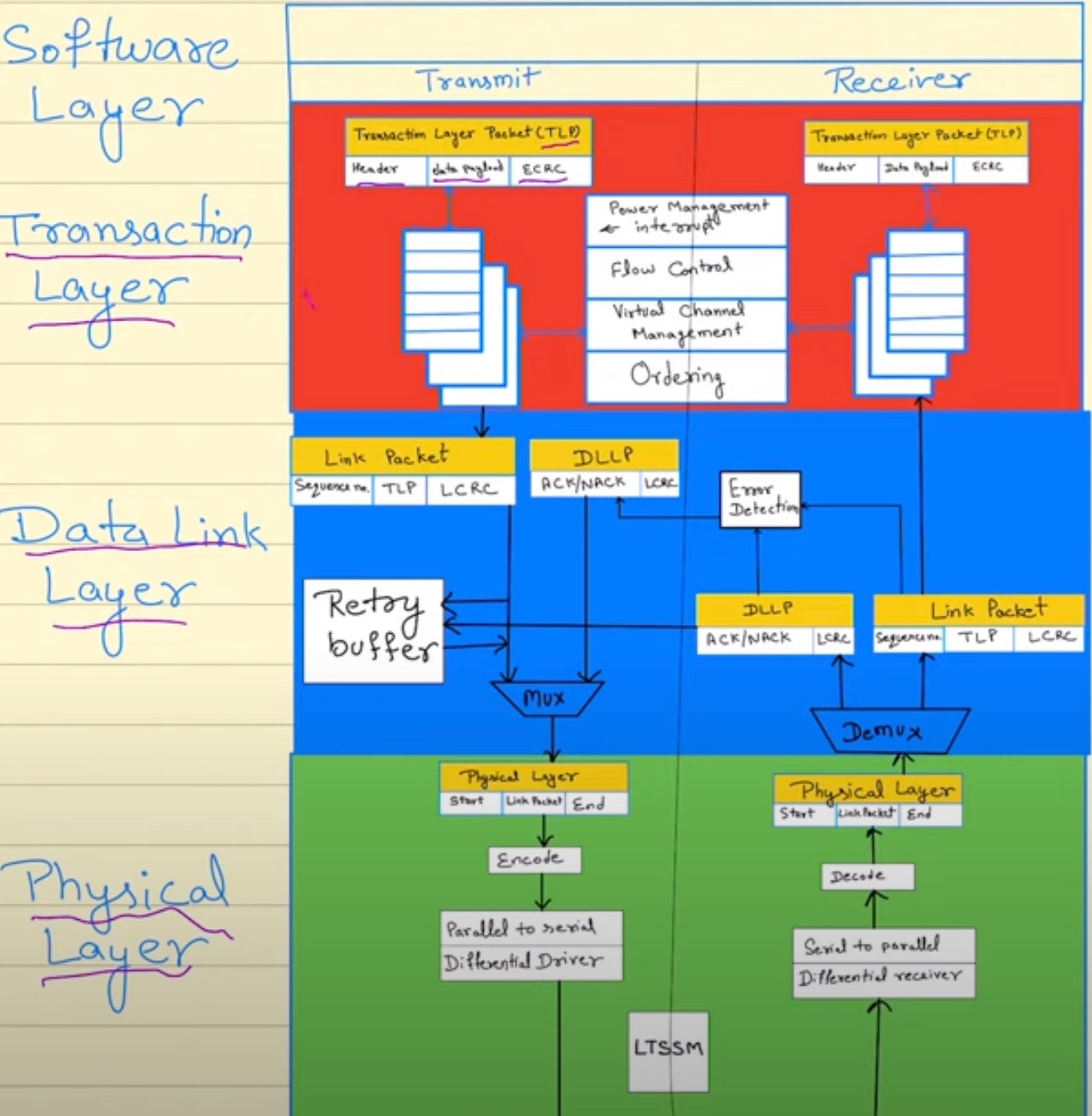
传输格式
通过串行的传输协议我们会获得Non-deterministic memory latency,除了极端情况下放在核电厂旁边不停丢包以外,更会受到CXL Switch over subscription的影响.
使用DRAM介质直连CPU的内存和NVDIMM不到100ns,通过PCIe串行连接的缓存一致性协议CXL(XMM、NV-XMM模组和AIC)、CCIX可以达到350ns延时;OpenCAPI的DDIMM也只有40ns;而Gen-Z这样经过外部Switch/网络连接的在800ns水平。
PCIe 传输格式
包头所对应的不同层传输格式
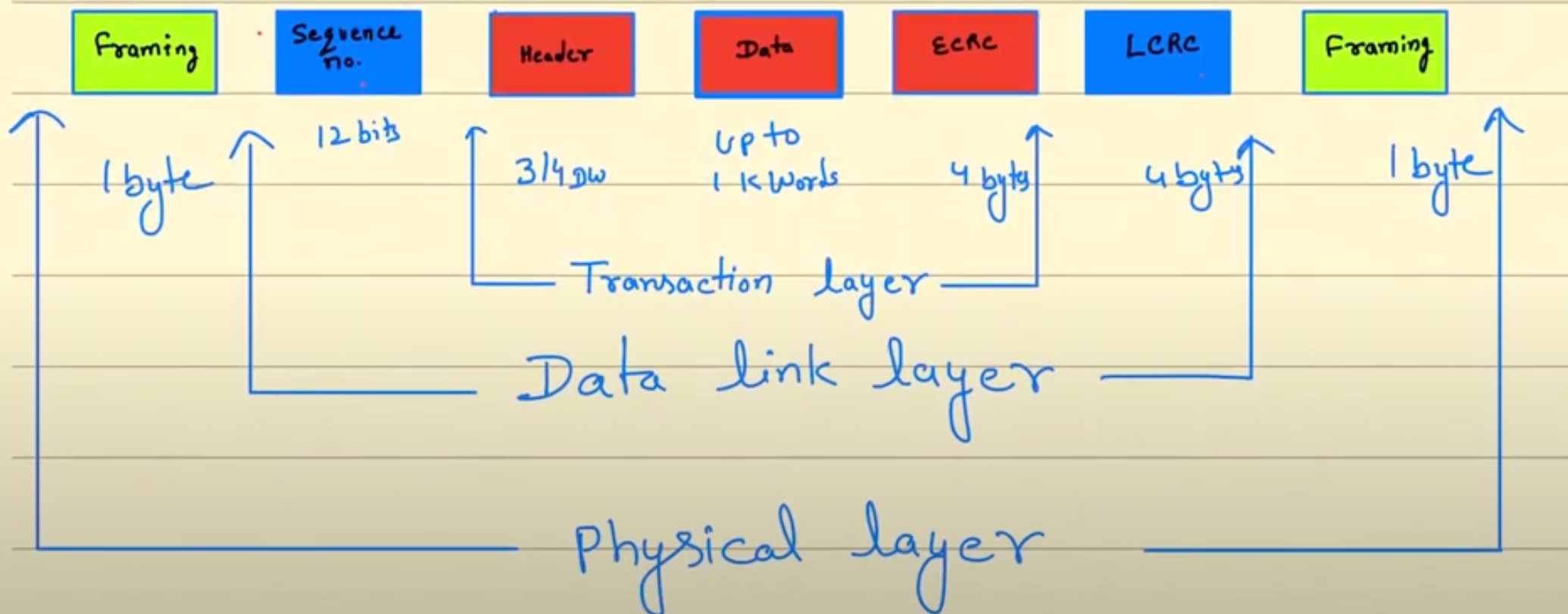
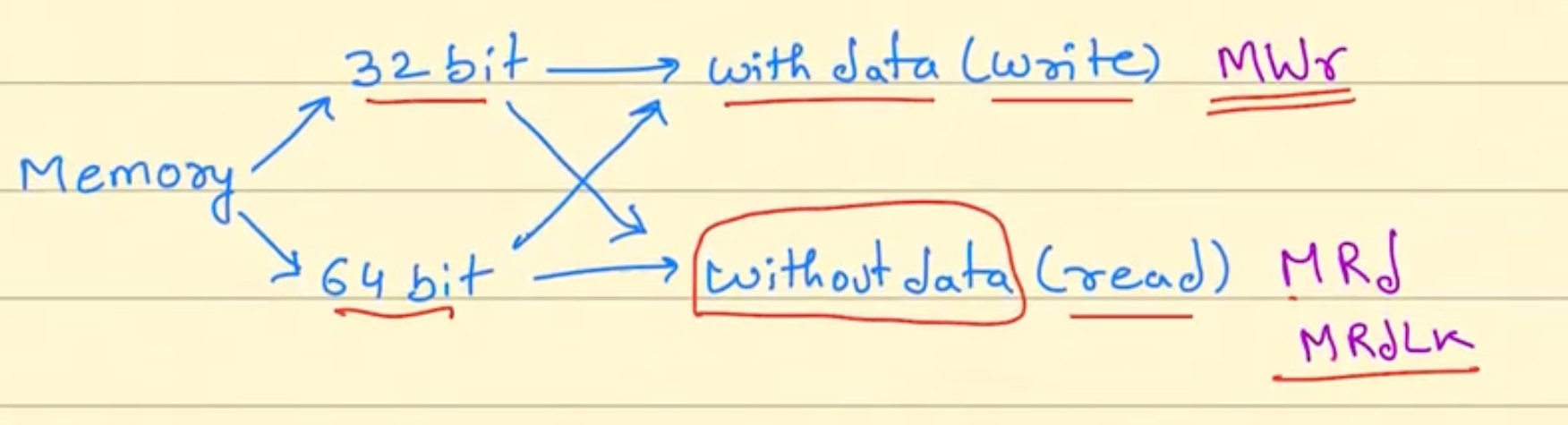
Memory configuration space有32bit BAR限制.需要一开始就指定是32/64来获得3DW还是4DW
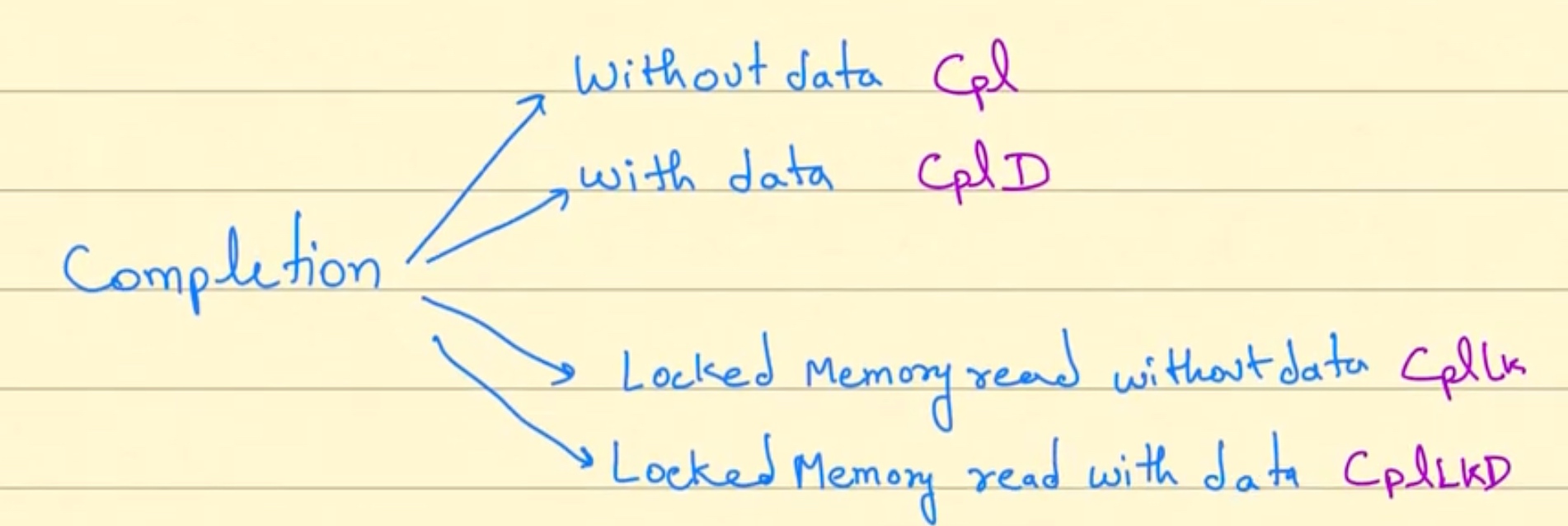
Completion 返回的 Ack 是分别对应之前的 Memory 请求。

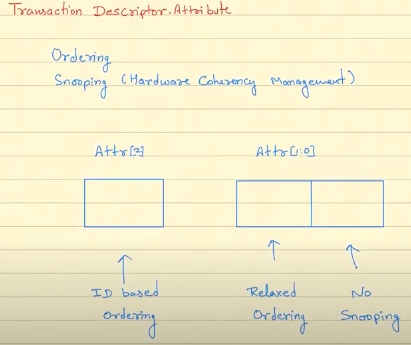
最后值得注意的是Transaction Descriptor Attribute 会指定IO的Ordering和CPU的Ordering/Snooping
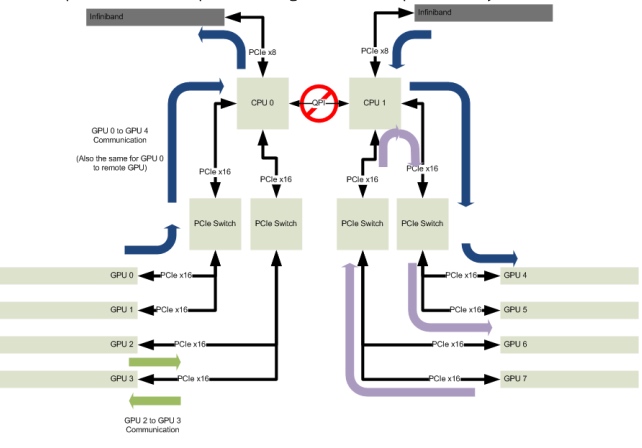
End Point通常是我们最感兴趣的,因为那是我们放置高性能设备的地方。它是样本框图中的GPU,而在实时情况下,它可以是一个高速以太网卡或数据收集/处理卡,或一个infiniband卡与大型数据中心的一些存储设备communication。下面是一个框图,放大了这些组件的互连。
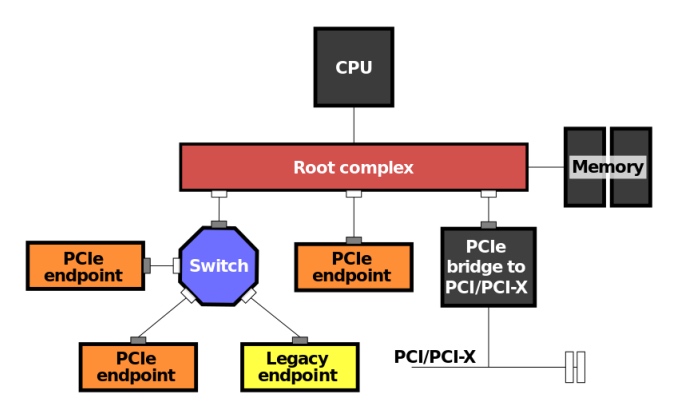
基于这个拓扑结构,让我们来谈谈一个典型的场景,其中远程直接内存访问(RDMA)被用来允许终端PCIE设备在数据到达时直接写入预先分配的系统内存,这最大限度地卸载了CPU的任何参与。因此,设备将发起一个带有数据的写入请求,并将其与希望的Root ComplexRoot一起发送,其将数据输入系统内存.
CXL 增加了啥
- ATS/MSI-x
- transportation metadata
- flip (faster in 3.0)
Problems
2.0 .mem也需要在背后维护一套directory based的coherency protocol,如何实现是个问题。3.0有很多的内存序问题,MESI是否是一个过于慢的设计?总线怎么设计?
Reference
- https://par.nsf.gov/servlets/purl/10078086
- https://www.youtube.com/watch?v=Uff2yvtzONc
- https://bwidawsk.net/blog/2022/6/compute-express-link-intro/#cxl.mem
- https://www.computeexpresslink.org/download-the-specification
- https://www.youtube.com/watch?v=fpAFvLhTpqw
- https://www.youtube.com/watch?v=caiREMKP0-E&t=7s