

文章目录[隐藏]
The current RPC layer between nodes can be scaled by utilizing NUMA variants like NEBULA [1] or soNUMA, which provides on-chip buffer locality awareness of the data movement. A lot of RDMA RPC Accelerator/ SmartNIC implements these kinds of locality information when sending on LLC or on RDMA Shared Receive Queue(to enable the inter-endpoint buffer sharing).
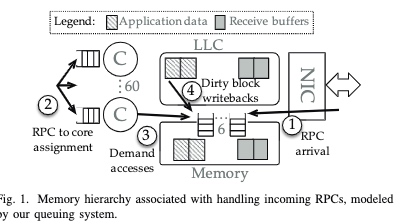
For tail latency that newly arriving RPCs will inevitably violate the SLO and are eagerly NACKed, informing the client early about increased load conditions on the server, NEBULA will reject or retry(fail-fast approach) the requests predicted. The NIC to core policy is implemented naturally using DDIO+fast packet reassembly, but this dispatch is not cached into L1 directly.
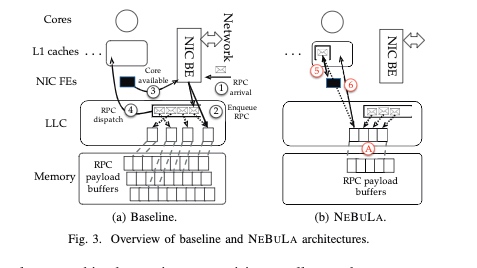
Dagger implemented FPGA reconfigurable RPC stack-integrated microservices. Their eventual goal is to enable NUMA(future support CXL) over FPGA RPC. Their initiative is still if the microservice like NGINX/MongoDB is not latency bound and memory bound, just disaggregate using their NIC to the same memory space. The RPC is the prevailing IDL gRPC. The CPU/NIC communication is very similar to the approach in the HFT industry DDIO+cache hash function+avx stream load cl, WQE-by-MMIO.
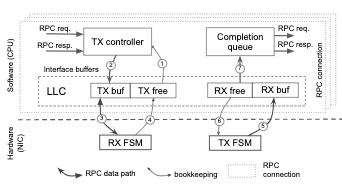
Their load balancer+ flow scheduler on FPGA is very similar to a CXL.cache device bias CHA. That CHA normally distributes Req on-chip or cross Socket through UPI.
When CXL FPGA NIC's in, I think it can cache cl onto L1 and use hw to replace the cc. I still think there's more OS-level sync that can leverage the cc of CXL.cache.