

文章目录[隐藏]
- Coding and Cloud Storage
- Key-Value Stores
- AI and Storage
- File Systems
- CJFS: Concurrent Journaling for Better Scalability
- Unsafe at Any Copy: Name Collisions from Mixing Case Sensitivities
- ConfD: Analyzing Configuration Dependencies of File Systems for Fun and Profit
- HadaFS: A File System Bridging the Local and Shared Burst Buffer for Exascale Supercomputers
- Fisc: A Large-scale Cloud-native-oriented File System
- Persistent Memory Systems
- Remote Memory
- IO Stacks
- SSDs and Smartphones
今年Fast在家门口开,那当人就请个假去玩玩咯.paper现在已经可以access了.两个Best paper都是中国的,一个是zuopengfei的ROLEX,一个是Fail-Slow的时序预测模型。
Coding and Cloud Storage
Practical Design Considerations for Wide Locally Recoverable Codes (LRCs)
- MR-LRC,every group has a local redundancy and global redundancy.
- Use Cauchy LRC to predict the distance
- 96-105 code per stripe >=6 time failure reliability test/Time to recover/ Mean-time-to-data-loss.
VAST Data's approach? LDC: workloads matters.
ParaRC: Embracing Sub-Packetization for Repair Parallelization in MSR-Coded Storage
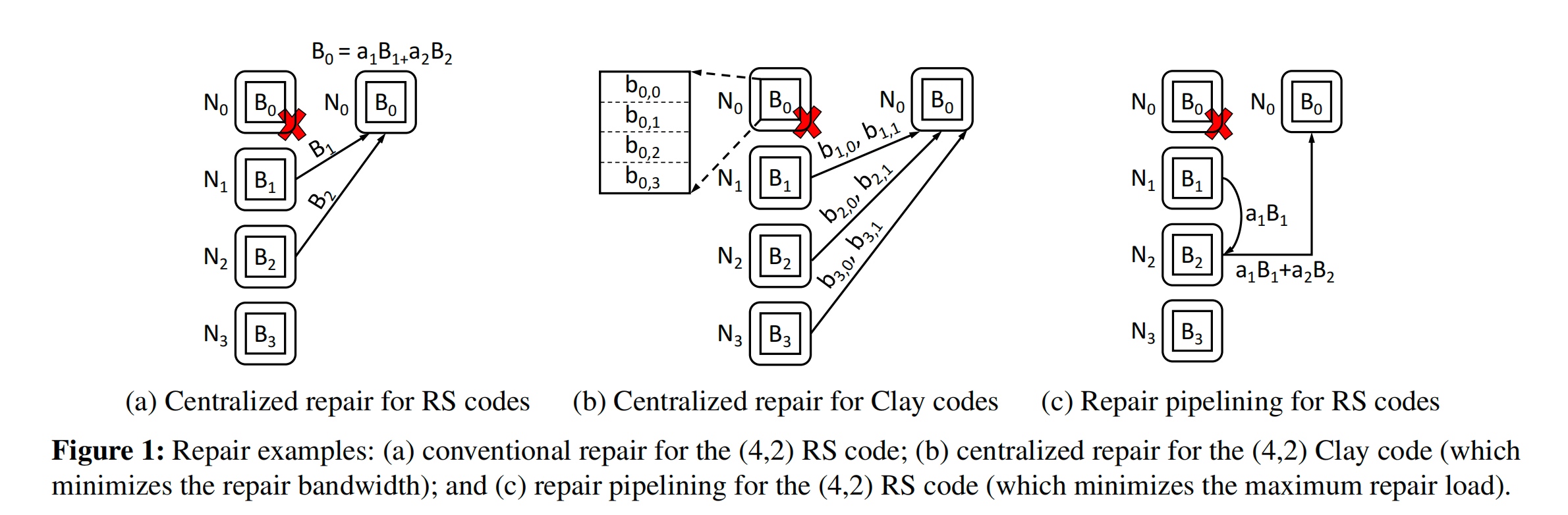
Repair penalty of RS Code
- Reduce bandwidth: amount of traffic transferred in the network
- Maximum repair load
For SoTA (4,2)Clay code, the blocks size is 256MB while bandwidth and MRL are both 384MB.
Repair can be pipelining while the block can be chunk into blocks, (bw ,MRL)=>(512,256), drawback is additive associative. But we can subpackerize the block.
pECDAG to parallel GC for Clay codes.
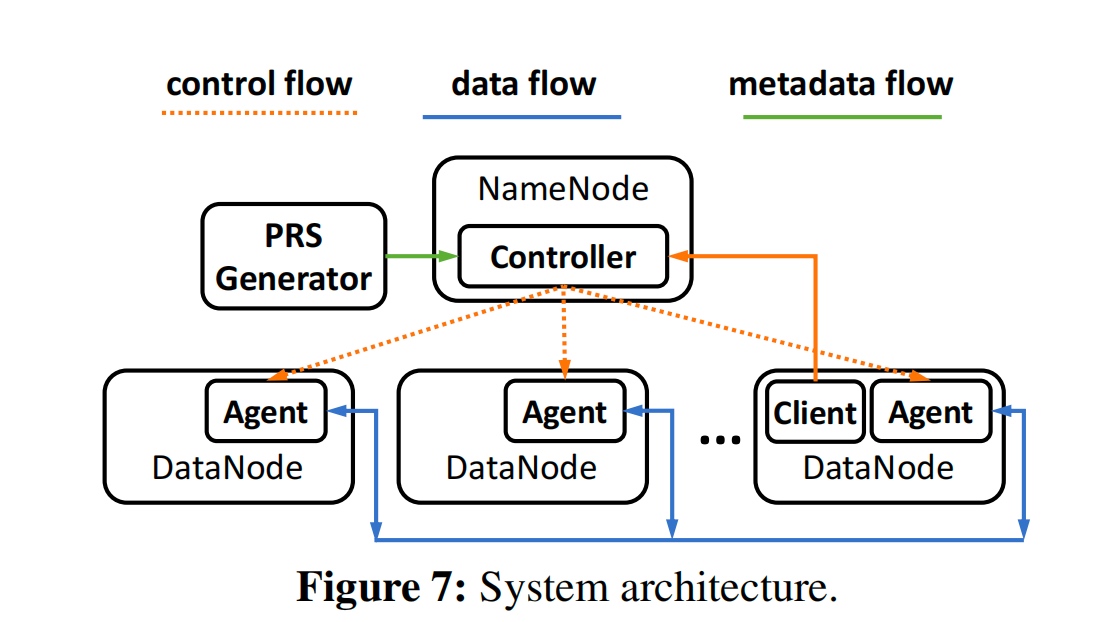
InftyDedup: Scalable and Cost-Effective Cloud Tiering with Deduplication
Cloud Tiering and backup data requires Deduplication in the cloud hypervisor level. They get teh fingerprint and semantic from the cloud tier and send the request to the local tier.
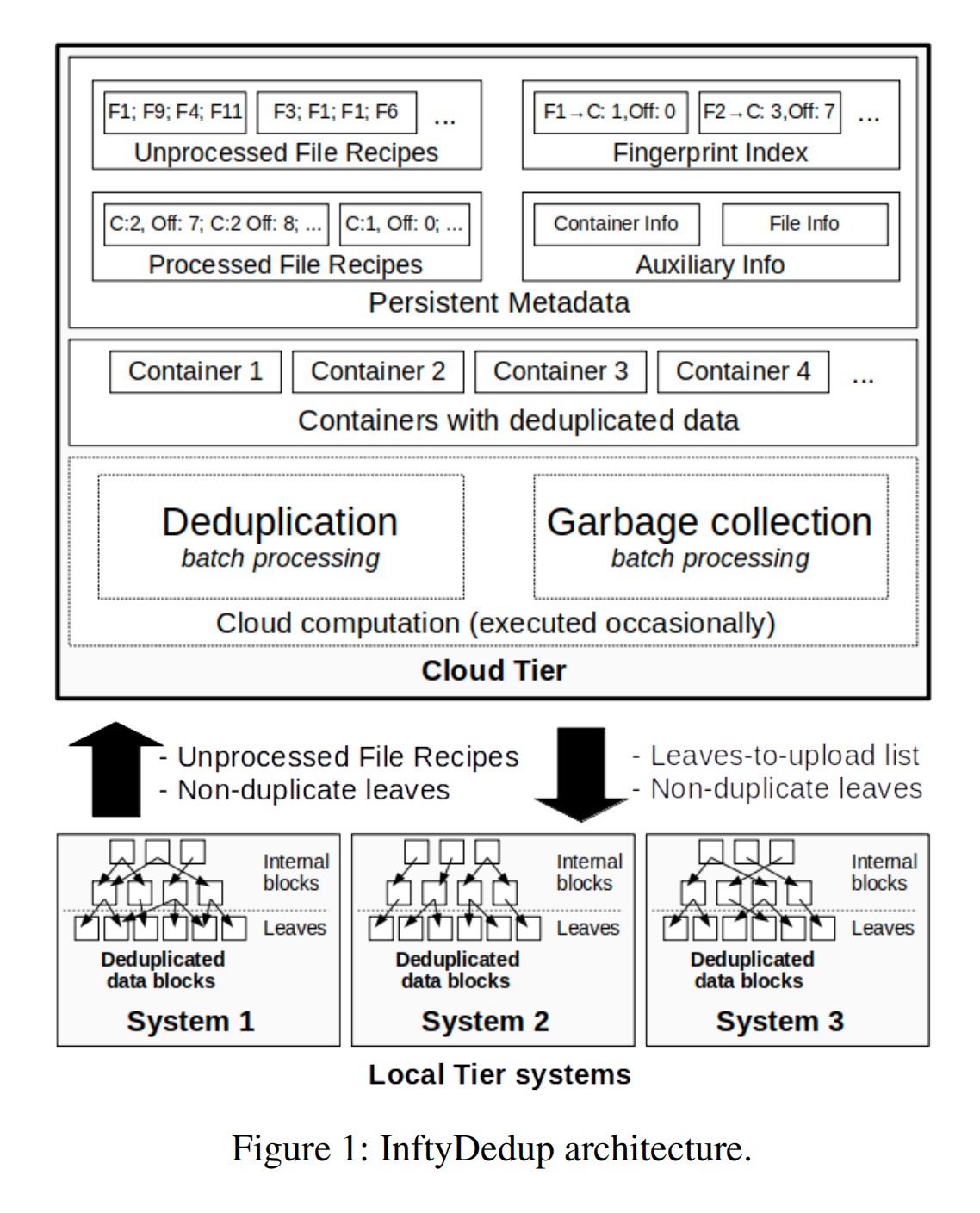
The GC algortihm is basically BatchDedup.
fingerprint Indexing in SSD.
Perseus: A Fail-Slow Detection Framework for Cloud Storage Systems
用sliding window 做peer evaluation。
用时序模型预测Fail-Slow的出现时间 Latency vs Throuput+Linear regression。
Key-Value Stores
ADOC: Automatically Harmonizing Dataflow Between Components in Log-Structured Key-Value Stores for Improved Performance
用历史数据学不同SSD的RocksDB的L0-L1 compaction,data overflow.
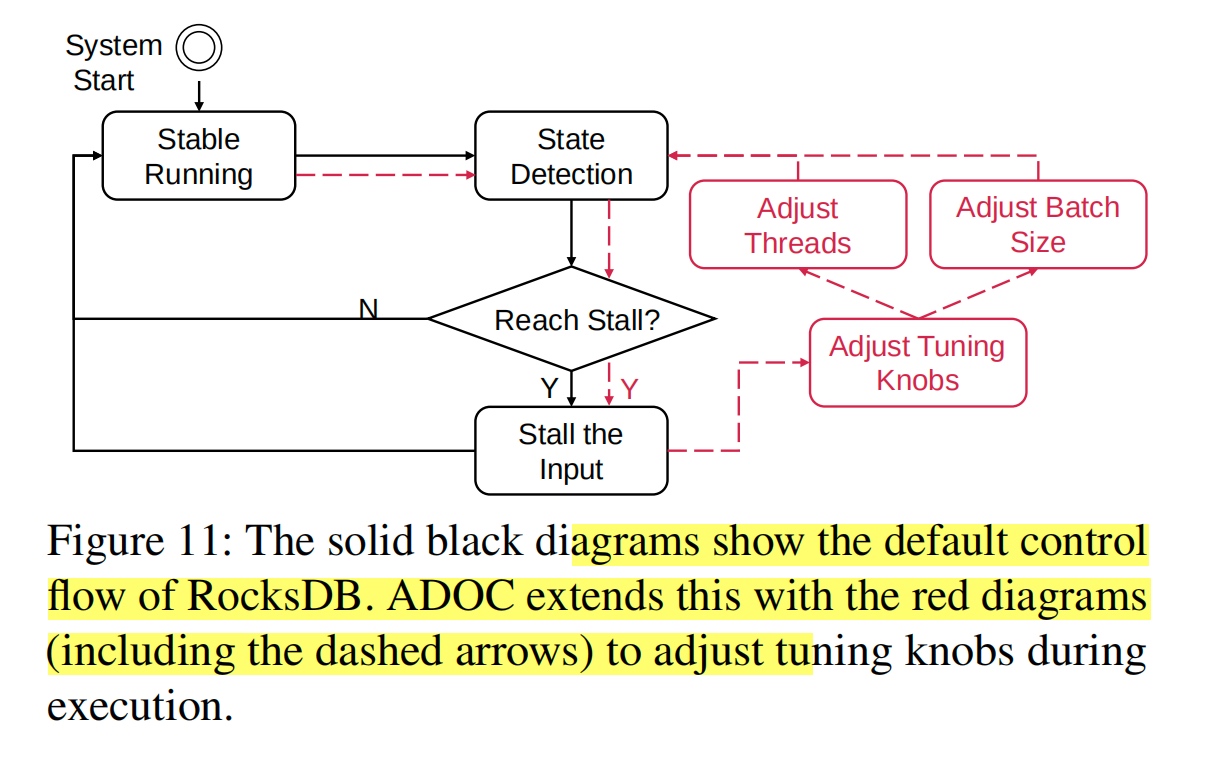
感觉做的没Kill Two Birds with One Stone: Auto-tuningRocksDB for High Bandwidth and Low Latency好。
RocksDB会自己increase memtable?
Does RDO control compaction? All layer compaction
RDO MMO encoder Transformer?Future work。
FUSEE: A Fully Memory-Disaggregated Key-Value Store
这篇和Ceph的想法基本一样。只不过放到了disagregated memory。

Client centric index replications
Remote Memory Allocation: RACE hashing+SNAPSHOT
Metadata Corruption: Embeded operation log
RACE Hashing: onesided RDMA hashing
Primary and write-write conflict resolution by last-writer(majority writer) wins and update the other place thereby.
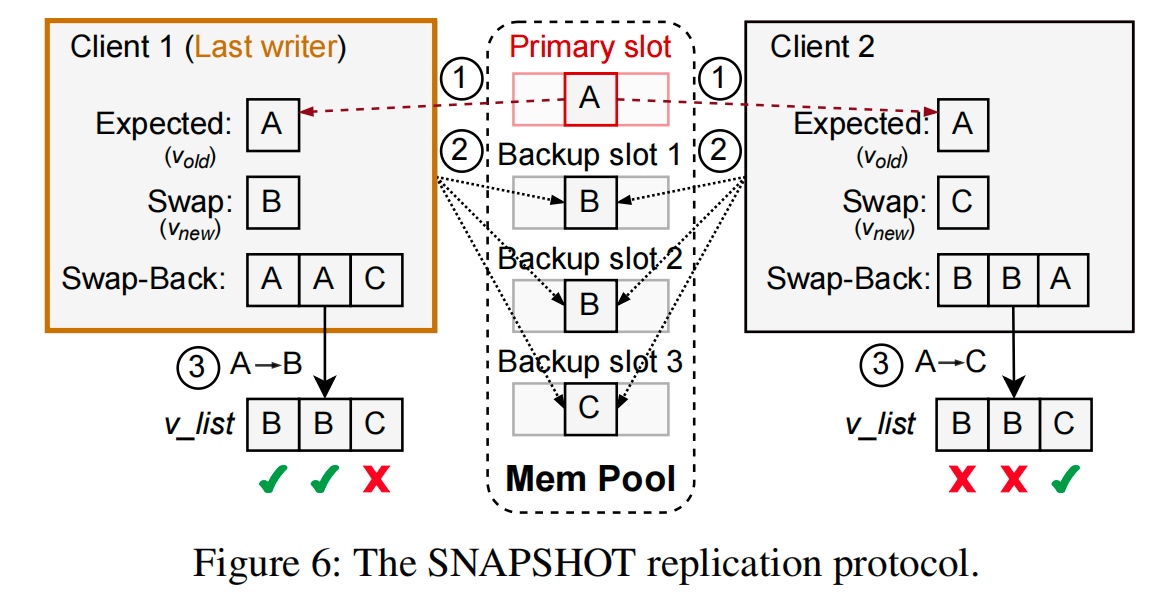
Compared with MDS that has key to hash for direct access to RDMA result. only 1 RTT for read.
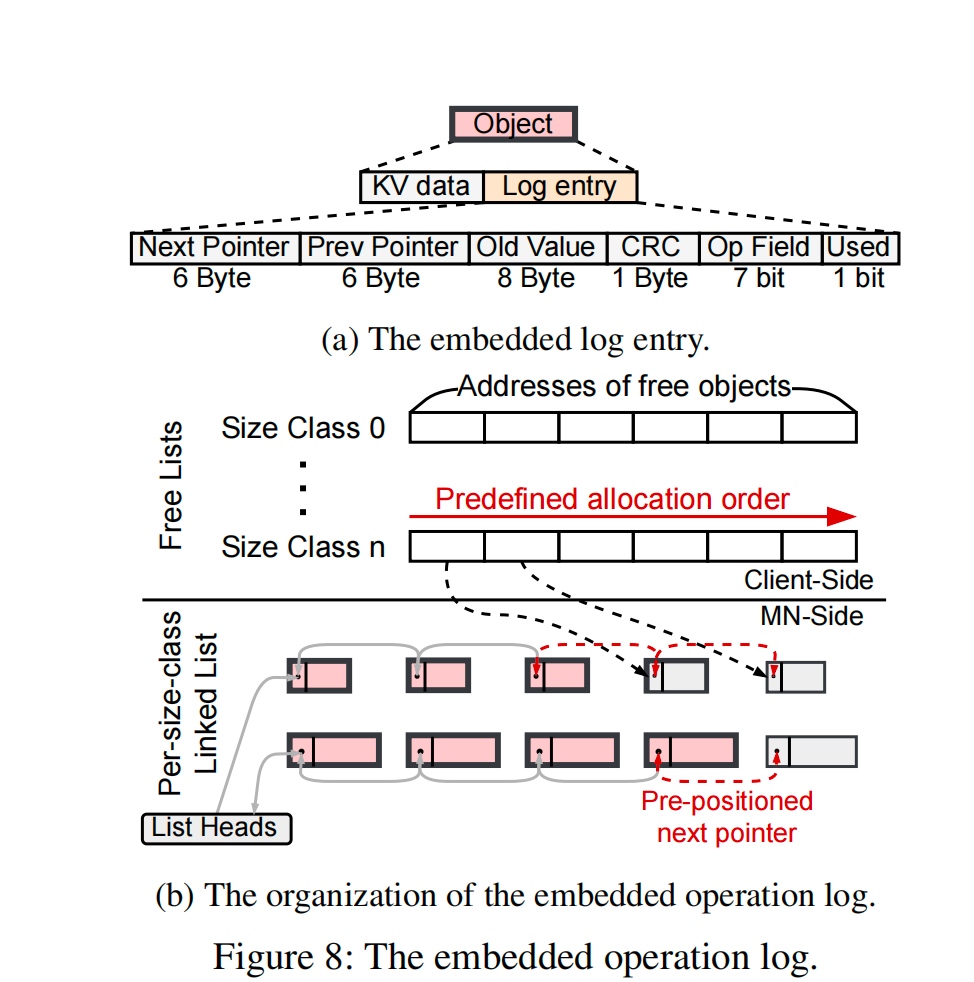
embedded operation log
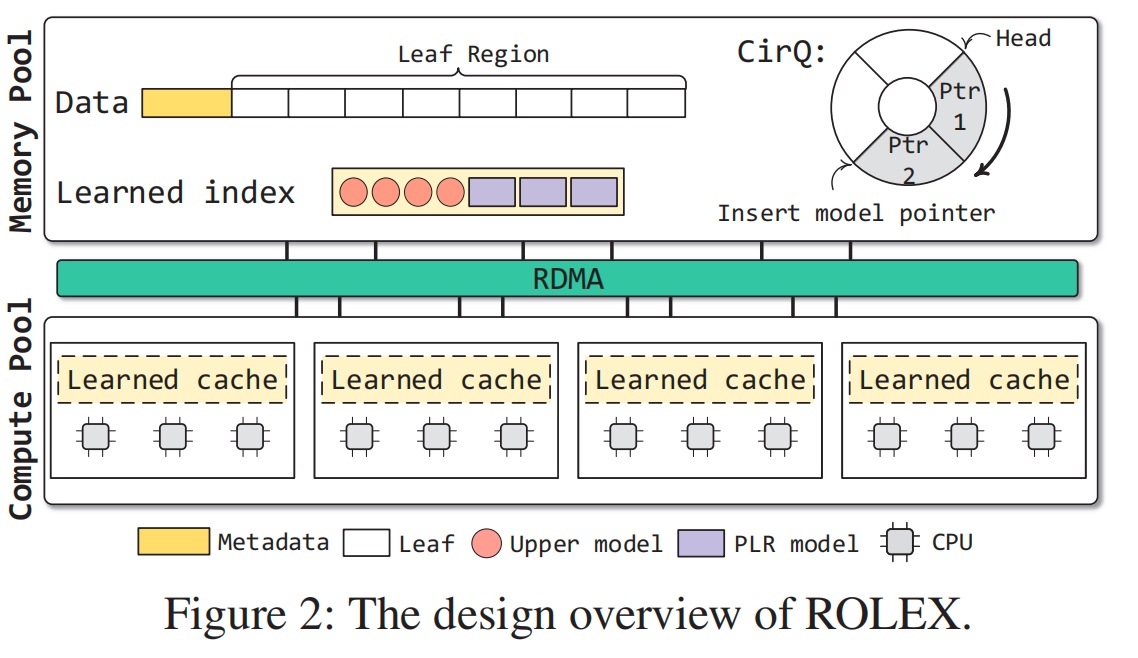
ROLEX: A Scalable RDMA-oriented Learned Key-Value Store for Disaggregated Memory Systems
Learned key data movement and allocation requires recomputed decoupled learned indexes. The desired data leaves are fixed size bby the retraining decouple algorithm mathematically, which makes migration easier.
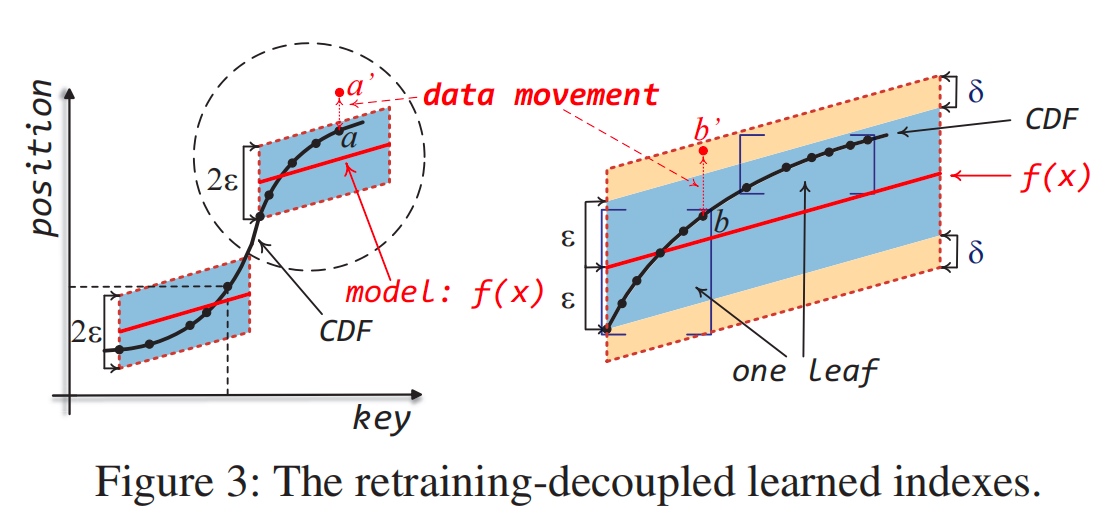
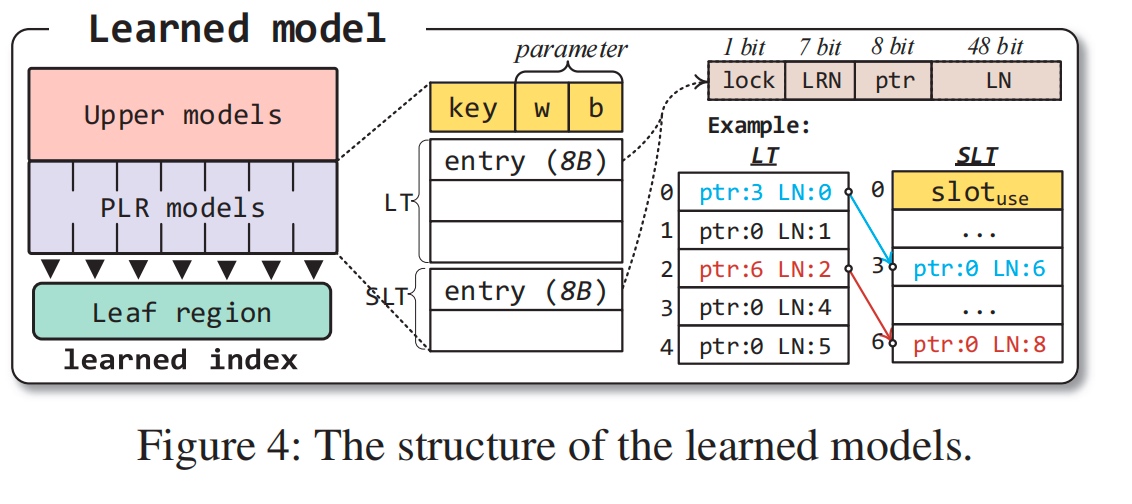
Consistency Guarantee, 感觉要同步的model的RDMA操作挺多的。
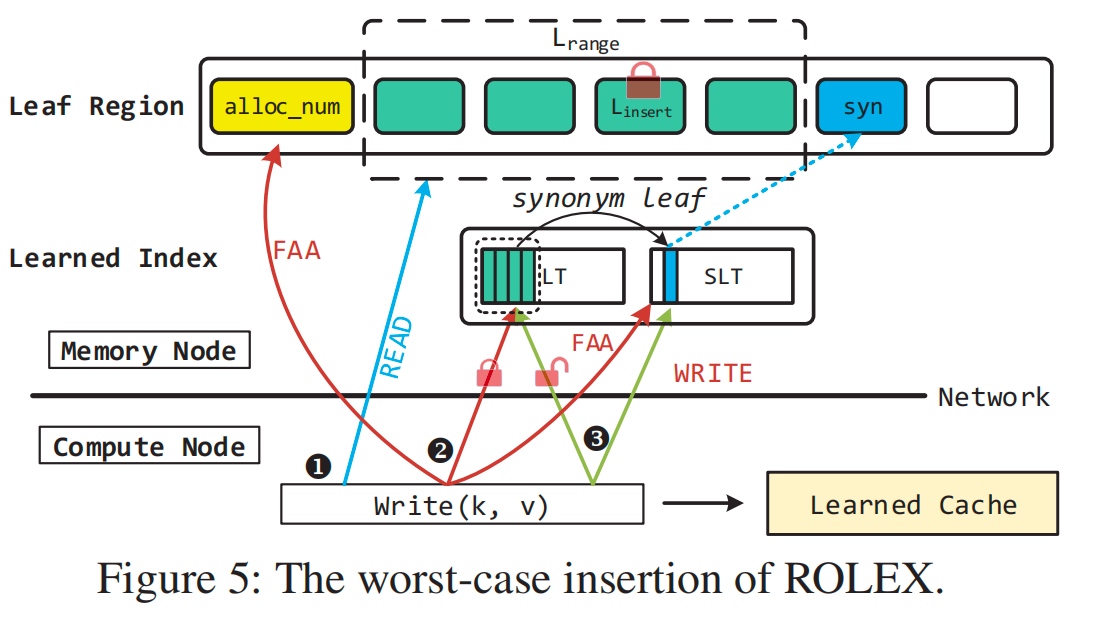
bit as lock? how to recover from the lock? future work.
Always update new model every read? first check the first entry of SLT. and update the model if changed.
AI and Storage
GL-Cache: Group-level learning for efficient and high-performance caching
xgboost学了utility time的metrics。然后按utility time evict。如果两个workloads公用cache就不行。以及如果cachesize很大我觉得预测的效率不如手动ttl的segcache。以及我觉得Transformer预测ttl更优秀,因为xgboost只是捕获信号,并没有预测能力。然后似乎这个metrics也是试出来的。
SHADE: Enable Fundamental Cacheability for Distributed Deep Learning Training
这篇是SC见到的同学的。
Intelligent Resource Scheduling for Co-located Latency-critical Services: A Multi-Model Collaborative Learning Approach
File Systems
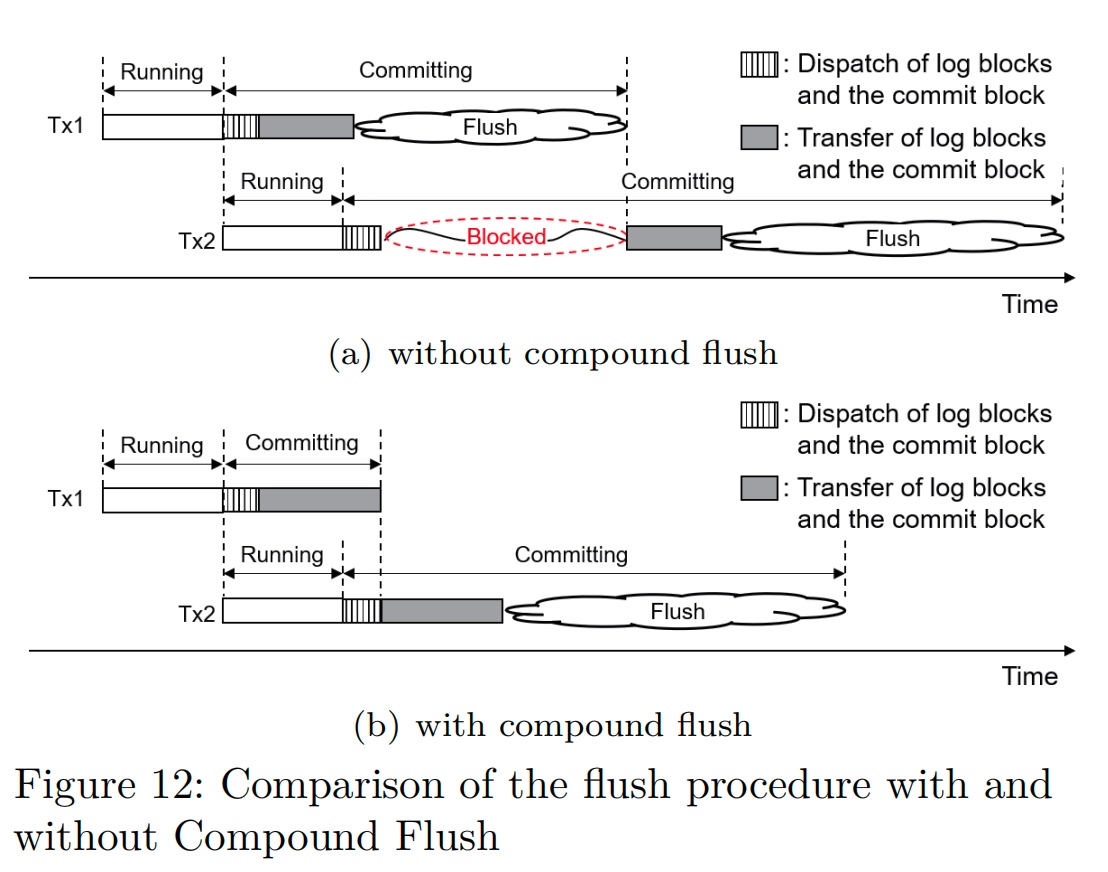
CJFS: Concurrent Journaling for Better Scalability
Multi version shadow paging
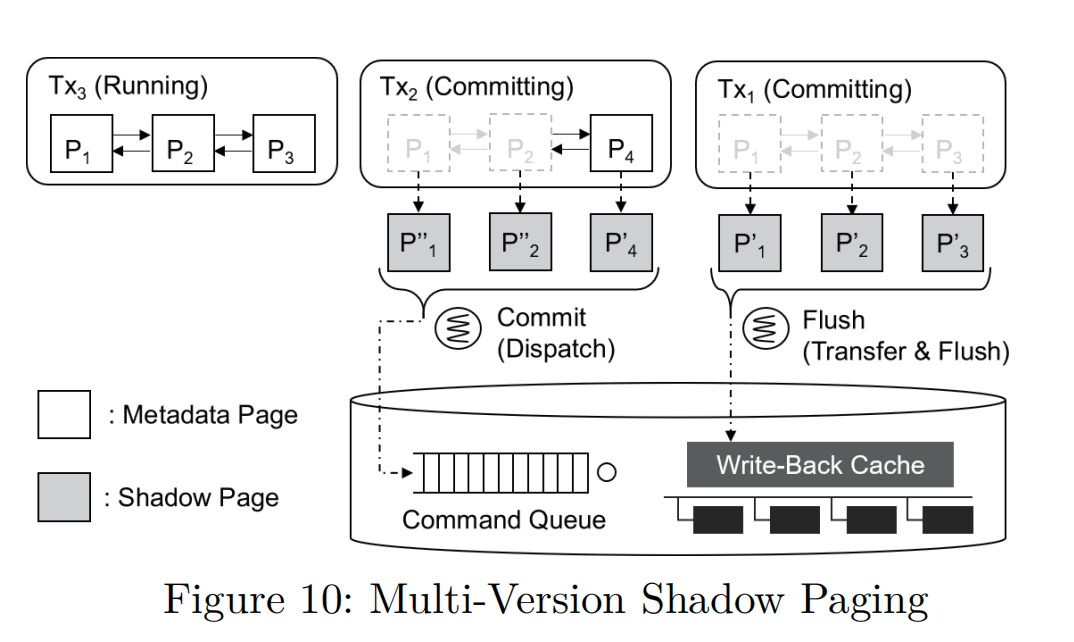
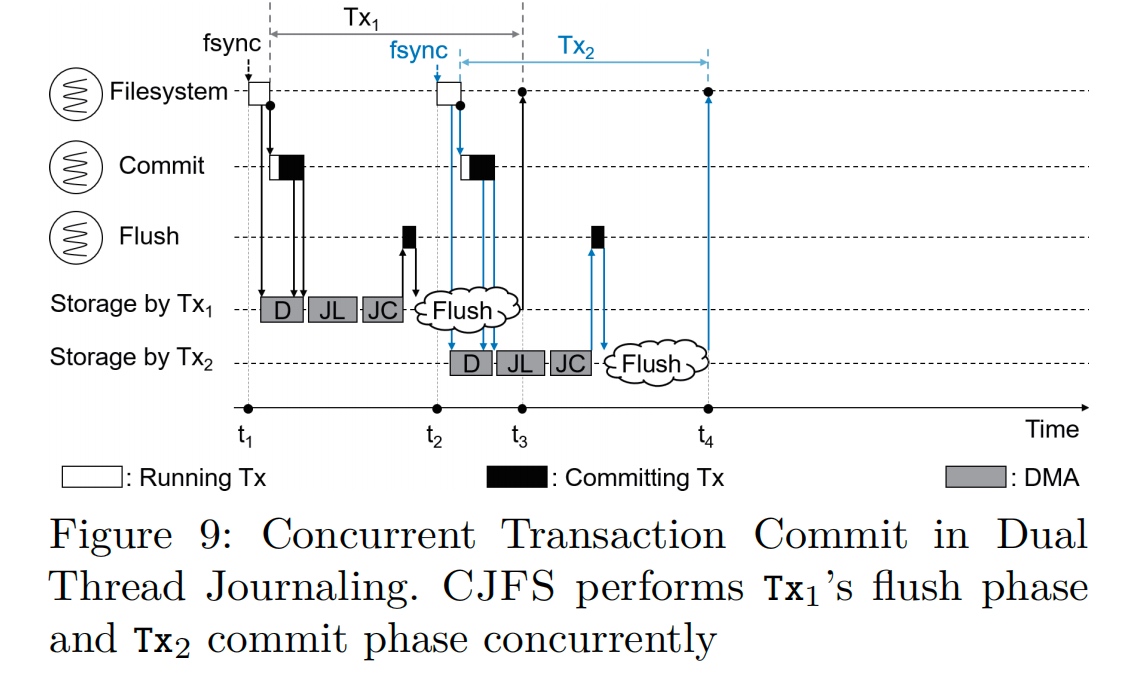
Compound flush: On Tx finish cache(DMA, which can be hack by CXL?) barrier send the interrupt to the storage.
Unsafe at Any Copy: Name Collisions from Mixing Case Sensitivities

name collision, 之前有个git CVE。
ConfD: Analyzing Configuration Dependencies of File Systems for Fun and Profit
软工找bug,实在太没意思了,改configuration(主要是allocator的内存格式/type信息/64bit?),然后污点分析,找这三个bug。

Compared with Hydra
HadaFS: A File System Bridging the Local and Shared Burst Buffer for Exascale Supercomputers
MadFS 在无锡超算上跑的。
Consulidate the links from userspace.
Fisc: A Large-scale Cloud-native-oriented File System
是一个南大网络组的人去了盘古。阿里巴巴双十一现在完全基于这个了。
相当于implement了一个 lightweight file system client to improve the multiplexing of resources with a two-layer resource aggregation。每个computation storage vRPC agent proxy做负载均衡。
RPC serialization? 没有指针,docker/container的metadata都是flat的(只有offset),他们RPC几乎相当于RDMA over memcpy,很lightweight。 load balancer只做file-granularity based。如果DPU硬件fail了,直接RDMA migrate docker,其他请求fallback slow path,很快,用户无感。如果用户觉得IO慢了会提供全链路trace。
Persistent Memory Systems
TENET: Memory Safe and Fault Tolerant Persistent Transactional Memory
用tag+地址Btree连在一起的方式防止buffer overflow和dangling ptr。
MadFS: Per-File Virtualization for Userspace Persistent Memory Filesystems
file+dummy(2MB granularity)重排了文件写在DAX Pmem上,有写放大。concurrent control用的是CAS。metadata concurrent write好像没有处理,后来理解了因为open的寓意保证了write不会contension。
On Stacking a Persistent Memory File System on Legacy File Systems
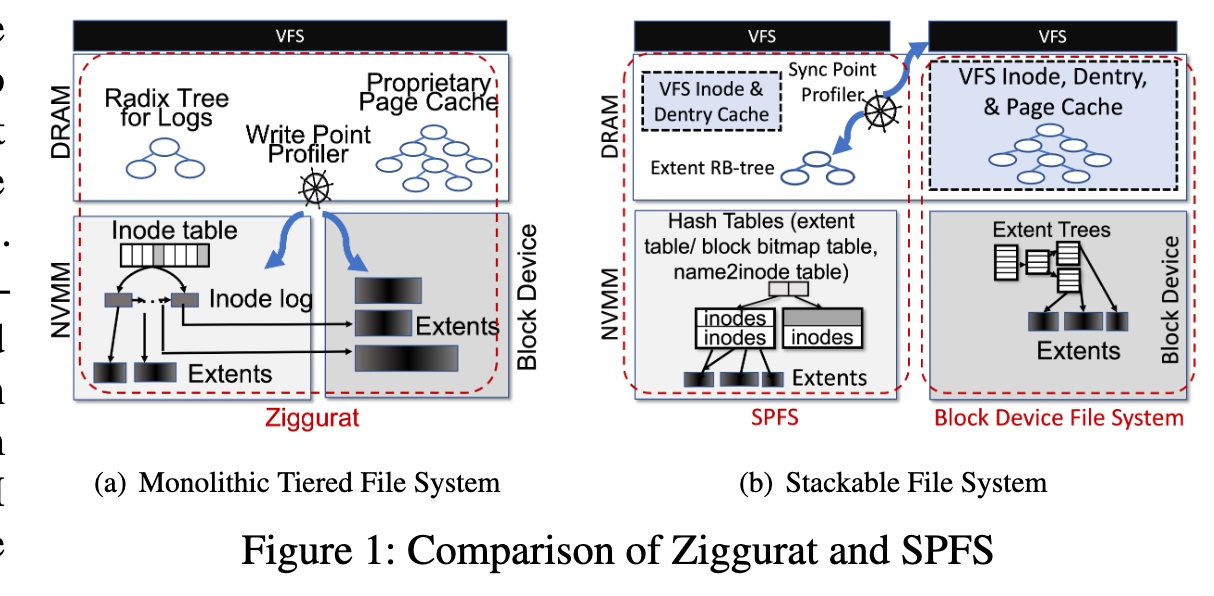
Stackable Memory Filesystem over normal filesystem.上面的内存文件系统比较轻量extent RB tree。Sync file system factor设计和dirty page wb有点像。
extent hashing和下面同步
Remote Memory
Citron: Distributed Range Lock Management with One-sided RDMA
线段树map ranges to tree ndoe。
Ext-CAS+Ext-TAA
Patronus: High-Performance and Protective Remote Memory
用per memory window multiple qp and remote lease to protect the file,
More Than Capacity: Performance-oriented Evolution of Pangu in Alibaba
盘古牛逼
IO Stacks
λ-IO: A Unified IO Stack for Computational Storage
陆老师和杨者的文章,想法是在kernel和SSD driver上跑统一的eBPF.
sBPF是对eBPF检查的减弱,想offload computation eBPF code没有语意上的限制。
通过page cache来观测是否在in memory database在kernel里可以被reuse,用这个metrics offload计算到设备。同时利用host CPU资源快,内存大,device计算资源少内存少但是离storage近,只用返回计算结果。
实验在SF=40 TPCH over Java上做,把syscall 分解为 read_λ(read, percentage, λ)的形式。λ本身就是sBPF的程序。
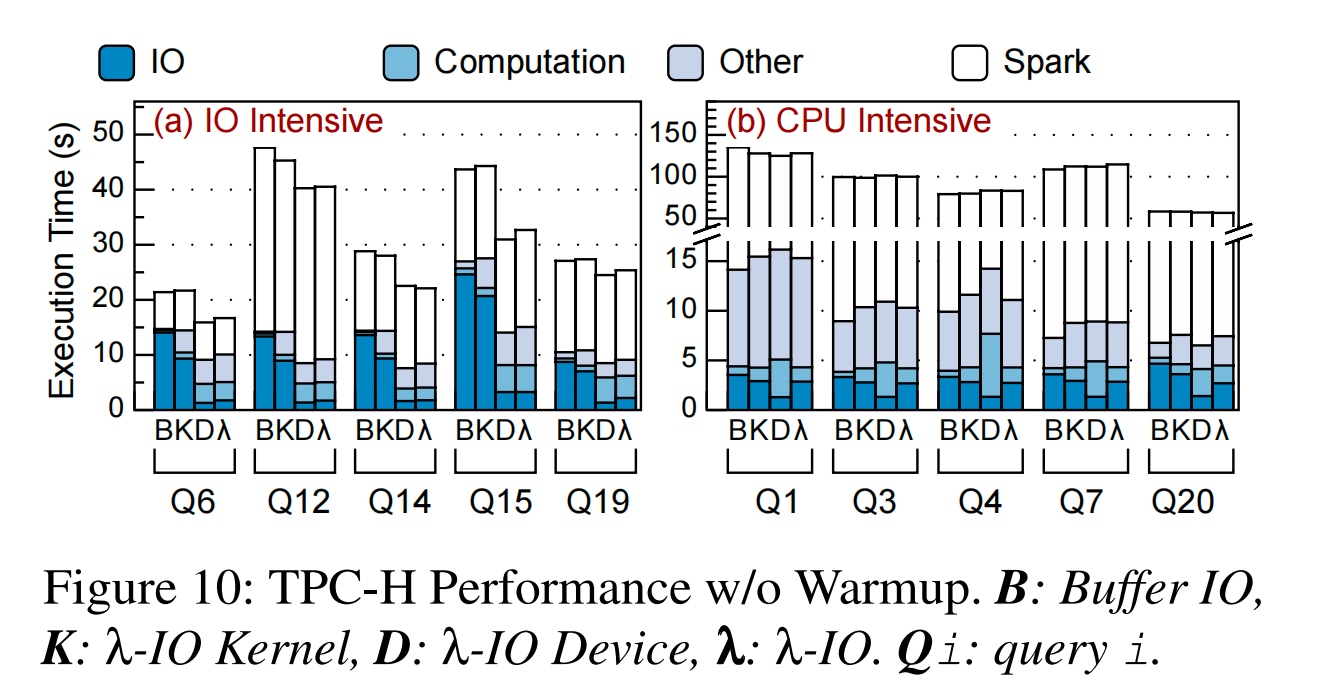
结果非常好,有2.16倍的加速
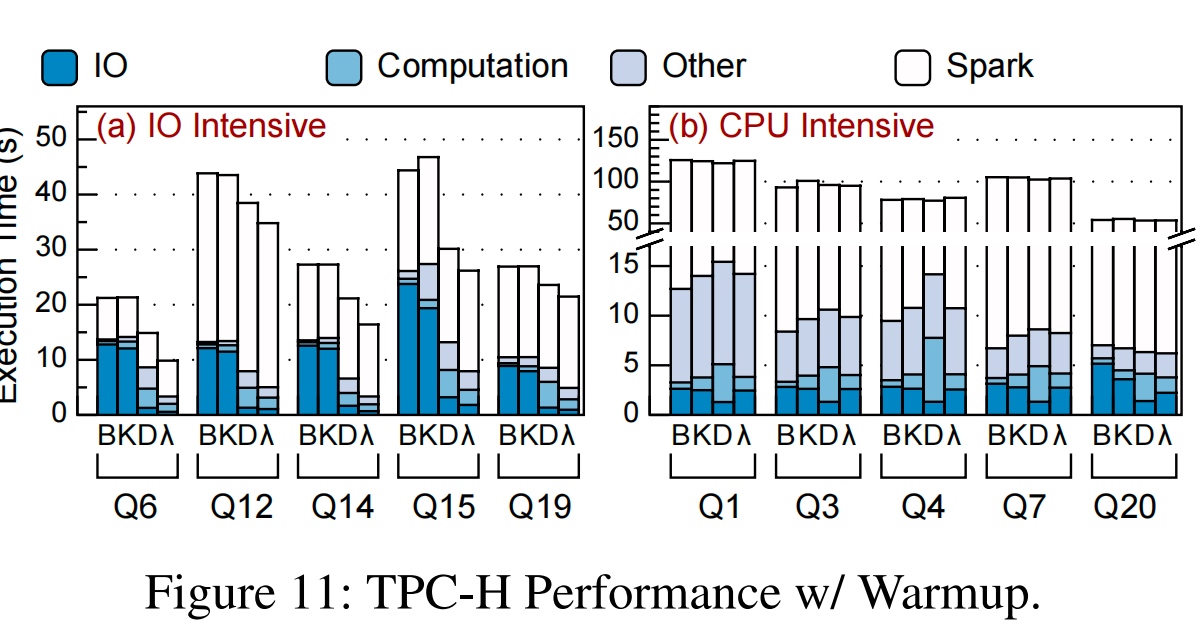
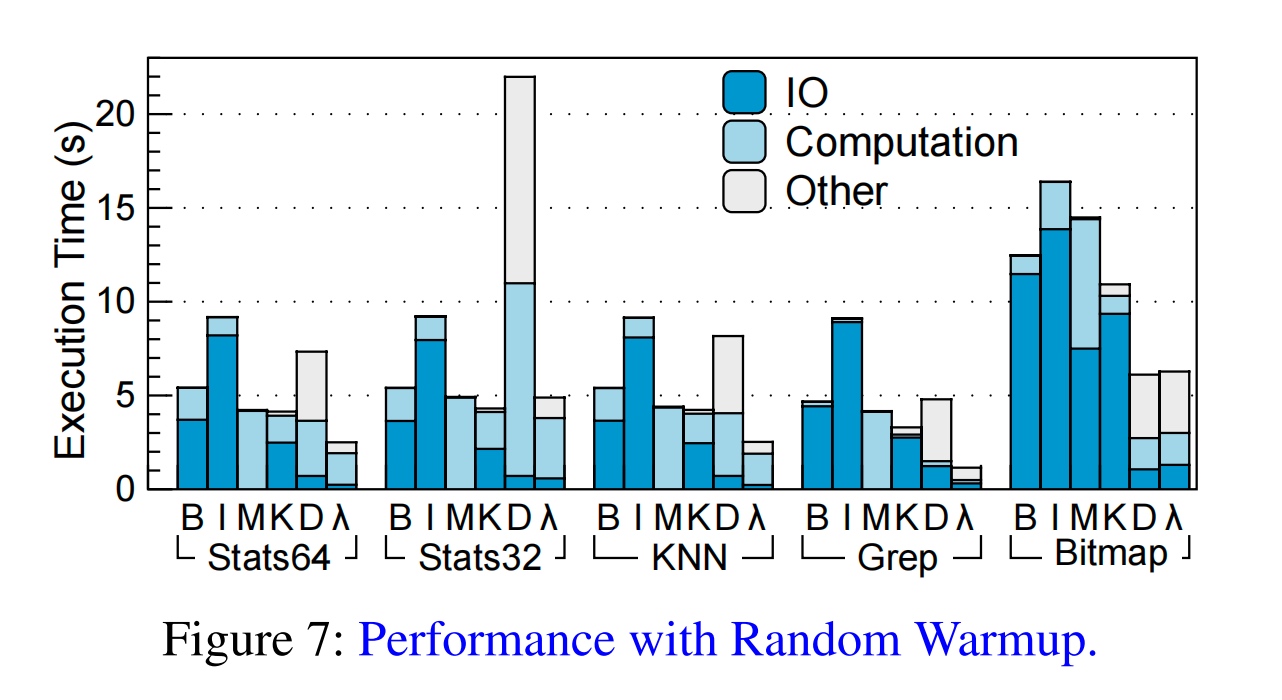
Why not Native?统一框架。 我们发现mmap的部分都是计算时间,于是,load from device mmap+page fault and trigger userspace WebAssembly computation? for mmap very fast。
CXL+eBPF,small pagetable for transaction?fast getting metrics from cacheline network,decide load or store and dma?
有一个concern是会占满PCIe Root Complex的带宽,仅仅观测page cache大小是会出问题。
Revitalizing the Forgotten On-Chip DMA to Expedite Data Movement in NVM-based Storage Systems
NVMeVirt: A Versatile Software-defined Virtual NVMe Device
更准的SSD模拟器,问了个为什么不模拟CXLSSD的问题。
SMRSTORE: A Storage Engine for Cloud Object Storage on HM-SMR Drives
按zone分chunk在OSS更优,而且SMR问题determinist分配zone是一个比较优的策略。
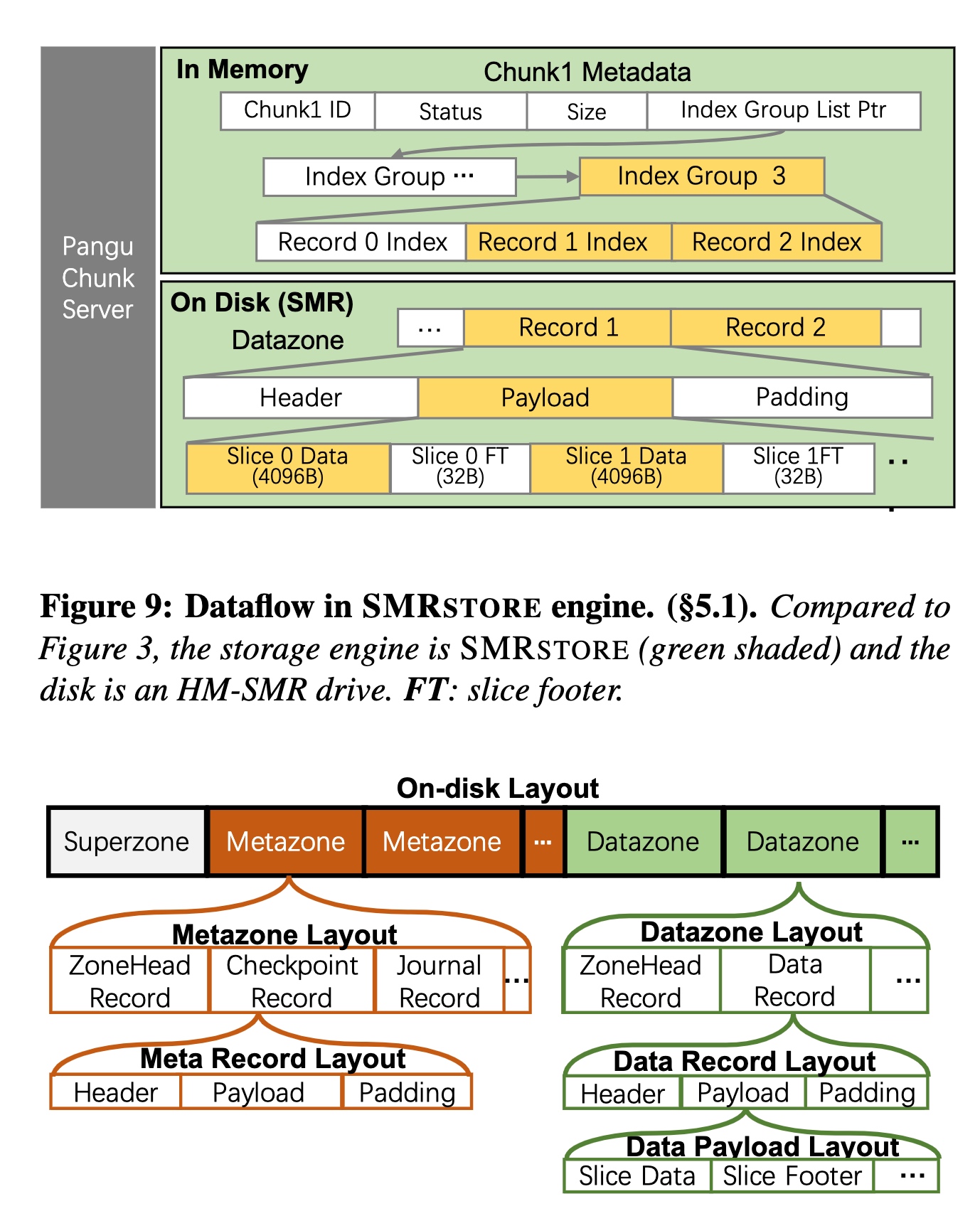
15%reduction of time
SSDs and Smartphones
Multi-view Feature-based SSD Failure Prediction: What, When, and Why
用时序数据predict results
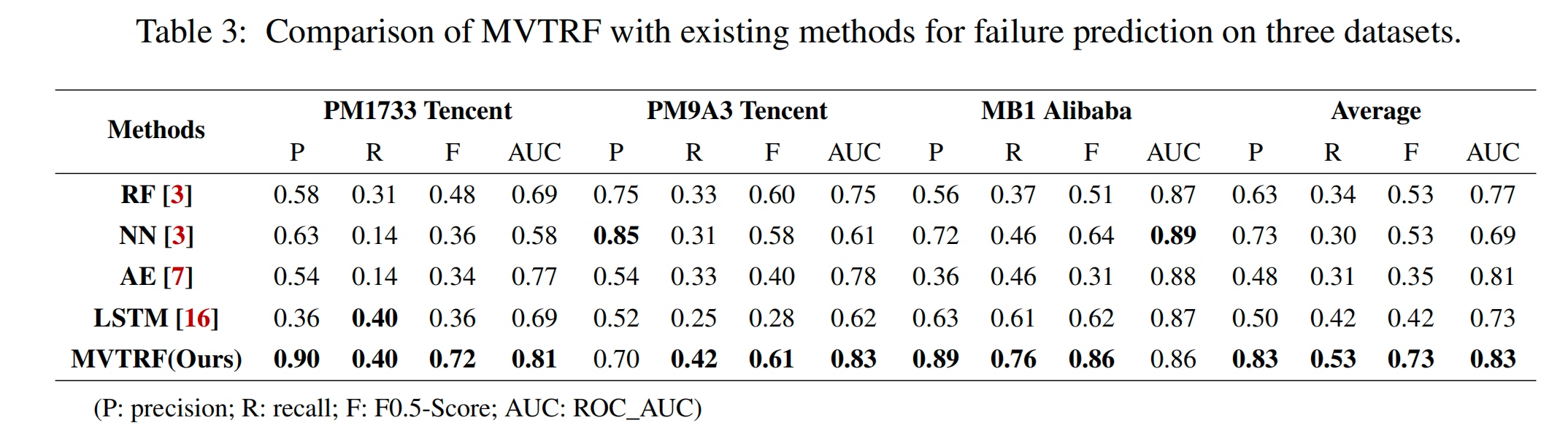
但是对异常数据不是很敏感。
Fast Application Launch on Personal Computing/Communication Devices
不是很懂
Integrated Host-SSD Mapping Table Management for Improving User Experience of Smartphones
拿L2P数据prefetch UFS的。在UFS上的数据结构比较deterministic。