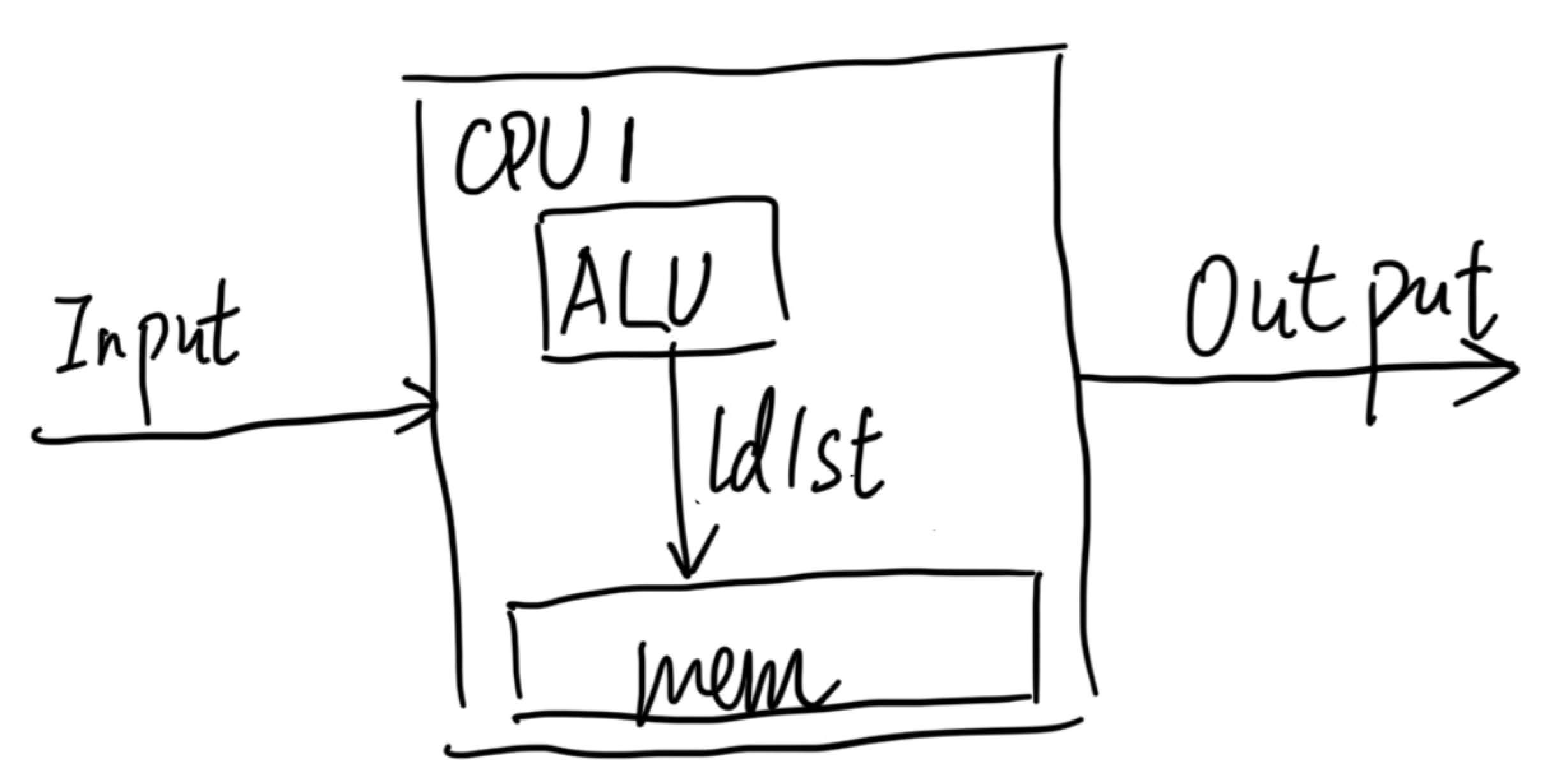
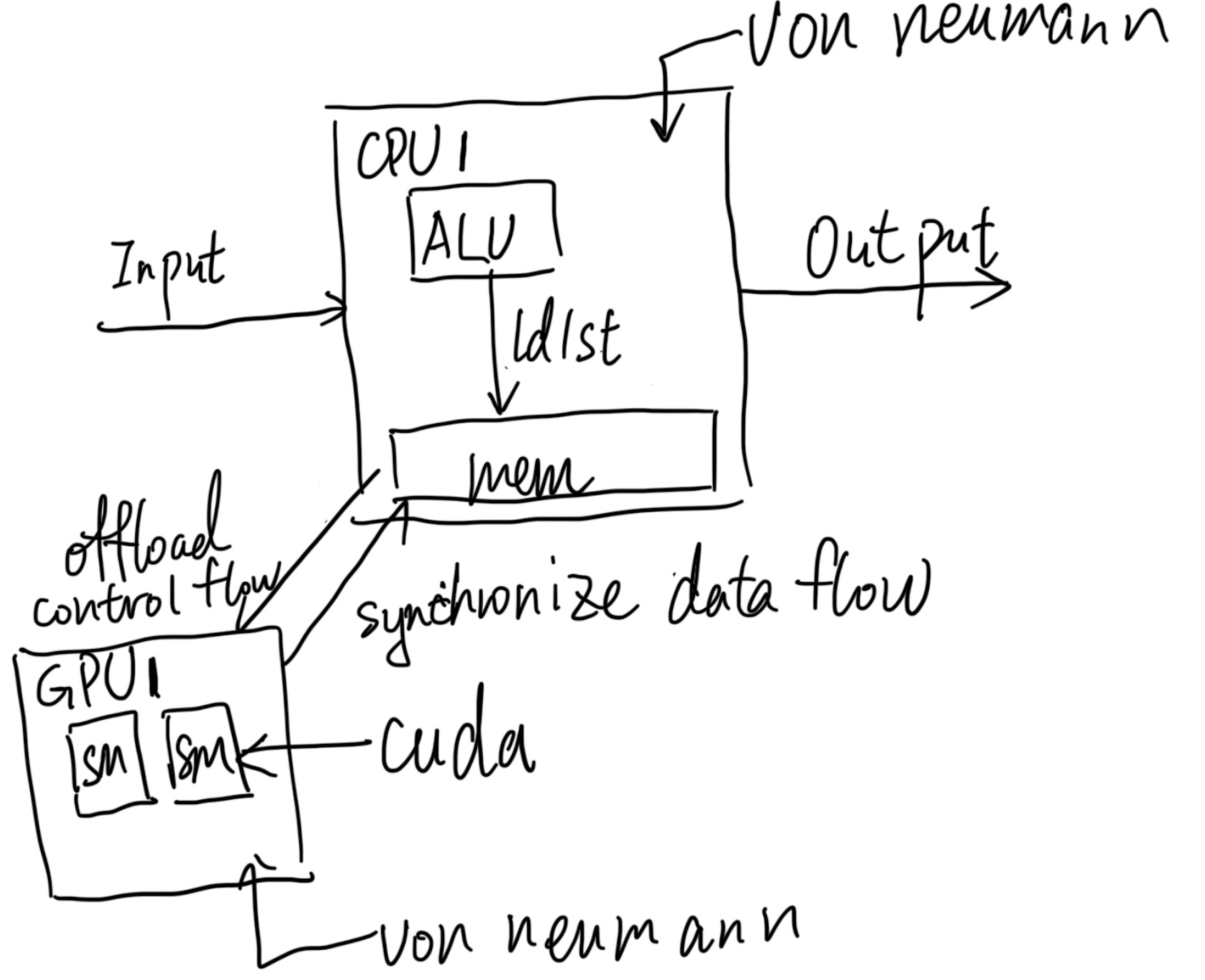
The current trend of developing AI accelerators is not following Von Neumann's view. What was Von Neumann's outcome? Multi-tenancy, virtualization, fine-grained scheduling, mapping back to the compiler, and cross-platform live migration. Why is this property deprecated in a lot of so-called Von Neumann Architecture? It's because the current microarchitecture state is too complicated to fully manifest for the programmers to understand, which cancels out a lot of people's interests. I think Professor Jiang Yanyan's abstraction of the operating system as an automaton is incorrect because of the explosion of the transparent state to OS; the GPU is not fully debuggable, letting along other coarse-grained architecture in TPU. So if you couldn't fine-tune your scheduling, the outcome is if the workload is constantly changing, your chip and infrastructure will never beat Nvidia because they have better infrastructure, and TFLOPS is close to the extreme of what any chip can do. Tomorrow, if I want to deploy LLM+HPC, all the DSA will just die because of this. I think the abstraction of CUDA or the abstraction of C++ language level is good for programmers to program, but far more deviated from the Von Neumann property all done. If other academic proposals want to commercialize either one of the DSAs, like TPU, CGRA, Like-brain, or PIM, they might lose any of the above Von Neumann properties and won't be useful if those architectures don't have the 10x speedup and agility that CUDA and GPU provide.
In terms of virtualization, GPUs are never ready for virtualization because the current virtualization techniques on GPUs are still VFIO, which is CPU-dominated and slow. Ray, as I mentioned before, has a Von Neumann Memory Wall, and epoch-based is not fine-grain granularity. and we should never adapt to the front end like PyTorch or CUDA because it doesn't change anything in the meaningless abstraction or working for monopoly; we need a revolution from the architecture and back to the abstract to the language. We need to go back to normal; why did we lose this property? In the realm of modern GPU architectures, there's an emerging sentiment: as long as we utilize CUDA's Just-In-Time (JIT) compilation capabilities, we can achieve a faster Virtual Instruction Set Architecture (ISA)—for instance, something akin to WebGPU/Vulkan/ptx. This could lead to virtualization speeds surpassing traditional methods like VFIO with no semantic or performance sacrifice.
Am I saying DSA is no longer useful? No, if everything in a space is very mature, I guess the DSA will eventually win, but things change every day. Speculative decoding is mathematically the same as whole decoding, saving your training set 10 times, so your TPU is not agile enough to tailor to this change, but your GPU can quickly adopt the new math advancement. TPU has an inference market. If Google Gemini is going to take everybody in the next month, the TPU behind it will be very money-saving in terms of the electricity cost, which only Google can do in the entire universe. Other technologies, like CGRA or like-brain technology, are unsolvable in the near future.
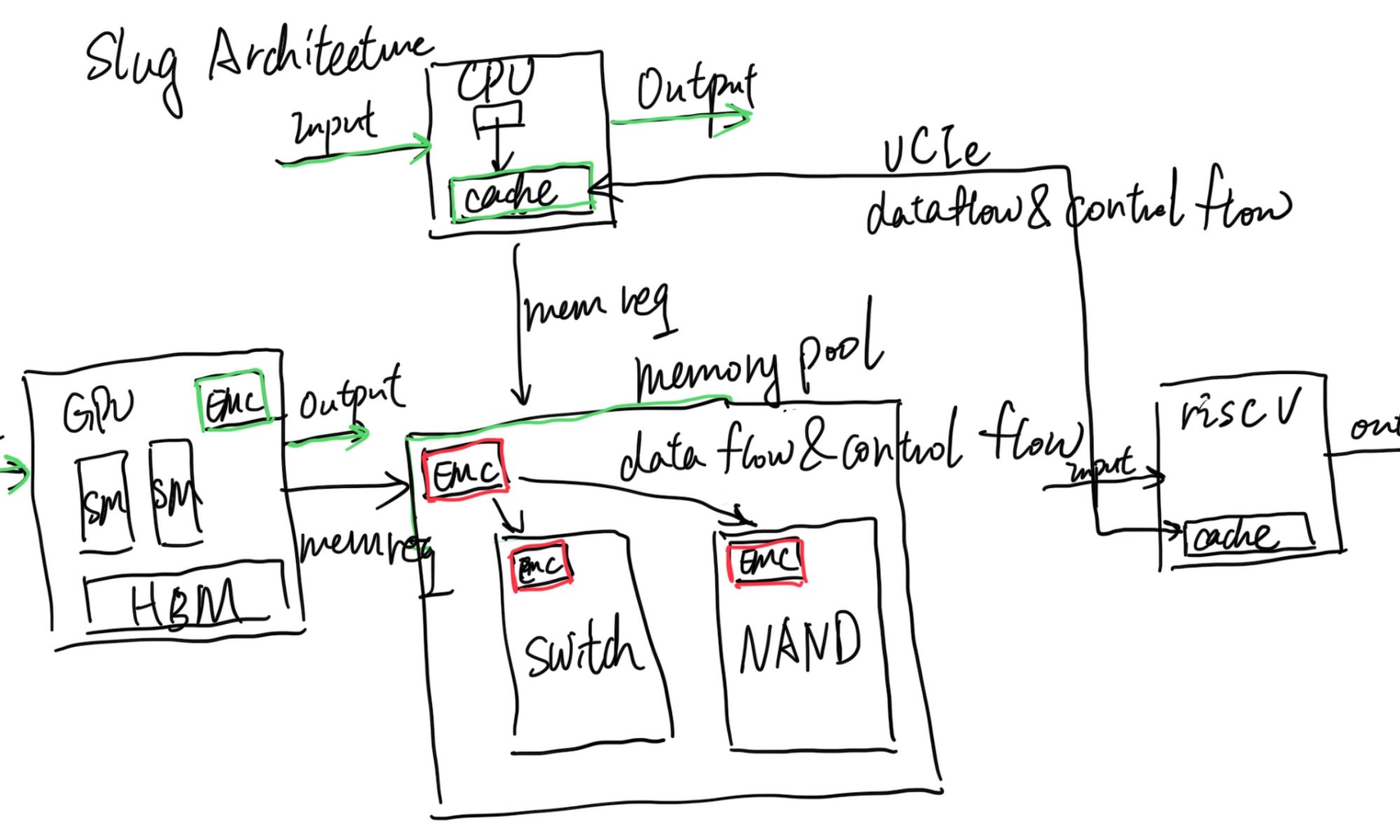
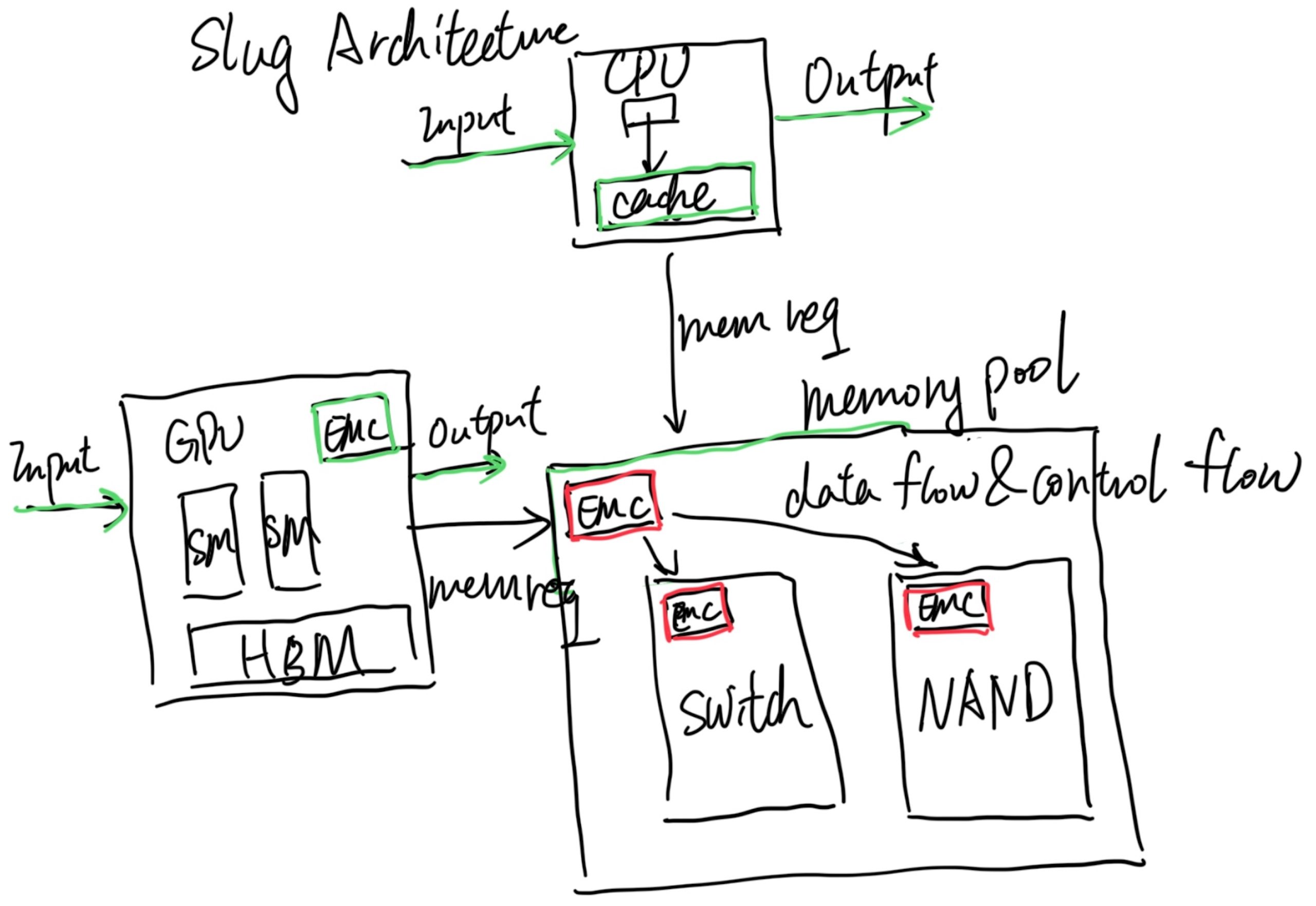
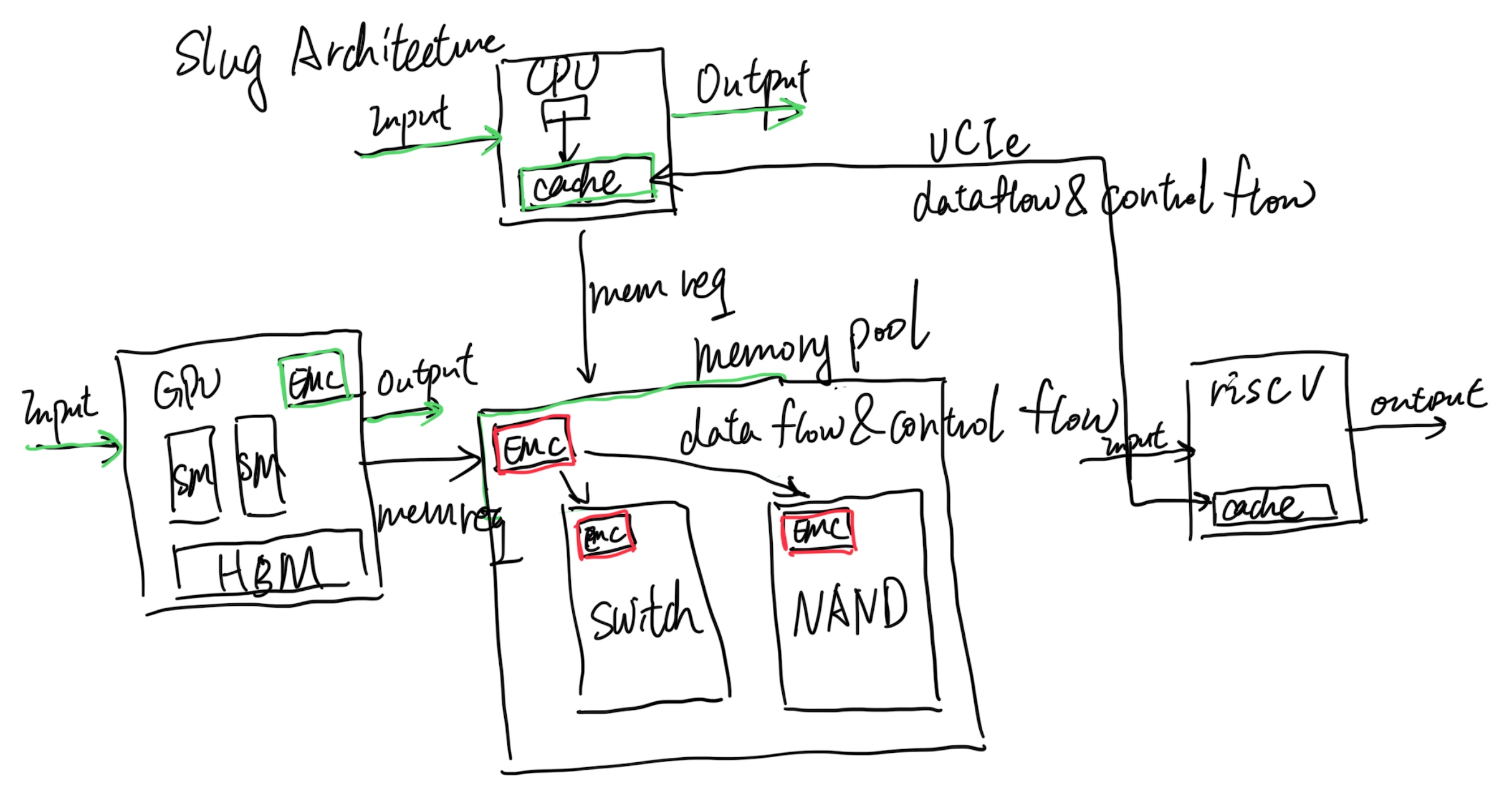
ExaScale aims to beat Nvidia, not by breaking the monopoly that Nvidia has, but first by making transparent migration over different GPUs and connecting them within a memory pool that is not Nvidia's alone. This will facilitate price competition because Nvidia will no longer have competitive edges. The second is to hack the interconnect through CXL or another faster fabric that beats NVLink with software hardware codesign like CXLMemUring. I guess this movement will be the future of how we integrate everything!