

文章目录[隐藏]
Greater Instruction-Level Parallelism (ILP)
- Multiple issue “superscalar”
- Replicate pipeline stages ⇒ multiple pipelines
- Start multiple instructions per clock cycle – CPI < 1, so use Instructions Per Cycle (IPC)
- E.g., 4GHz 4-way multiple-issue
- 16 BIPS, peak CPI = 0.25, peak IPC = 4
- But dependencies reduce this in practic
- “Out-of-Order” execution
- Reorder instructions dynamically in hardware to reduce impact of hazards
- Hyper-threading
Pipelining recap
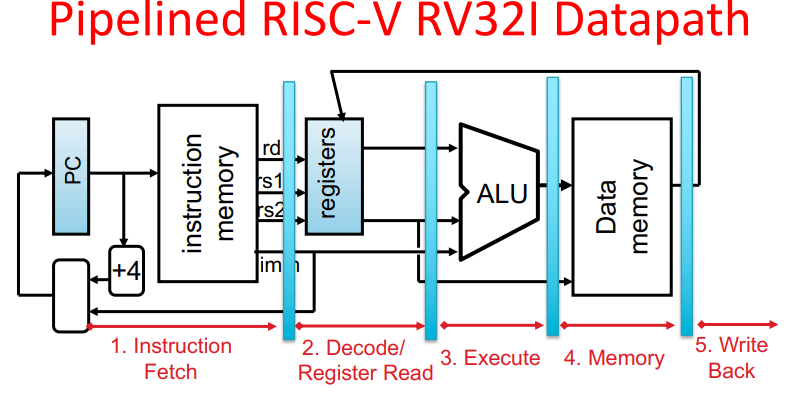
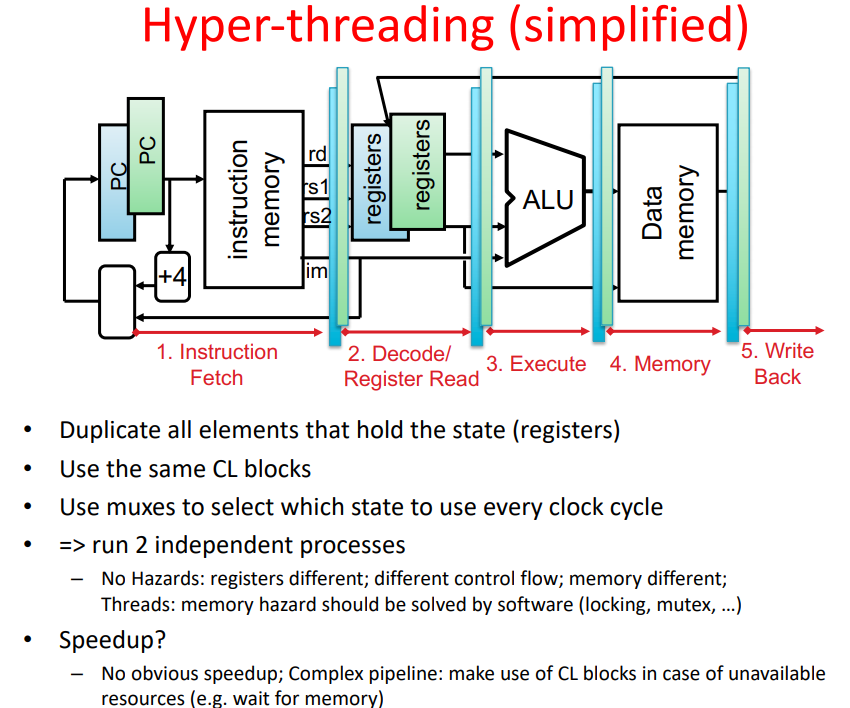
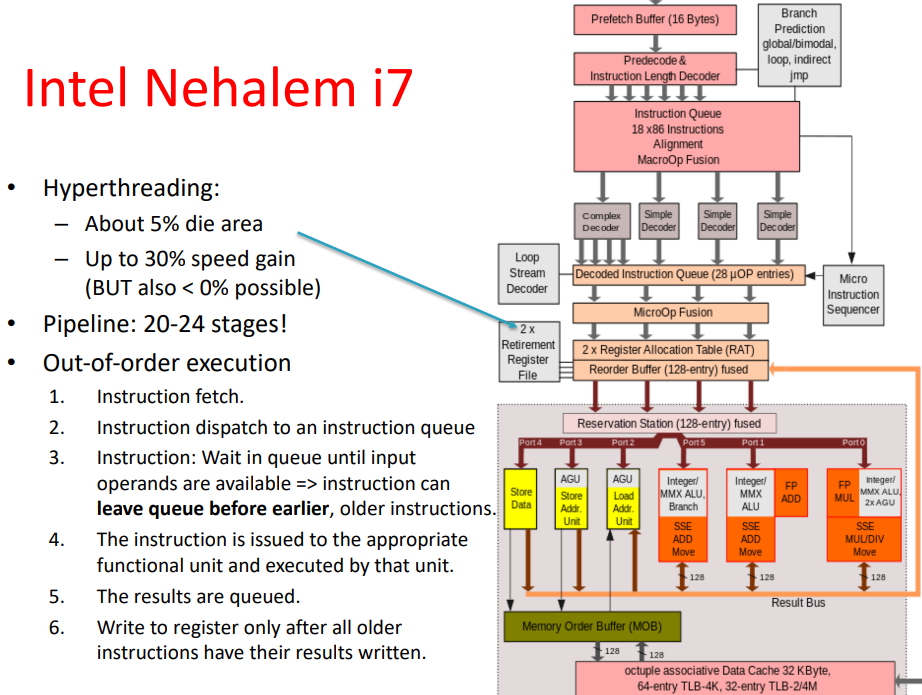
pipelines complexities exlained
GPRs FPRs
- More than one Functional Unit
- Floating point execution!
- Fadd & Fmul: fixed number of cycles; > 1
- Fdiv: unknown number of cycles!
- Memory access: on Cache miss unknown number of cycles
- Issue: Assign instruction to functional unit
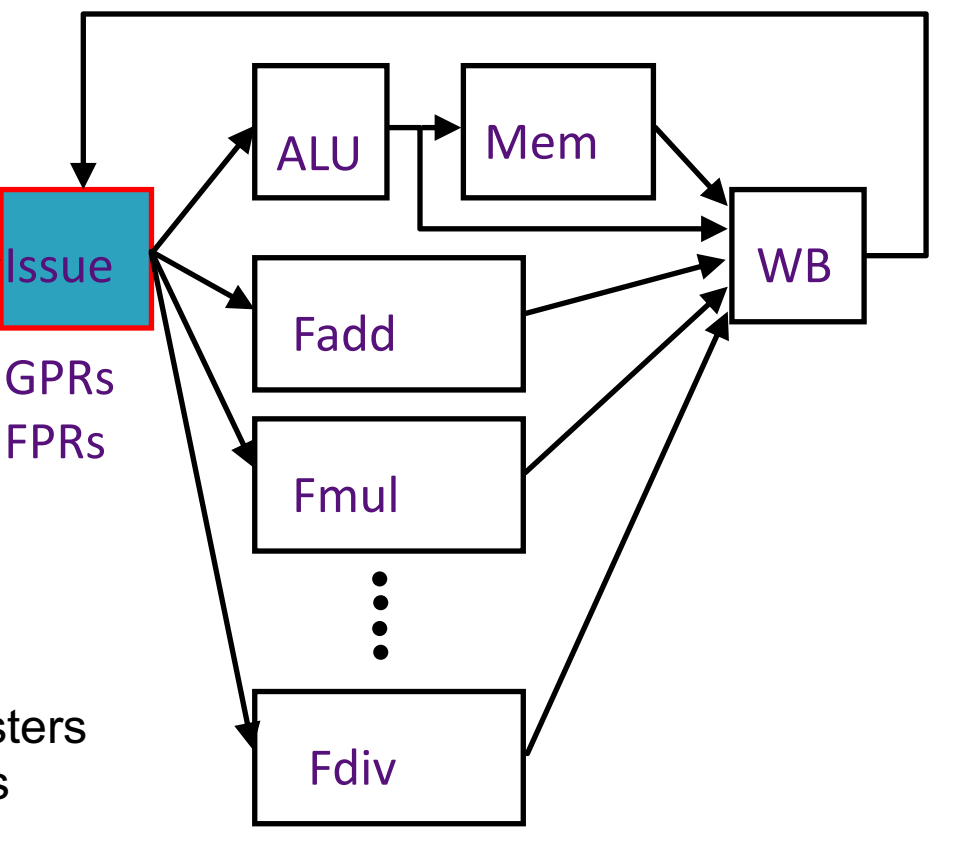
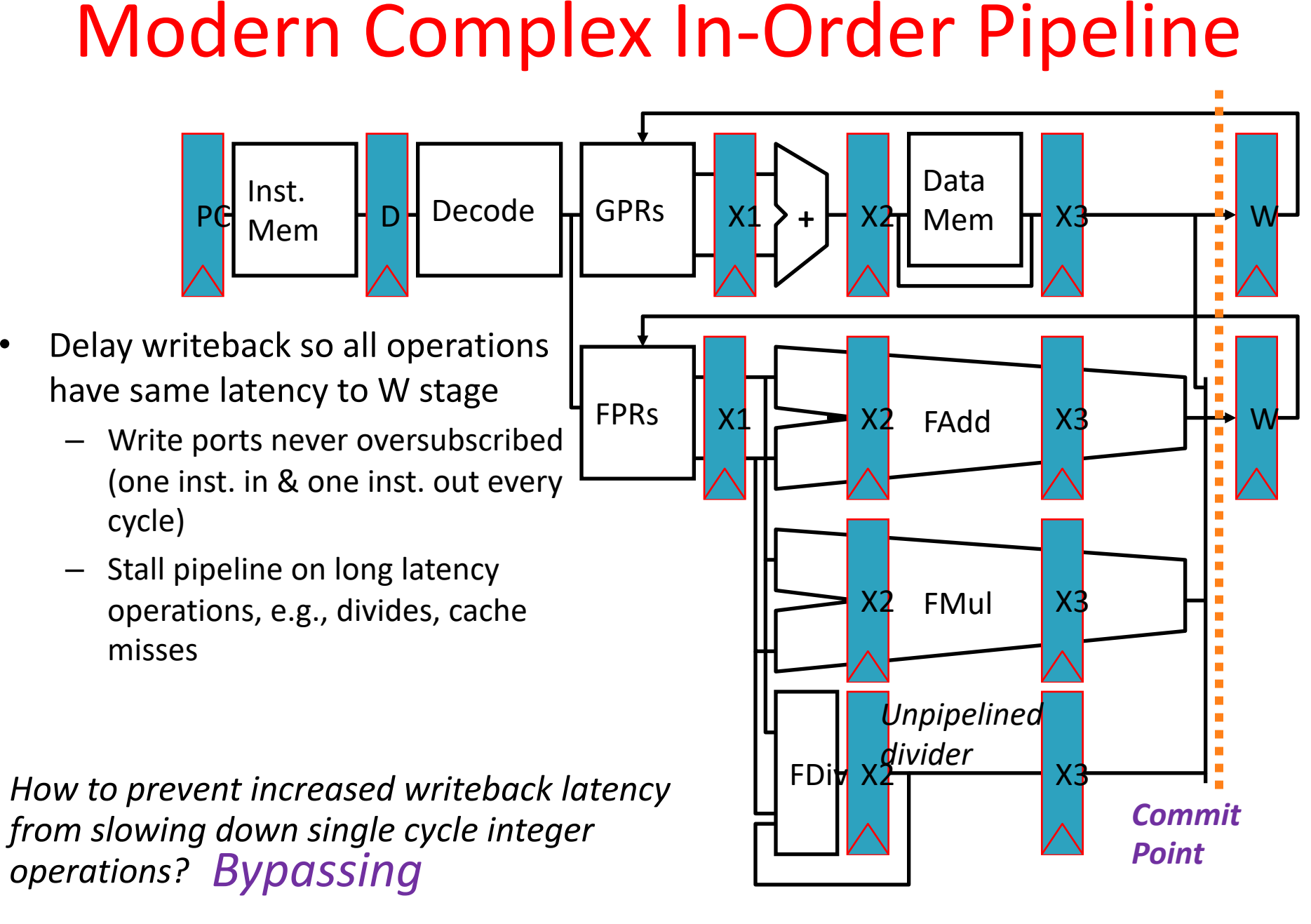
summary
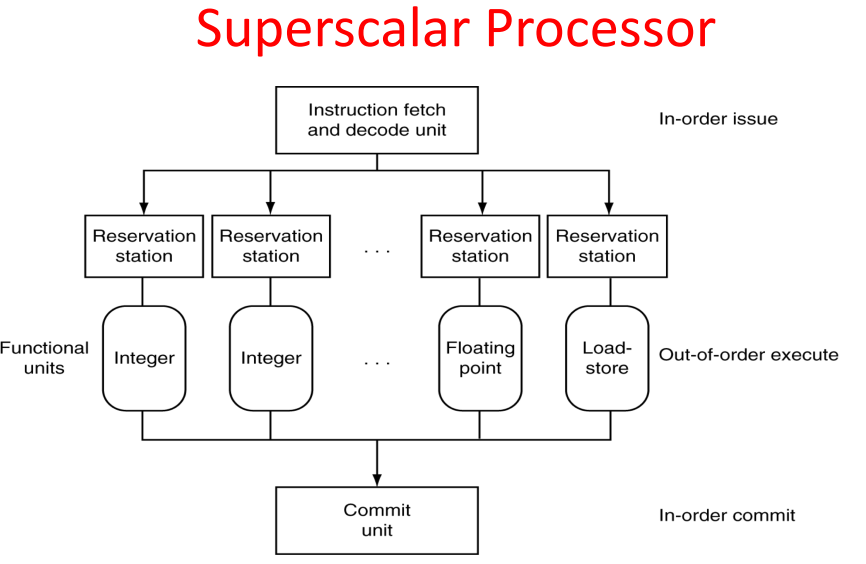
Some static multiple issues
VLIW: very long instruction word
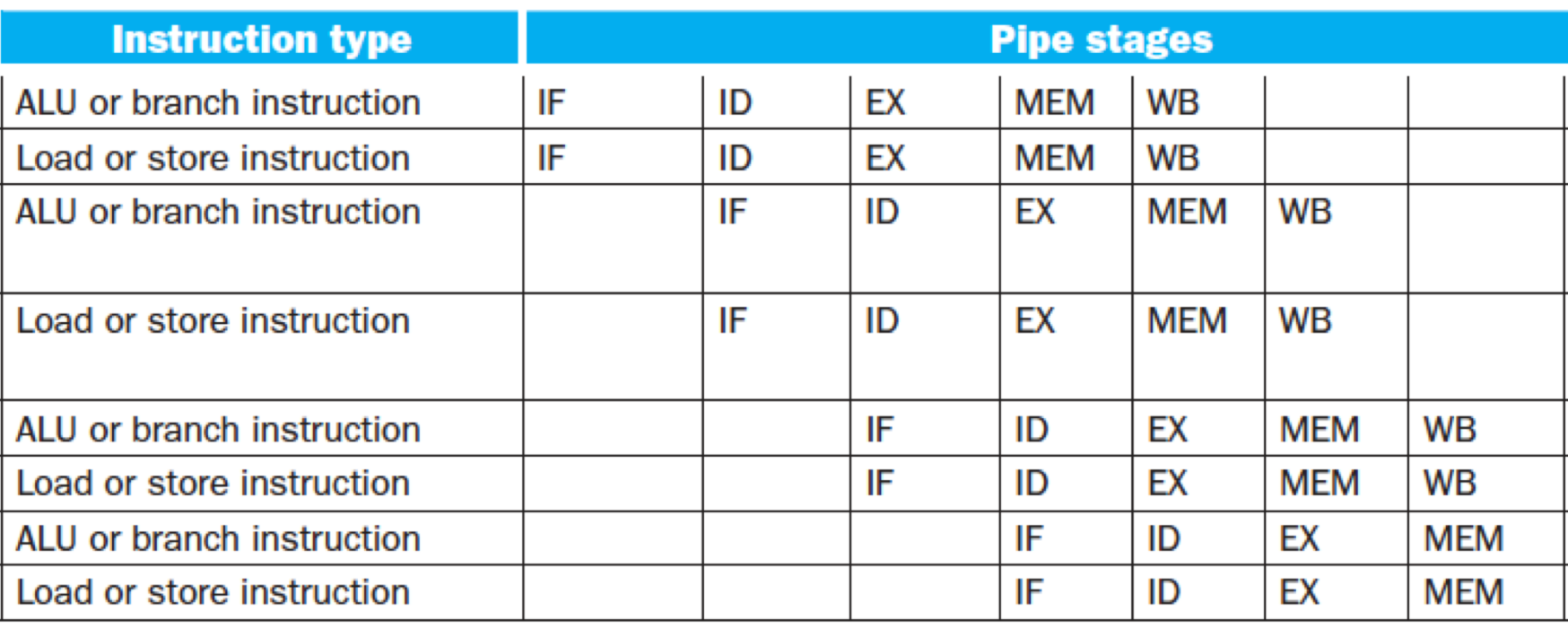
The solution can be easily found
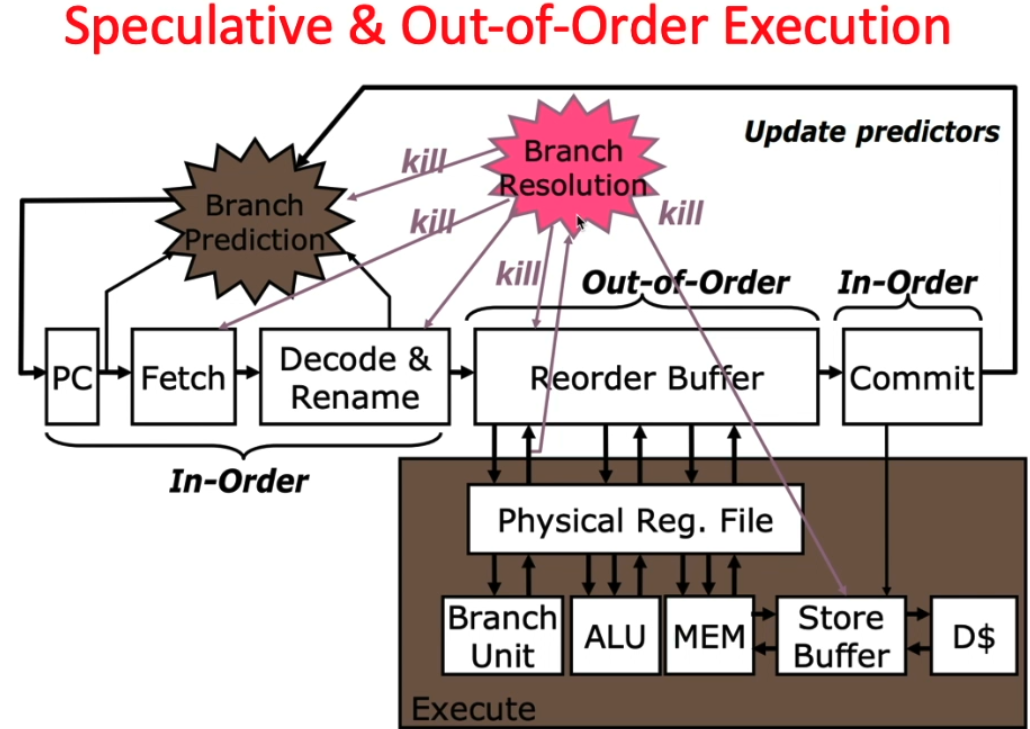
Quiz
[ ] A. In-order processors have a CPI >=1
[x] B. more stages allow a higher clock frequency