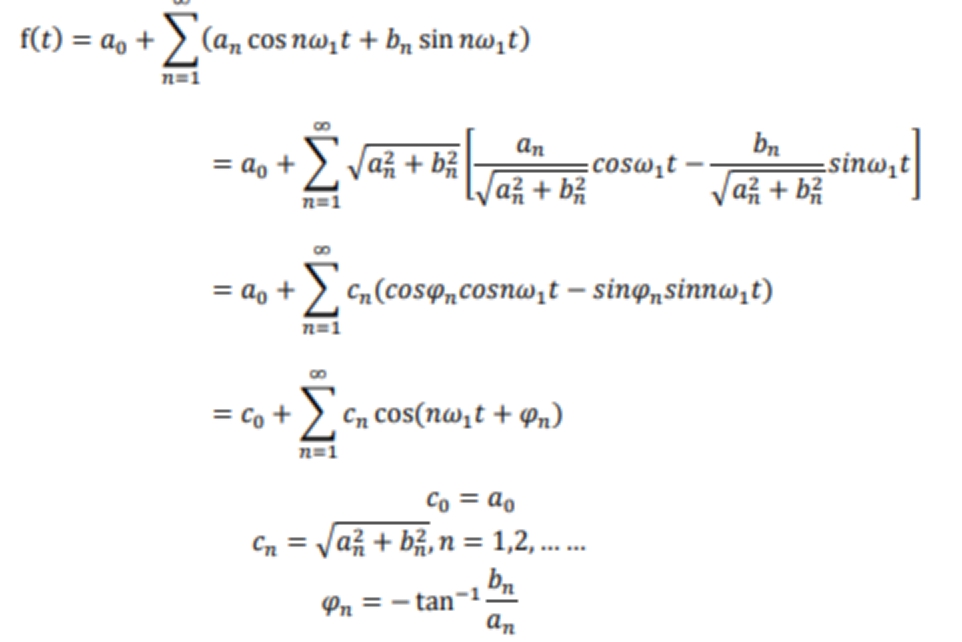
credit those who've helped me on x86tom site and pcbeta.
http://openwrt.victoryang00.xyz:8880/index.php?share/file&user=1&sid=qeEj3QHF


A Tech Nerd with a finance mind.
credit those who've helped me on x86tom site and pcbeta.
http://openwrt.victoryang00.xyz:8880/index.php?share/file&user=1&sid=qeEj3QHF
I manually do some stuff like
wget -r -p -np -k http://ics.nju.edu.cn/~jyywiki/
Many of the time you may get into the scenario the page you scripy from the website. they are rendered by the js. Admittedly, you can continue to use request_html. The idea is to use Chroium core to dynamically render the js page and grab the important information.
from requests_html import HTMLSession
If you want to deploy them locally, you have to get the express.
var express = require('express');
var path = require('path');
var ejs = require('ejs');
//import the package here
var app = express();
// view engine setup
app.set('views', path.join(__dirname, '/wiki'));
app.engine('html', require('ejs').__express);
app.set('view engine', 'html');
//youcan implement the function used in the cache page here.
router.get('/*', function(req, res, next) {
res.type('html');
res.render('*');
});
//credit: https://blog.csdn.net/u011481543/article/details/79696565
node server.js
Save it to the server.js with the relative path and run

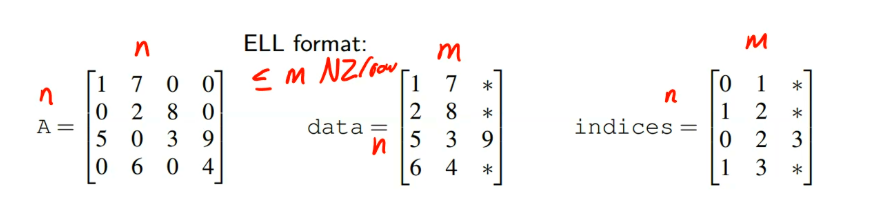
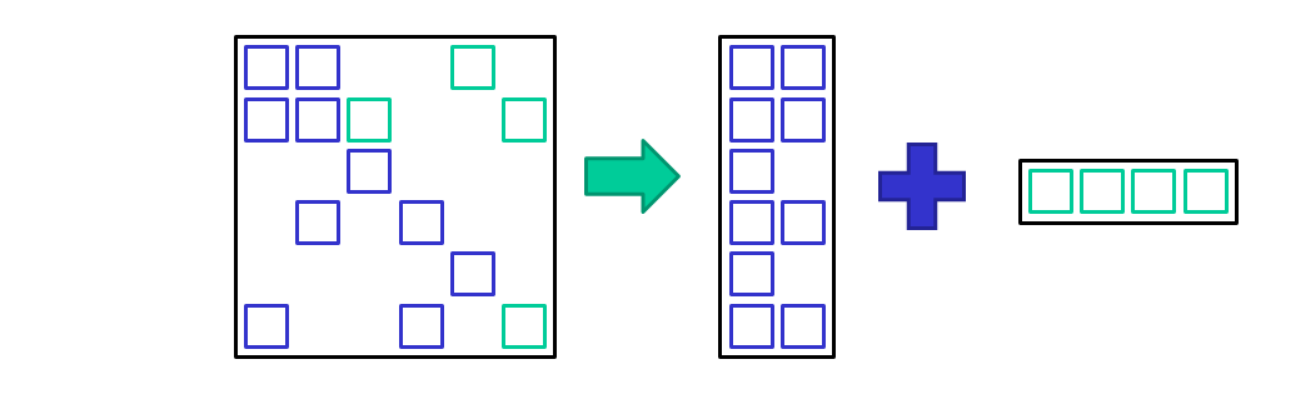
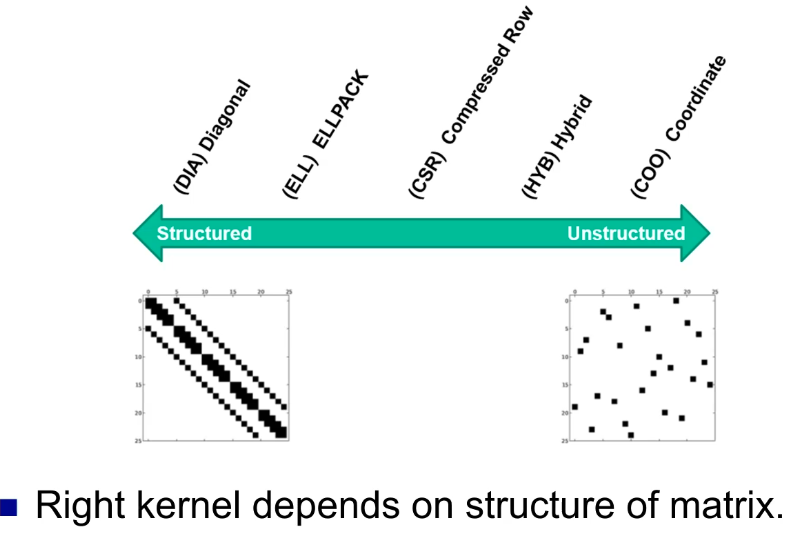
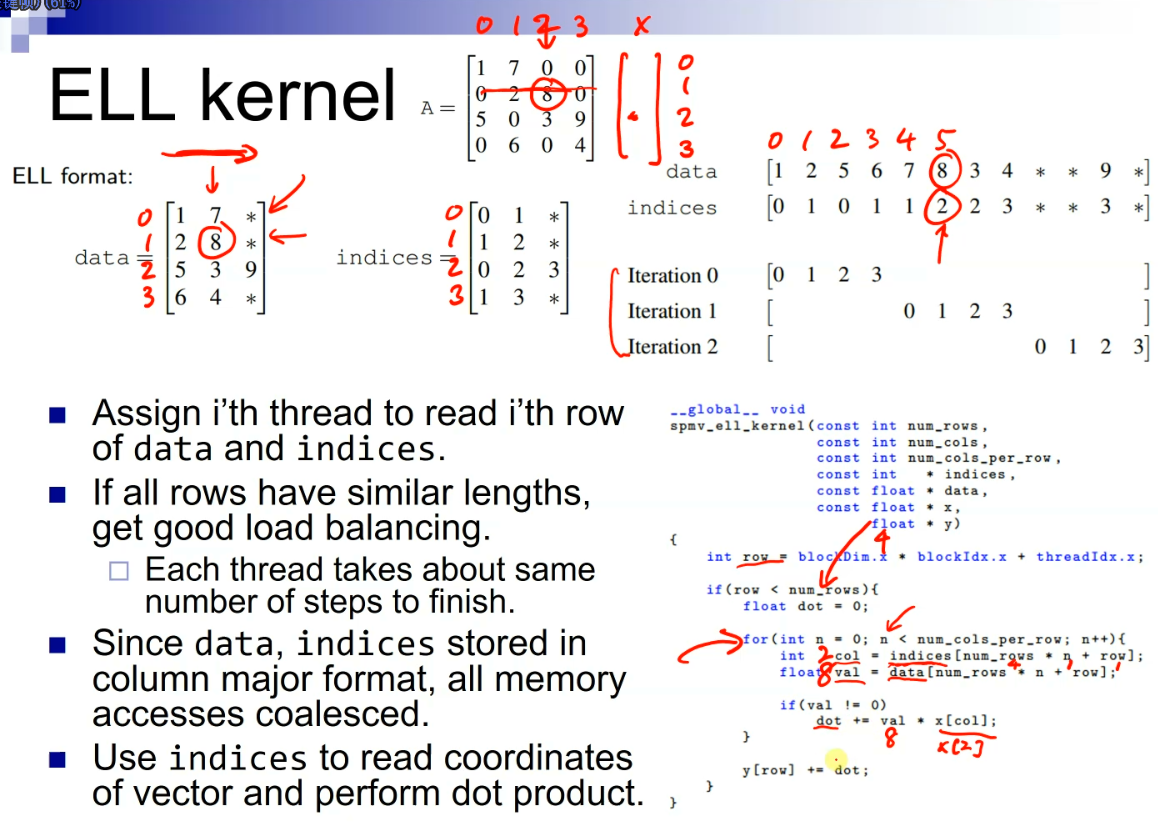
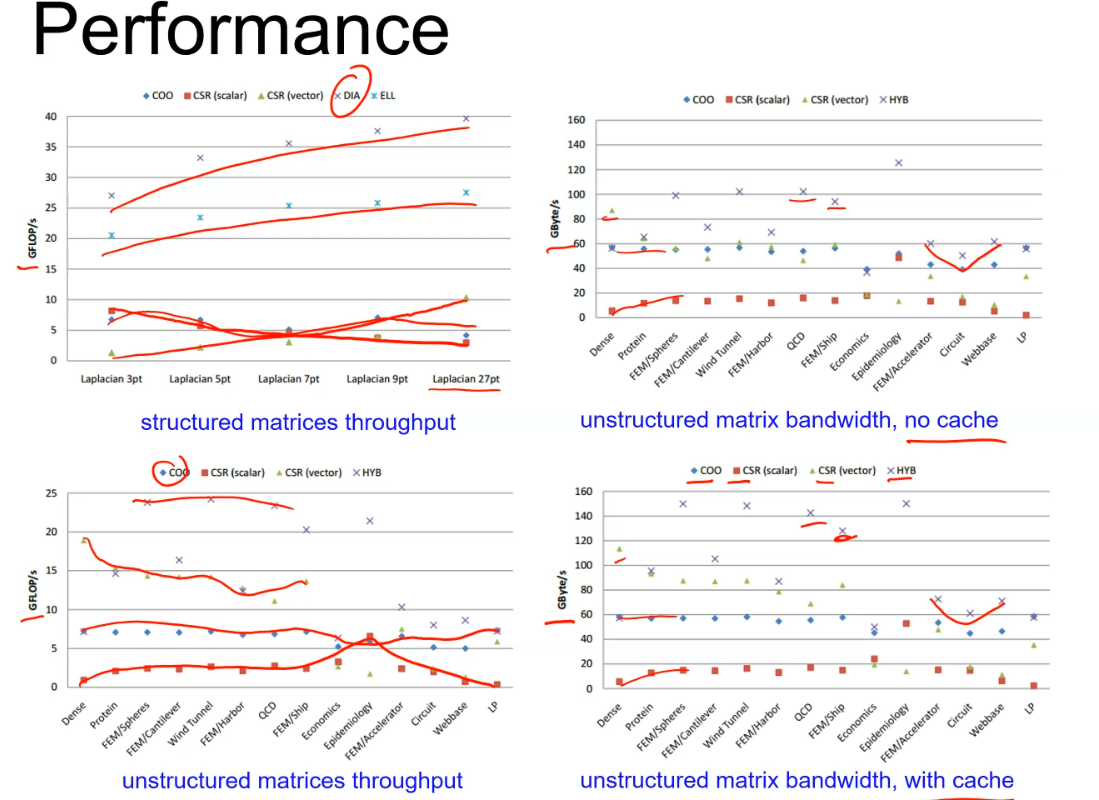
low degree mesh.), iterative methods (solving linear systems), eigenvalue methods (e.g. graph partitioning vx), simulations (e.g. finite elements), data analysis (e.g. Pagerank the web connectivity matrix).










Therac-25 radiation therapy system had a concurrency bug that led to radiation overdose and death of several patients.
Space shuttle aborted 20 minutes before maiden launch due to concurrency bug in its avionics software.
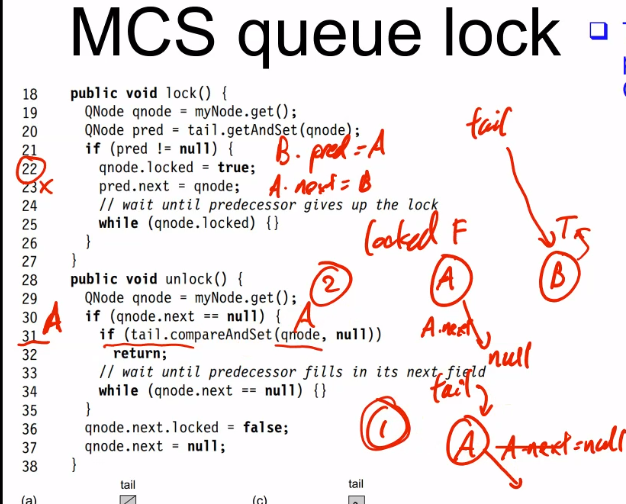
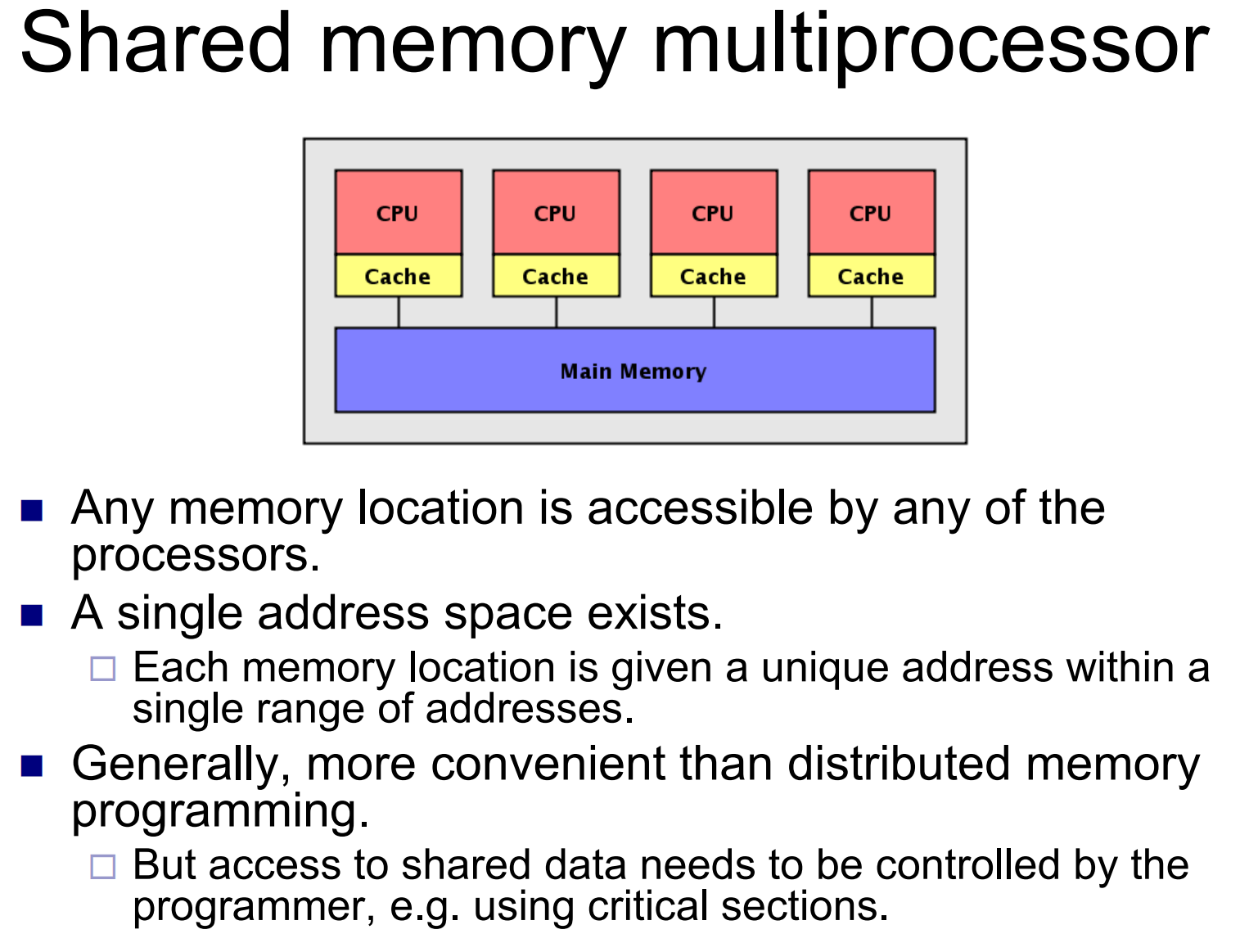
n concurrent processes that want to perform a critical section (CS), mutual exclusion can satisfy the following properties.

Reference: Cuda dev blog
Race condition: Different outcomes depending on execution order.
Race conditions can occur in any concurrent system, including GPUs.
GPUs have atomic intrinsics for simple atomic operations.
Hard to implement general mutex in CUDA.
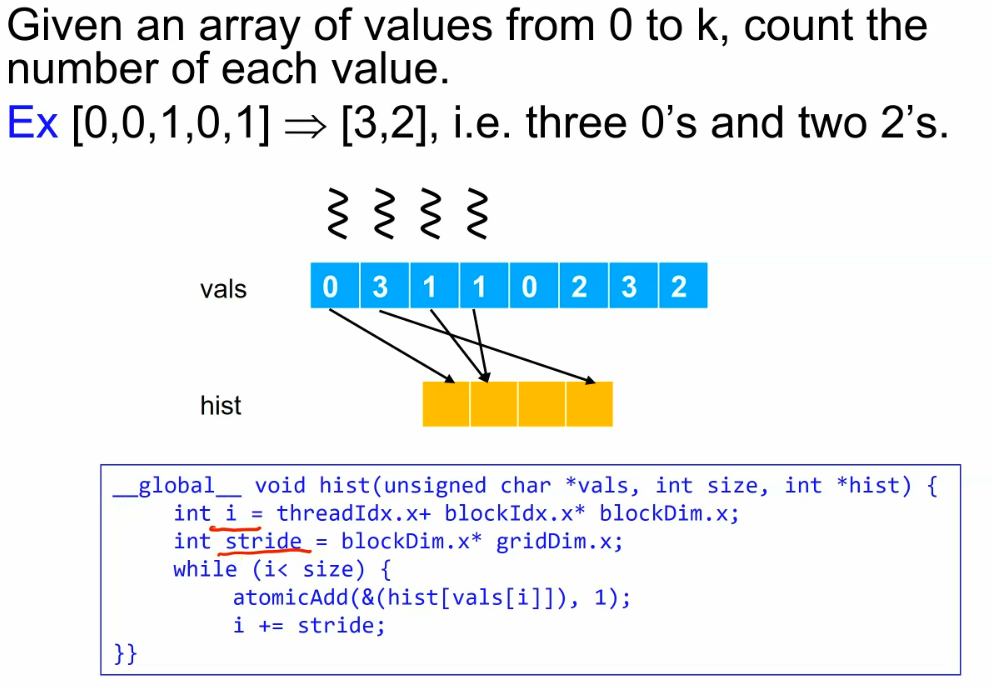
The atomic thread in critical section is not good in performance. The example is identified for variable d_a
Can perform atomics on global or shared memory variables.

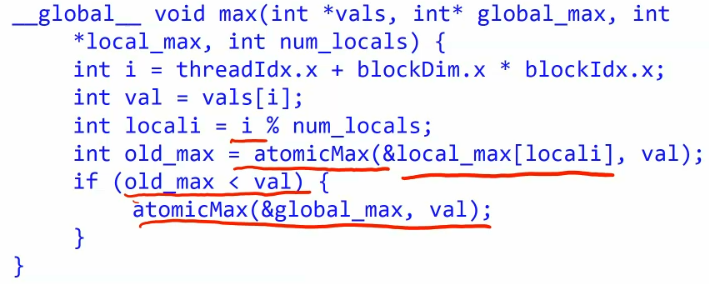
we can improve it bu split the single global max into num_locals number of local max value.
Thread i atomically maxes with its local max. can max the local_max[locali],

a better solution is to make it into the tree DS+CA
! whether the data is stored on shared or global memory is depend on programmers
! this intrinsic is not limited to cuda but all SIMD architecture
from avx256 vector elements we have
__m256 load_rotr(float *src)
{
#ifdef __AVX2__
__m256 orig = _mm256_loadu_ps(src);
__m256 rotated_right = _mm256_permutevar8x32_ps(orig, _mm256_set_epi32(0,7,6,5,4,3,2,1));
return rotated_right;
#else
__m256 shifted = _mm256_loadu_ps(src + 1);
__m256 bcast = _mm256_set1_ps(*src);
return _mm256_blend_ps(shifted, bcast, 0b10000000);
#endif
}
For Kepler architecture, we have 4 intrisics.
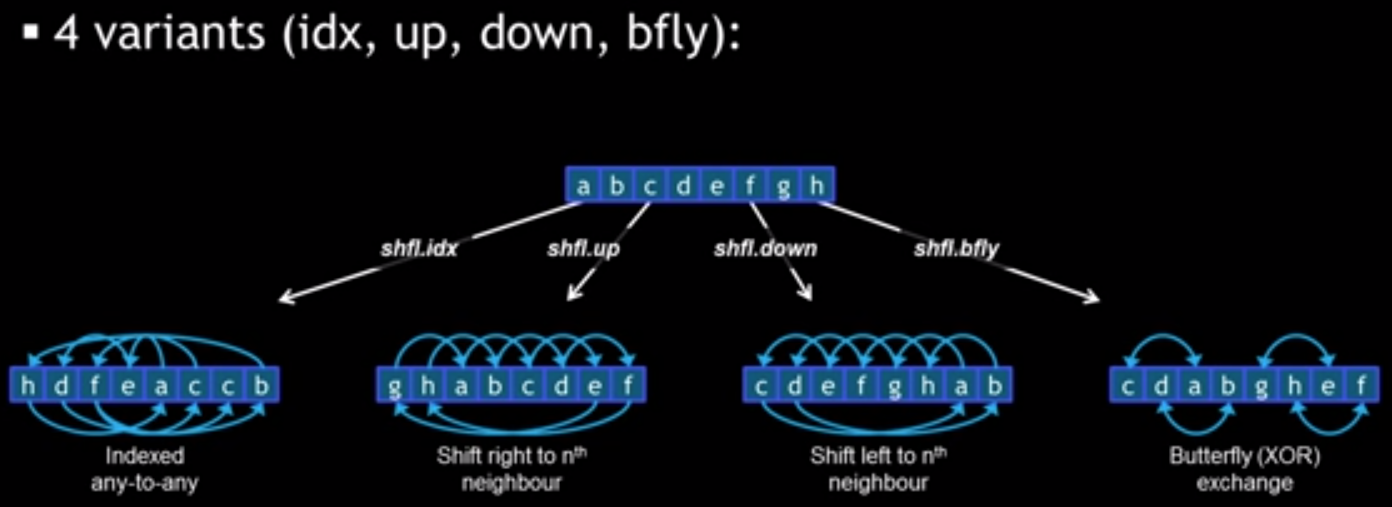
The goal of the shuffle intrinsics is actually for optimizing Memory-Fetch Model
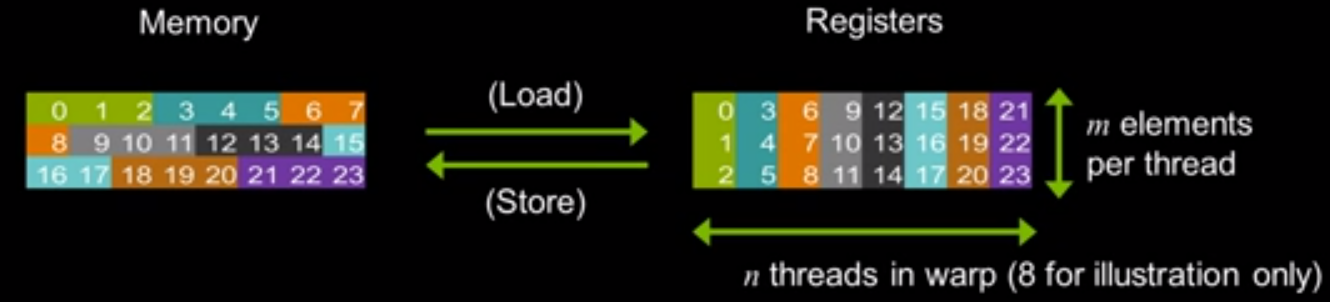


Assume we have at most shuffle instead of shared memory


Amdahi law defines the speedup formula after the parallelization of the serial system.
The defination of the speedup: \(Speedup = \frac{Time\ before\ optimized} {Time\ after\ optimized}\). The higher the speedup, the better the optimization.
Proof: The time after optimization: \(T_n=T_1(F+\frac1{n(1-F)})\), where \(T_1\) stands for the time before optimization, F is the percentage of serialized program,\((1-F)\) is the percentage of paralized program,n is the number of processor number. Take those into the equation we have \(\frac{T_1}{T_n}\),namely \(\frac{1}{(F + \frac{1}{n(1-F)})}\).
From the equation we can induce that the \(Speedup\) is inversely related with the \(F\). Also, from the equation, we can see that adding processor's number is just another method of providing \(Speedup\). Besides, lowering \(F\) can have the same effect.
For example in the \(ASC19\), besides merely applying the \(MPI\) parameter modification. The serialized part like initialization and special operation on the Qubits.
Gustafson is another important ways of evaluating the speedup rate
define the serialized processing time \(a\),parallelized processing time \(b\), namely single CPU situation, so the executing time \(a+b\) overall executing time \(a+nb,\) n denotes CPU number.
define the propertion F of a out of the executing time \(F=\frac{a}{(a+b)}\)
we get the final speedup rate. \(s(n)=a+\frac{nb}{a}+b=\frac a{a+b} + \frac{nb}{a+b} = F + \frac{n(b-a+a)}{a+b }= F + n(1-F)\)
From the equation, we have if the serialized part is tiny enough, $s(n) equals to the number of the CPU, so reducing the serialized part make sense, as well as adding the CPU core.
Two different law treats the parallel program from 2 different angles. Amdahi said that when the serial ratio is fixed, there is an upper limit by adding a CPU. By reducing the serial ratio and increasing the number of CPUs, the acceleration ratio can be improved. Gustafson is saying that when serial comparison tends to be very small, it can be seen from the formula that adding cpu can improve the speedup ratio
Because of the inconsistency and security of data in a multi-threaded environment, some rule-based control is required. Java's memory model JMM regulates the effective and correct execution of multi-threading, and JMM is precisely the atomicity, visibility, and Orderly, so this blog introduces some multi-threaded atomicity, visibility and order.
For single-threaded, it is indeed atomic, such as an int variable, change the value, it is the value when reading, this is very normal, we go to the system to run, it is also the same, because our operation Most of the system is 32-bit and 64-bit, int type 4 bytes, that is, 32-bit, but you can try the value of long type, long type is 8 bytes, which is 64-bit, if both threads Read and write it? In a multi-threaded environment, a thread changes the value of the long type and then reads it. The obtained value is not necessarily the value just changed, because your system may be 32-bit, and the long type is 64-bit. Yes, if both threads read and write to the long type, this will happen.
How to understand visibility? First of all, there is no visibility for single-threaded. Visibility is for multi-threaded. For example, if one thread has changed, does another thread know that the thread has changed, this is visibility . For example, the variable a is a shared variable. The variable a on cpu1 is cache optimized, and the variable a is placed in the cache. At this time, the thread on the other cpu2 changes the variable a. This operation is for cpu1. The thread is not visible, because cpu1 has been cached, so the thread on cpu1 reads the variable a from the cache, and found that the value read on cpu2 is not consistent.
For single-threaded, the code execution of a thread is in order, which is true, but in a multi-threaded environment may not be necessary. Because in a multi-threaded environment instruction rearrangement may occur. In other words, in a multi-threaded environment, code execution is not necessarily ordered.
Since disorder is caused by rearrangement, then all instructions will be rearranged? of course not. The rearrangement follows: Happen-Before rule.
余乃一介草民,最近要写文章,回顾以前的文章,有所感。高中时每每写及作文时,大概都添加了我对家庭,我对社会的看法。我出生在一个科技、理性,不逐利、仓廪实的家庭。当时的语言表达随常常词不达意。但却是时至今日我的人生哲学。
找到痛苦的幸福
周国平在复旦做了一场《生活的幸福》演讲,座次一位嘘声,自诩貌美有才,家庭美好,成绩优异,却无法得到幸福。
幸福不是一种没有痛苦的状态。
由于当时我挺喜欢这句话的。我讨厌这种秀优越感却实际上什么都不自知的人,但有时候自己却是这样的。我感激我的家庭给我带来的视野、高度。这使得当时我对很多“文青”嗤之以鼻。无所适从到想对他们口诛笔伐。我少了一种装逼的想法,同时有些自卑,因为我成绩就是不如同班同学,无论我多么努力。也许是能力不够吧,或者想要的太多。所以我内心还是非常自卑的,想通过“看不上别人”,来得到自身的慰藉。
我对这篇文章大体的想法是想写成与自己的对话。如果自己已经感受到世俗意义上的幸福了,是否应该皈依痛苦,再从痛苦中寻找自我的价值。
周国平这句话实际上也是一种放大性的解读。痛苦不是幸福的对立面。或许有时候进入痛苦也能得到幸福,不痛苦也可以幸福。这对很多文青来说就是他们的发挥空间了。比如这种痛苦可以是找寻西绪福斯般的“有痛苦却很幸福”,最终找到痛苦也很幸福。然后再辅以华丽的与评卷老师会心的想法。便可以得到不错的分数。
当时我刚从伯克利回来没多久,是一次高二上的月考。同时接触很多家里有钱,同时又很优秀,最后不乏申上伯克利计算机的一些同学,这种人的人物肖像就是口上说的都是满满的资源。所以我将这位同学带入了他们。他们其实很幸福,可以一天换一个女友。想象王思聪。我开始了我的骂战。我同时还想到了当时的“航母”,即通过每天网上学习学到3点的女生,最后考上了清华新亚书院。我说,不要那么为了幸福而痛苦。还有就是我的不作为的母亲和不作为的语文老师。若是母亲给力一点。若是语文老师给力一点。我会好走一点。
我引经据典,告诉他们所谓的“小有成就”在明清时的夜航船上就有很多自吹自擂最后落得自己“一无所知”的下场。得到四书五经的真传又如何?这种将八股奉为圭臬,陷于自己的舒适区的人,实则仅得到孔孟程朱的边角料,闹得只会对对联这种恶俗文青操作。没有真正意义上的创新 ,也即是把自己放在舒适区的结果。当时的中国没有进步,人均生产一直维持在低点千年的原因莫过于此。我们放弃了“科技”,而沉浸于古人的辉煌。
人需要痛苦,需要痛苦去圆满充实人生,从而造福社会。
我想说,人是要有家国情怀的。您那些幸福不过是屁民想的屁事。仓廪实则需关注民生,自己痛苦,谋求全社会的幸福。
一个聪明人最容易想完人生,感觉人生就那样,做好分内之事,何必痛苦呢?于是每天拘泥于自己的小确幸中,如“龙应台”之流,这是“平庸之恶”。那位学生应把自己的所谓的财力投入自己的“痛苦”,走出舒适圈。而不应像儒士一样没有眼光。它因转化为力量,造福人类。
两个例子,一正一反。古巴银行行长切格瓦拉和傻逼王思聪。
炮轰没有幸福的人,没有痛苦的人。
“人需寻得所爱。”乔帮主用这句话结束给“世界大脑”们的演讲,意在说明人总能找到属于自己的价值,为之痛,为之乐。这份痛是带有主观判断的。不能麻木盲从地痛苦下去,折磨自己很简单,但绝不能陷入琐事的痛苦,不能让片面庸俗的痛苦成为成就高水平幸福的绊脚石。史铁生一生“埋没”在病痛痛苦的极致中,却在地坛公园中给全中国人民在文革后以生命意义的慰藉。苏轼成长之路世人皆知,从青年到老年的跃变,从无法摆脱对时弊的束缚到无以伦比的胸襟。他突破了苦的边界,为百姓疾苦共舞。他的幸是 苦叠加的结果。相反万历朱翊钧倒在了臣子阴阳利益斗争的血泊和三征高丽的痛苦中,失了心智,未能续大明之幸,张居正之托,终享其乐。
我这段话想说的就是有意义的高层次痛苦能带来更高层面的幸福。
找到痛苦后的幸福,是一种磨砺,更是一种蜕变。人不能简单满足现有的条件,而更应想着如何转化条件为更高层面的幸福。高层次的幸福就是家国之幸。同时,幸福不是简单盲目的,而是要有判断与取舍。
我的人生哲学尽如此。从不断的痛苦和打击之下历练自己。我要学技术,会管人。有自信。把“家国之幸”作为己任,修身齐家治国平天下。我不会做我眼中的小人,我妈,我的高中语文老师,liujingwen,还有那帮留学生们。我会为自己的意义奋斗终身,为祖国健康工作50年。
说说这篇文章为啥是三类下卷,即得了44/70. 大致上是偏题了,而且用词朴素,没啥料。好像老师看上去没有同感,或者说根本懒得读。还有,周国平在哪里?
这是一个17岁的少年在仅剩30分钟完卷的内心独白。我不适合被动的学习。从这以后我都是很主动的,从本被父母拉着出国(我认为是一个叛逃者),到作为一个合格的高考生。我或许在当时就应该认识到差距,可我被自己外表自大,内心自卑的性格所麻痹,认为经过努力,一定能得到属于我的一片天地。可事实是,语文老师不理解我的心思。
我挺喜欢读当时的那些文青的,现在估计转市场?学法律?抑或学经济了。我人对他们嗤之以鼻。我认为那个时候的作文,在我们的语文老师的渲染下变成了一种文青交流的乐园。
我的人生阅历太少,当时的阅读也少,之后读了挺多东西的,但鲜少能总结成文字。也会写书评,但得不到赞赏。我很少会对自己能力提升无济于事的事多努力,大概我一开始就认定那些人写的东西不值一提了吧。
鸢(yuān)飞戾(lì)天者,望峰息心;经纶(lún)世务者,窥(kuī)谷忘反。——《与朱元思书》
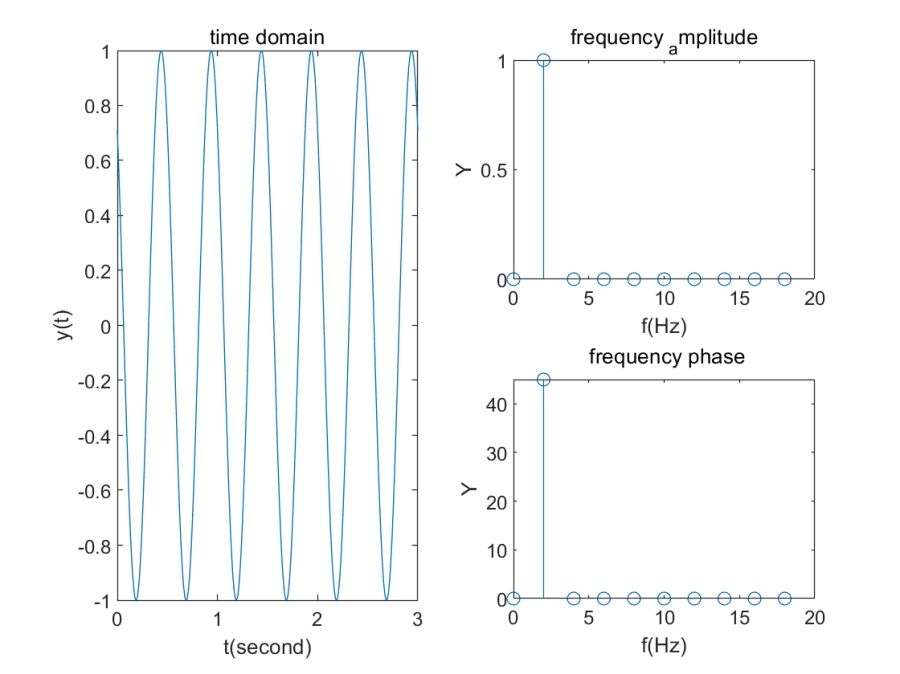
clear;clf;
syms t;
f=2;T=1/f;t0=0;
A=1;
%ft=A*sin(2*pi*f*t);
ft=A*cos(2*pi*f*t+pi/4);
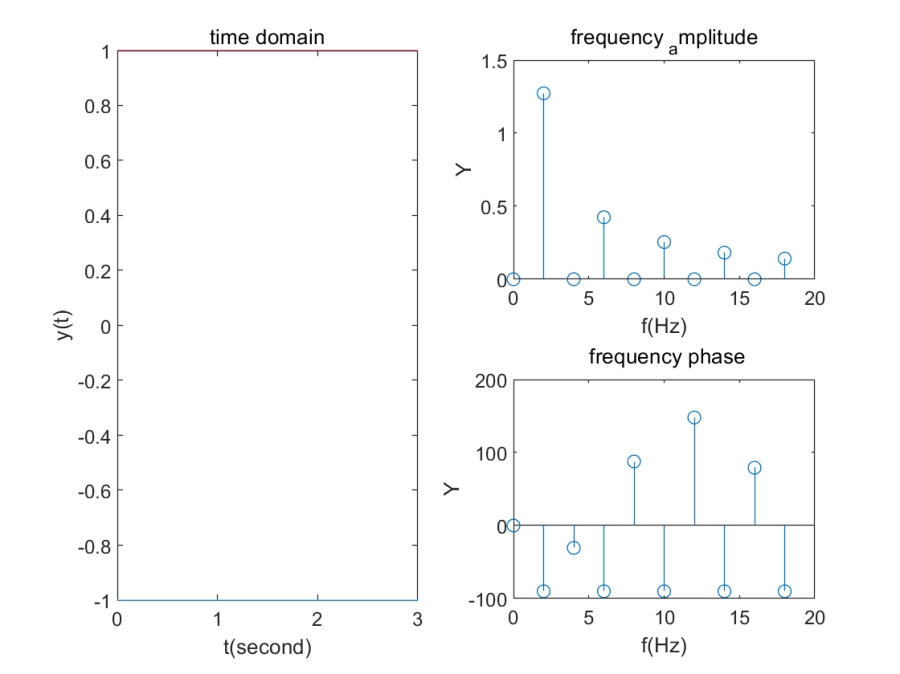
subplot(2,2,[1,3]); fplot(ft,[0 3]);title("time domain" ); xlabel( 't(second)');ylabel( 'y(t)' );
w = 2*pi*f;N =10;
Fn = zeros(1,N);
Wn = zeros(1,N);
for k = 0:N-1
Fn(k+1) = 2*1/T*int(ft*exp(-1j*k*w*t),t, [t0, t0+T]);
Wn(k+1) = k*w;
end
subplot(2,2,2); stem(Wn/ (2*pi),abs(Fn));title('frequency_ _amplitude' ); xlabel('f(Hz)' );ylabel('Y');
subplot(2,2,4); stem(Wn/ (2*pi),angle(Fn)*180/pi);title(' frequency_ phase'); xlabel('f(Hz)' );ylabel('Y')
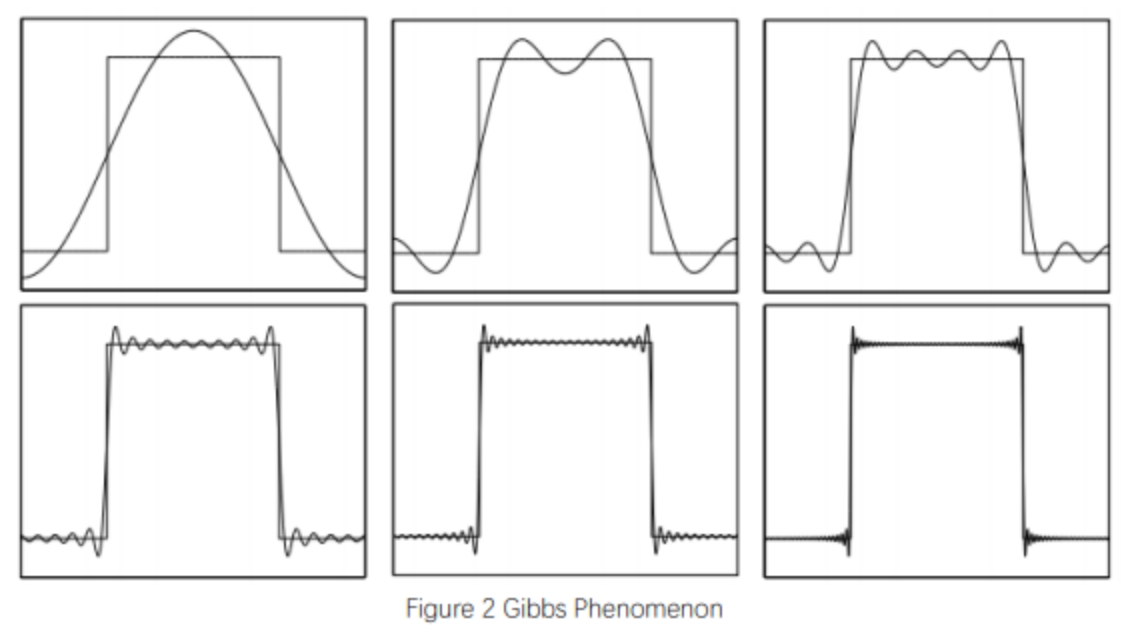
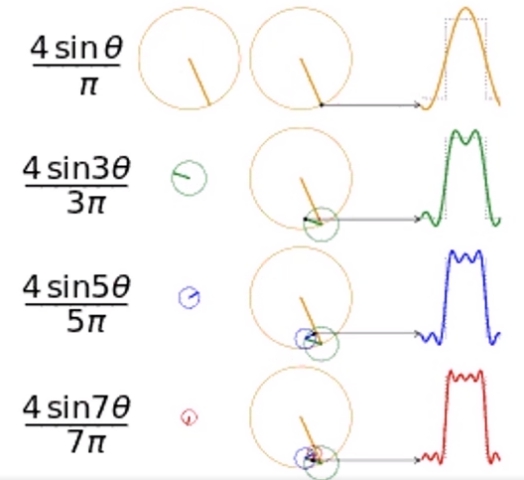
实际上方波信号也是三角函数的加和,可以从复频图中看出。
clear;clf;
t=0:0.01:3;
f=2;T=1/f;t0=0;
A=1;
%ft=A*sin(2*pi*f*t);
ft=square(2*pi/T*t);
subplot(2,2,[1,3]); fplot(ft,[0 3]);title("time domain" ); xlabel( 't(second)');ylabel( 'y(t)' );
w = 2*pi*f;N =10;
Fn = zeros(1,N);
Wn = zeros(1,N);
for k = 0:N-1
fun=@(t) square(2*pi/T*t).*exp(-1j*k*w*t);
Fn(k+1) = 2/T*integral(fun,t0,t0+T);
Wn(k+1) = k*w;
end
subplot(2,2,2); stem(Wn/ (2*pi),abs(Fn));title('frequency_ _amplitude' ); xlabel('f(Hz)' );ylabel('Y');
subplot(2,2,4); stem(Wn/ (2*pi),angle(Fn)*180/pi);title(' frequency_ phase'); xlabel('f(Hz)' );ylabel('Y')
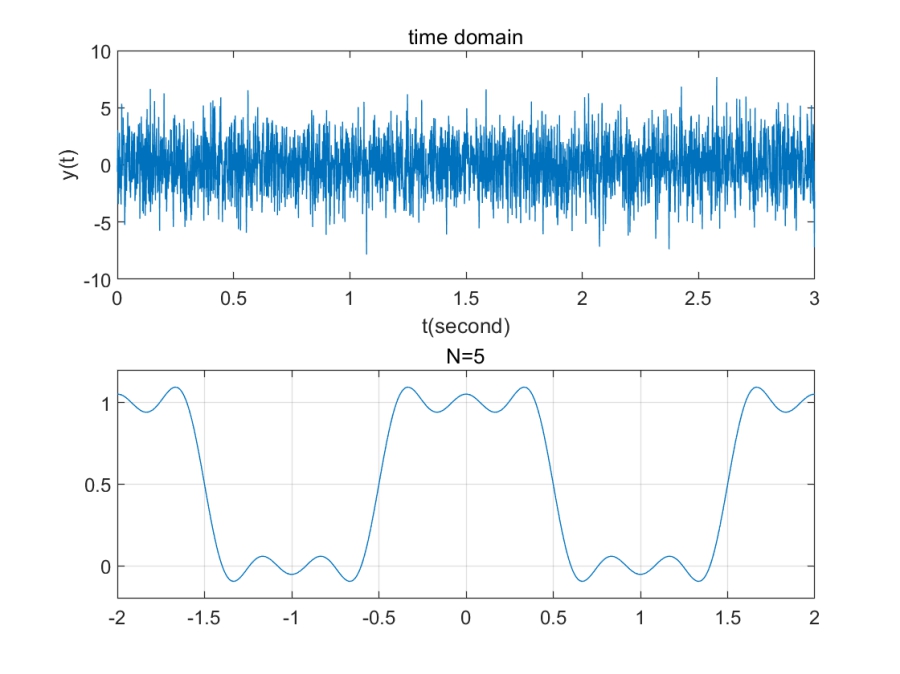
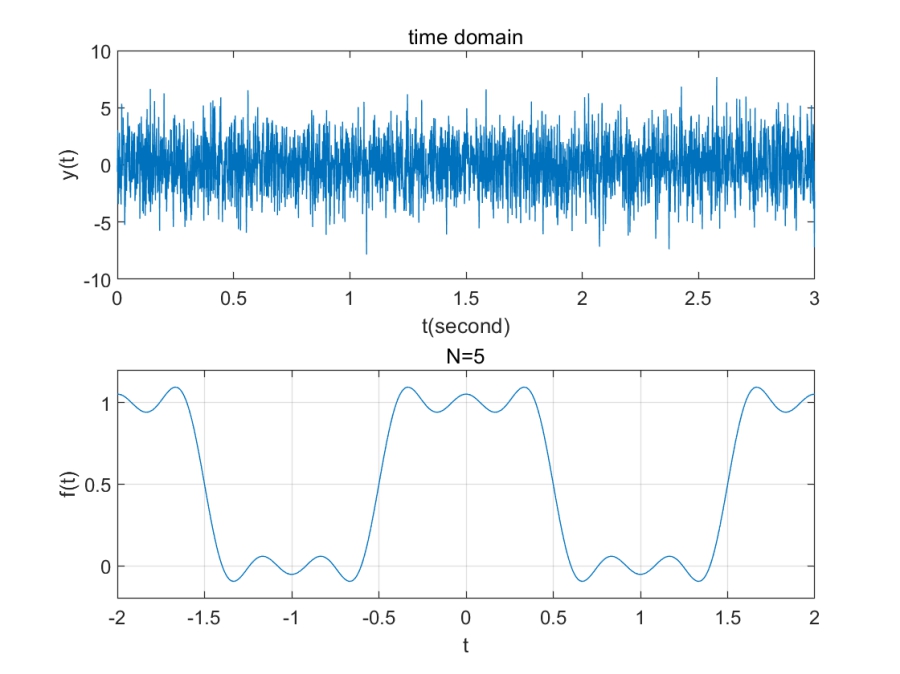
clear;clf;
Fs = 1000;
ts = 1/Fs;
N = 3000;
t = (0:N-1)*ts;
signal1 = 0.7*sin(2*pi*50*t)+sin(2*pi*120*t)+2*randn(size(t));
subplot(2,1,1);plot(t,signal1); title('time domain'); xlabel('t(second)');ylabel('y(t)');
Y = fft(signal1);
Y = abs(Y/N);
Y = Y(1:N/2+1);
Y(2:end) = 2*Y(2:end);
f = (0:N/2)*Fs/N;
subplot(2,1,2);plot(f,Y); title(' frequency domain' ); xlabel('f(Hz)');ylabel('Y');
 一种看时域图的角度
一种看时域图的角度
t = -2:0.001:2;
N = input('N=');
a0 = 0.5;
f = a0*ones(1,length(t));
for n=1:2:N
f = f+cos(n*pi*t)*sinc(n/2);
end
plot(t,f);grid on;
title(['N=' num2str(N)]);
xlabel('t');ylabel('f(t)');
axis([-2,2,-0.2,1.2])
t = -2:0.001:2;
N = input('N=');
T1 = 2;
w1 = 2*pi/T1;
fun = @(t) t.^0;
a0 = 1/T1*integral(fun,-0.5,0.5);
f = a0;
an = zeros(1,N);
bn = zeros(1,N);
for i = 1:N
fun = @(t) (t.^0).*cos(i*w1.*t);
an(i) = 2/T1.*integral(fun,-0.5,0.5);
fun = @(t) (t.^0).*sin(i*w1.*t);
bn(i) = 2/T1.*integral(fun,-0.5,0.5);
f = f + an(i)*cos(i*w1.*t)+bn(i)*sin(i*w1.*t);
end
plot(t,f); grid on;
title(['N=' num2str(N)]);
axis([-2 2 -0.2 1.2]);