






A Tech Nerd with a finance mind.
bios:顺序一定要让centos 先。超微主板的flexyboot 一定要disable 否则就会像这次一样卡死。
开机自启服务:
其他都可以再开机以后做,所以无所谓。
再看下ht开没开。nvidia-smi 在不在。内存有没有掉。
超微为了减少功耗是可以热插拔pcie 的,因为显卡插着就有25w功耗,热量积攒就算不用也会上升到平均30w左右。所以开机看看能不能热插拔。
最后总之能不重启就不重启。
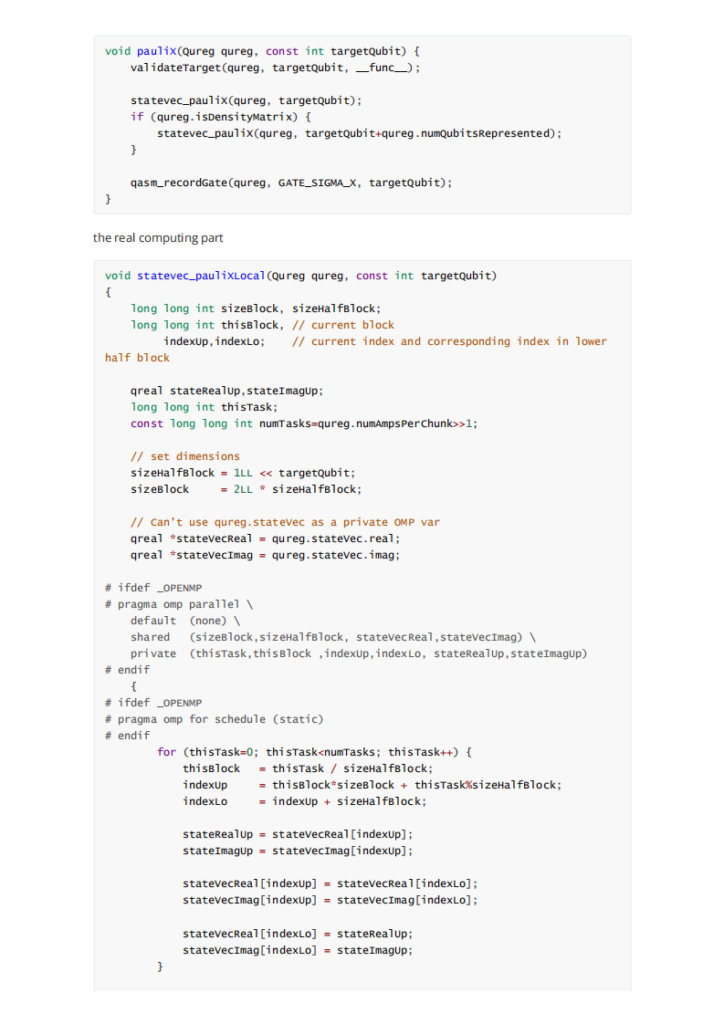
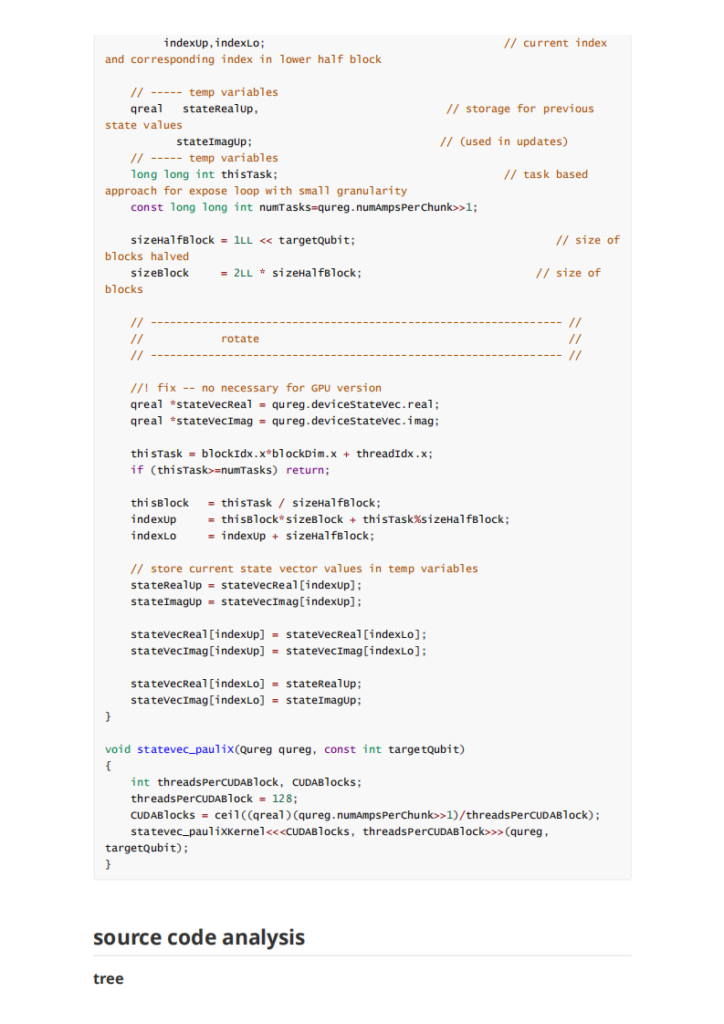
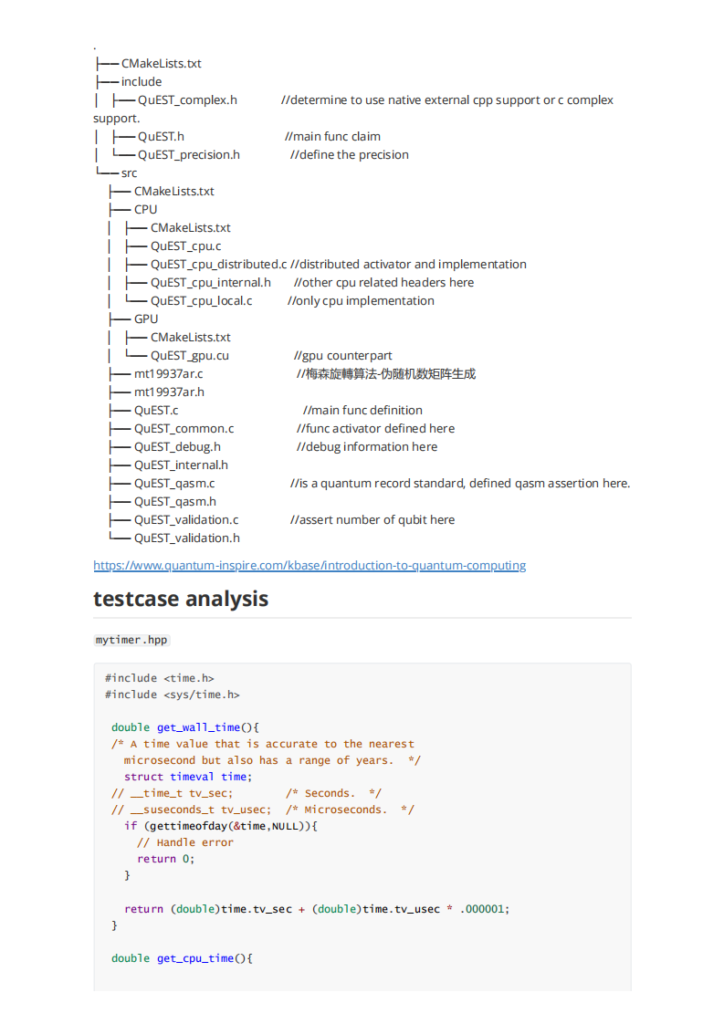
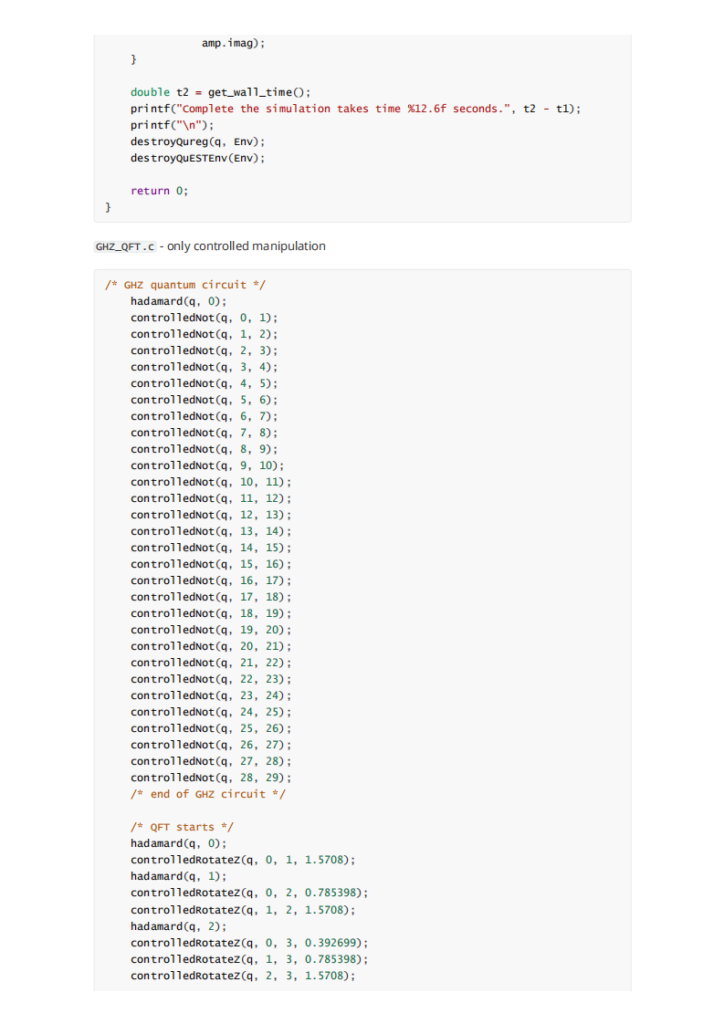
我们在开科学计算的选项的时候总是会碰到这种问题:内存如何分配。尤其是用到gpu的计算的时候。很难有减少内存传输overhead 的办法。正如这次asc quest题目作者所说的:
Firstly, QuEST uses its hardware to accelerate the simulation of a single quantum register at a time. While I think there are good uses of multi-GPU to speedup simultaneous simulation of multiple registers, this would be a totally new pattern to QuEST's simulation style. So let's consider using multi-GPU to accelerate a single register.
There are a few ways you can have "multiple GPUs":
作者没有实现distributed gpu的主要原因是他觉得显存带宽复制的时间overhead比较大。不如就在单gpu上完成就行了。但是未来随着gpu显存的不断增加和计算的不断增加,这个放在多卡上的需求也与日俱增。
翻了很多关于gpu显卡的通讯,无论是单node 多卡还是多node多卡。最绕不开的就是mpi。但是当我找到一个更优秀的基于 infiniband 网卡的rdma的数据共享协议,让我眼前一亮,决定就用这个。如果你不是要写cuda 而是pytorch 请绕步pytorch distributed doc,如果是python 版本的nccl 可以选择
参考文档:
主要的步骤:先照着nccl文档安装nv_peer_memory, 再装nccl 最后装plugin。
安装后之后有两个test 一个是 gdrcopy 另一个是 nccl-tests。 跑的命令是 mpirun -N 1 --allow-run-as-root --hostfile host -x NCCL_IB_DISABLE=0 -x NCCL_IB_CUDA_SUPPORT=1 -x NCCL_IB_HCA=mlx4_0 -x NCCL_SOCKET_IFNAME=ib0 -x LD_LIBRARY_PATH=/usr/local/nccl/lib:/usr/local/cuda-10.0/lib64:$LD_LIBRARY_PATH -x NCCL_DEBUG=INFO ./build/all_reduce_perf -b 16M -e 1024M -g 4
MPI 对于消息传递模型的设计
在开始教程之前,我会先解释一下 MPI 在消息传递模型设计上的一些经典概念。第一个概念是通讯器(communicator)。通讯器定义了一组能够互相发消息的进程。在这组进程中,每个进程会被分配一个序号,称作秩(rank),进程间显性地通过指定秩来进行通信。
通信的基础建立在不同进程间发送和接收操作。一个进程可以通过指定另一个进程的秩以及一个独一无二的消息标签(tag)来发送消息给另一个进程。接受者可以发送一个接收特定标签标记的消息的请求(或者也可以完全不管标签,接收任何消息),然后依次处理接收到的数据。类似这样的涉及一个发送者以及一个接受者的通信被称作点对点(point-to-point)通信。
当然在很多情况下,某个进程可能需要跟所有其他进程通信。比如主进程想发一个广播给所有的从进程。在这种情况下,手动去写一个个进程点对点的信息传递就显得很笨拙。而且事实上这样会导致网络利用率低下。MPI 有专门的接口来帮我们处理这类所有进程间的集体性(collective)通信。

其中双缓存的概念在asc20 hpl优化的时候得到了验证,4*teslav100=32g =128g,内存占用也是128g。实际上host 到device 的带宽太小,不适合做大规模的内存迁移,所以双缓存还是十分必要的。

gpu的延时是数百个时钟周期。


sm资源调度模型用于解决访存冲突。有texture 纹理寻址。
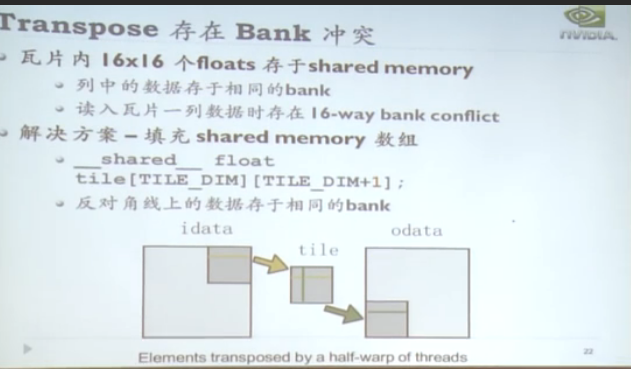
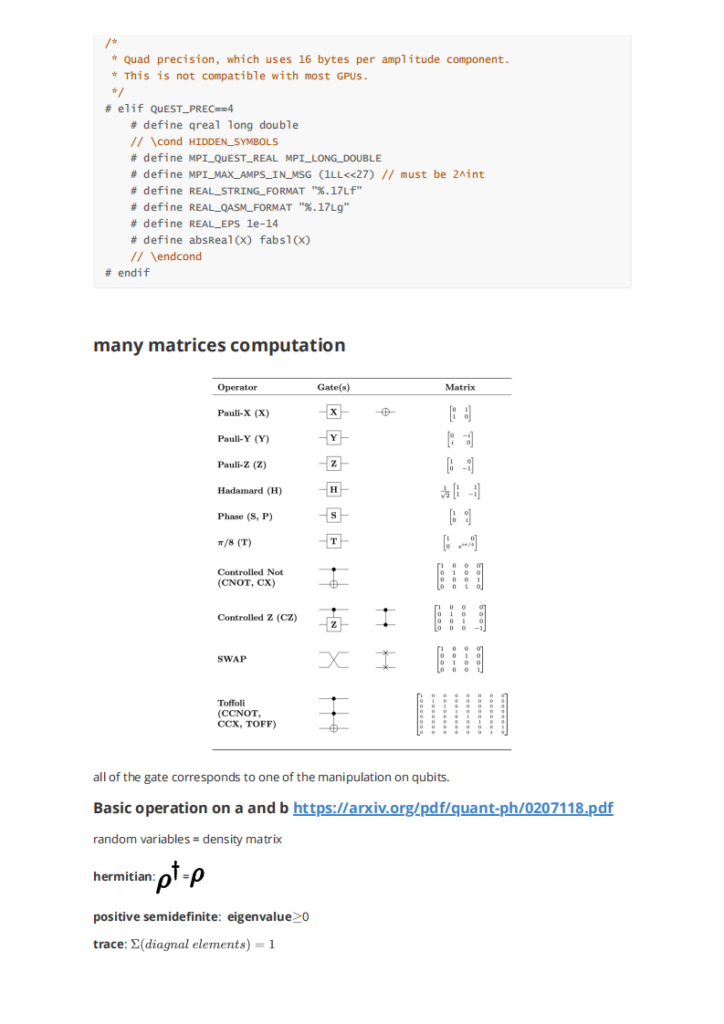
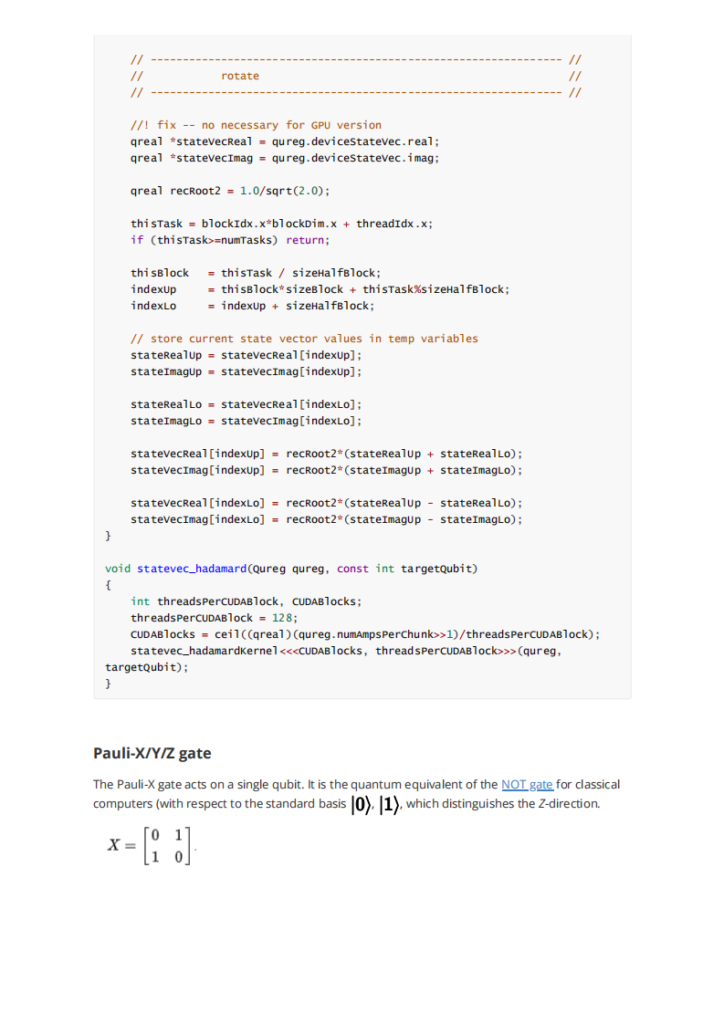
基本操作:

另外几种优化的方向。
single转double

Data Prefetching 数据预读

引入预读操作

编译器bb优化


类似SIMT中的线程,被serialized。很多特性和线程几乎一致。在host中经常被用到的概念,也是区别block的基本单位。
一个block 不是最小单元,最好的优化是在warp上调度,warp的步调是一致的。
P.S. 尽量不要写过多的深层的递归,因为在gpu上实现这个是需要开指数级别的线程数,没开一个线程就意味着特定的内存开销,显存很容易被撑满。

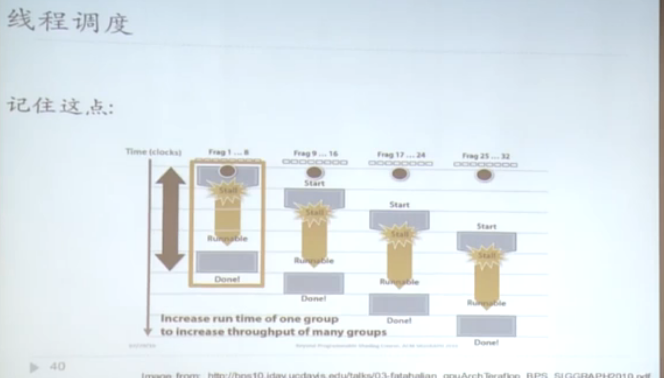
用线程调度的方法来达到延时隐藏的效果,对于gpu的warp来说,context switch 的开销几乎为零。在特定的时间点只可能一个warp在执行。
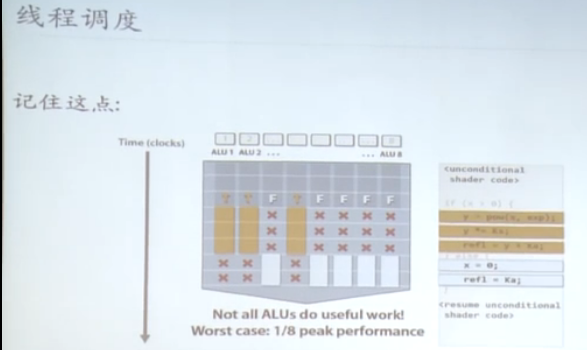
如果warp内部线程沿不同的
# 需求:将列表中的元素按其平方进行排列
li = [3,5,-4,-1,0,-2,-6]
sorted(li, key=lambda x: x^2)当然,也可以如下:
li1 = [3,5,-4,-1,0,-2,-6]
def get_square(x):
return (x^2)
sorted(list1,key=get_square)充分显示了其 PEP
Explicit is better than implicit
的特点
“Talk is cheap. Show me the code.”
–Linus Torvalds
之前是网断了,回机房插拔了一下就搞定了。
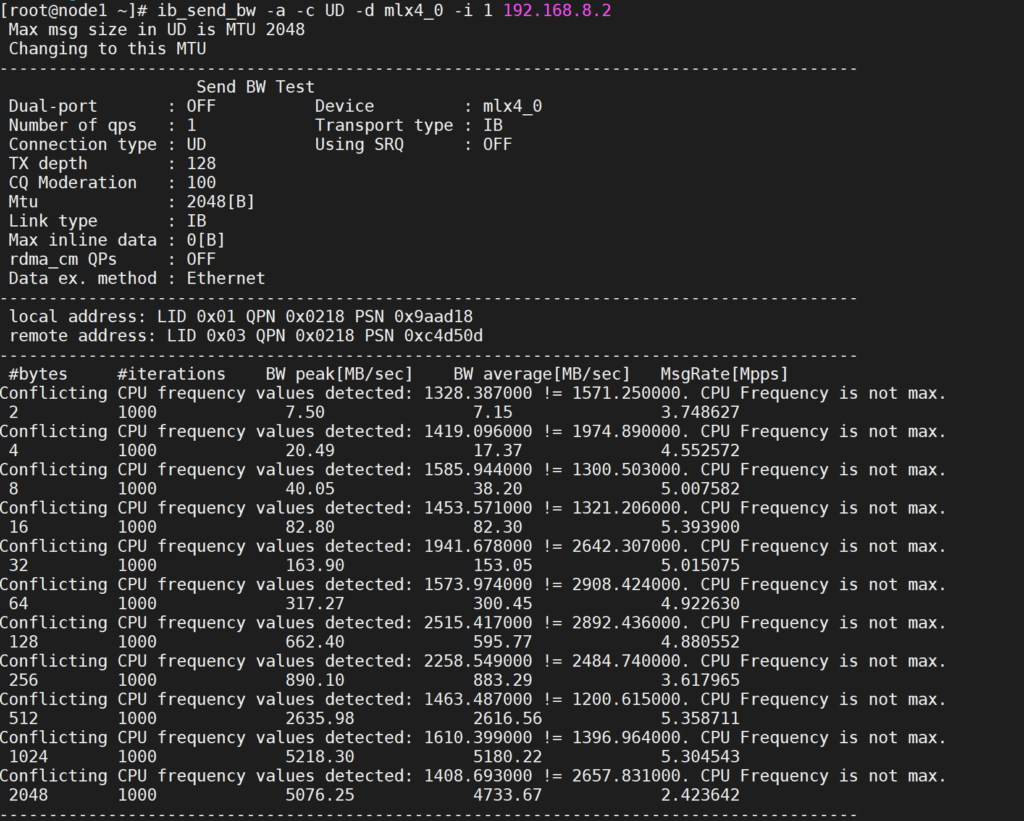
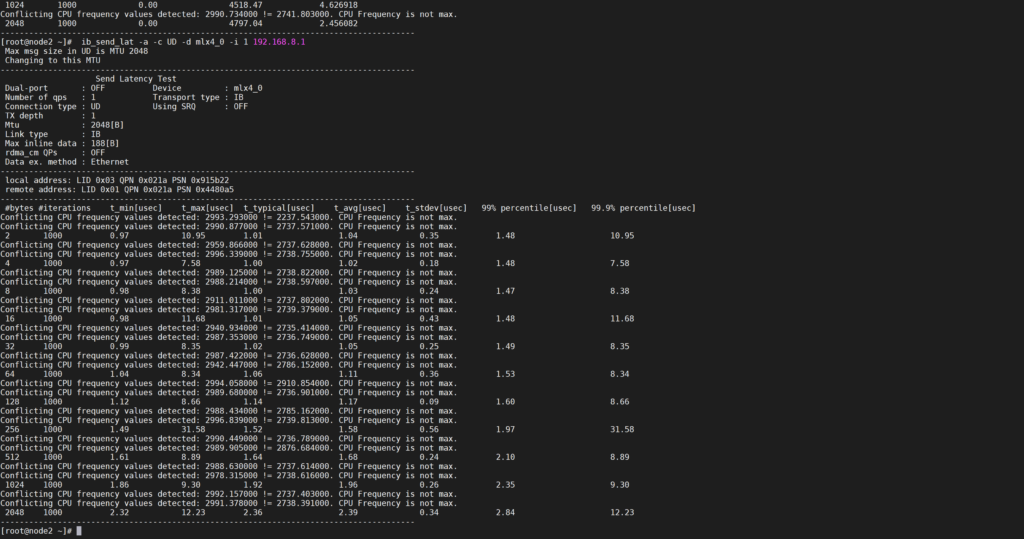
56Gbps延时是毫秒级别的!!