All the modified code and raw result is https://github.com/masc-ucsc/esesc/commit/2763f4c52351e9c9233b67beb245dd4c8d39c5ed and modified code reside the last 3 commits.
Basic Idea of Improving the IPC
Since the workload I'm using is a RISC-V simulator and an in-memory database, it highly requires the prefetcher that has awareness of page prefetcher.
Comparison between different prefetcher
Stride Prefetcher and TAGE Prefetcher have already been implemented in esesc and achieved great performance, but they still failed to fetch if the semantic of cacheline is within page level. Say the application malloc and do a pattern within the page level, and the SPP Prefetcher will win.
Base Offset Prefetcher(contains Stride/NextLine)
- 1-degree prefetcher (only prefetch 1 address)
- Prefetch 2 offset results in many useless prefetches
- Normally fetch the next line or stride semantic prefetcher.
- Turn off the prefetcher if the performance is too low.(stride or next line will not do so)
- MSHR threshold varied depending on BO score and L2 access rate
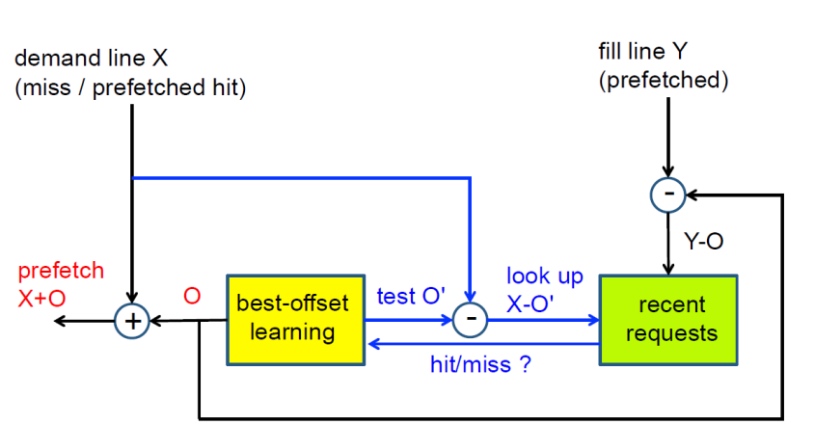
SPP Prefetcher
Basically maintained 3 tables, a Signature Table that records the page, a Pattern Table that records the specific page with what kind of pattern, and a Global Register History to enable possible cross-page ref.
Design Doc
the esesc implemented Prefetcher only takes place in a single hierarchy. So I inserted SPP into the member variable of GMmemorySystem. If the CCache is named L2(0) or DL1(0), I passed the SPP in. So that I could record all the down req for DL1, calculate the SPP result, and once entered L2(0), I consume all the addresses stored in SPP and schedule the prefetch.
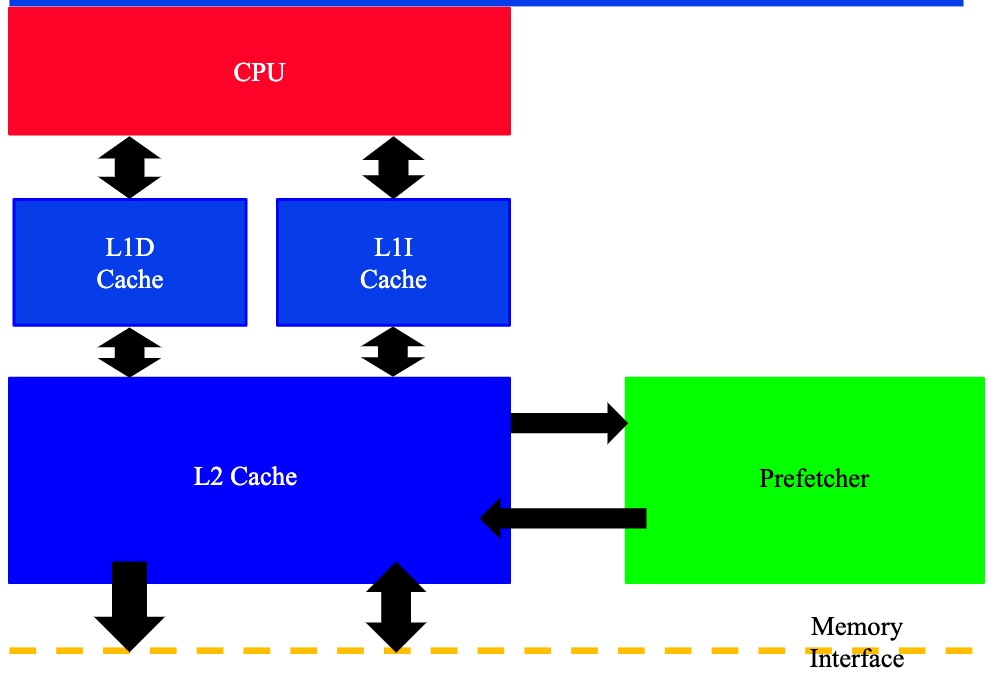
Associative size for replacing policy cast on the vector<Entry*> and unordered_map<Entry*, int>. Use AssocSet with vector and unordered_map of the address to implement the 1 assoc, 1 entry size replacement policy.
-
Table update
- The offset that corresponds to a page's signature will be updated when DL1(0) accesses it.
- The previous signature is utilized to alter the pattern table while the offset difference (delta) is used to construct the new signature.
- The offset that corresponds to a page's signature will be updated when DL1(0) accesses it.
-
The signature will match the design.
- Shorten training sessions and PT store visits
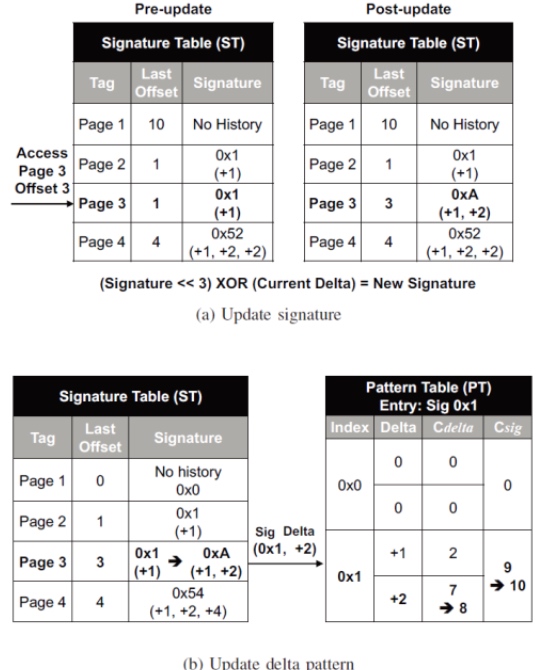
- Shorten training sessions and PT store visits
-
Prefetching
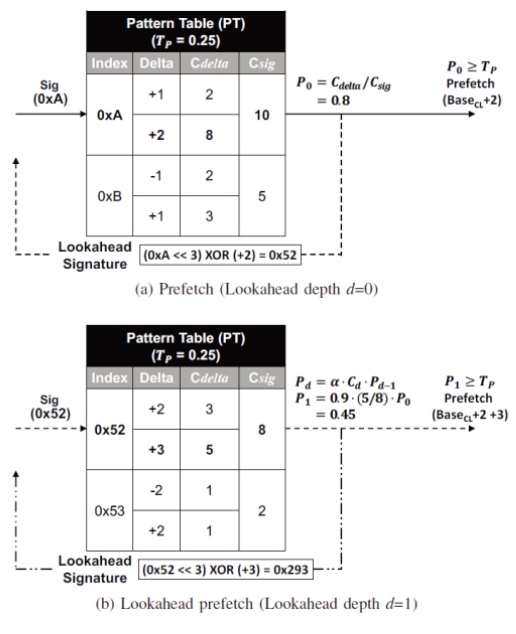
- Search the signature of the currently accessed page when L2 is accessing cacheline.
- Choose the delta with highest probability Pi ($C_{delta}/C_{sig}$) of $i_{th}$ prefetch depth
- If multiply all P larger than the threshold
- Prefetch current address + delta
- Use delta to update the signature and access the pattern table again
- If P < threshold=0.95, the procedure ends
Result
CKB-VM

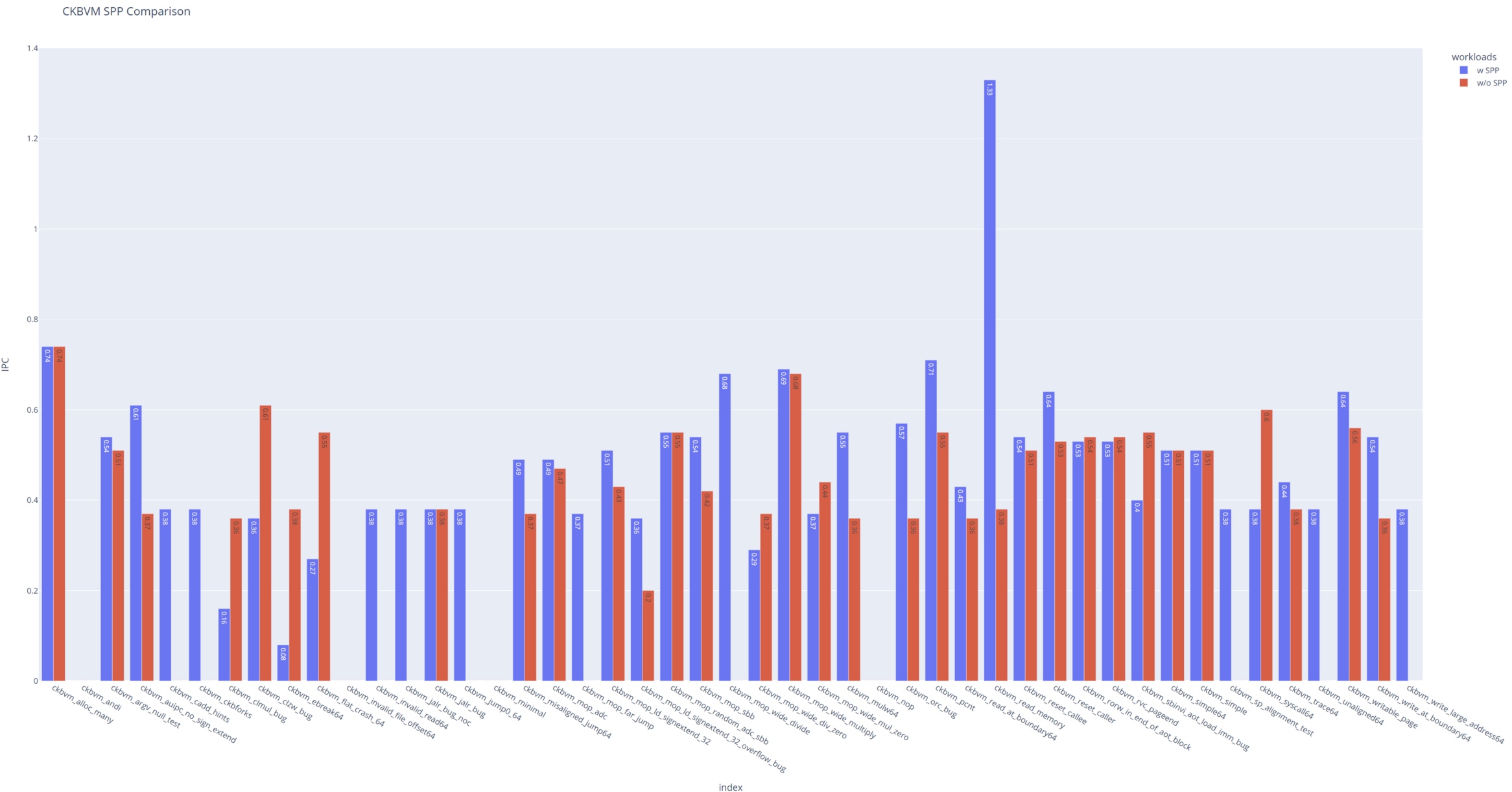
For much of the page semantic awareness workloads, the SPPPrefetcher reached a great performance, but some of the workloads are too deterministic since it's simulating the naive and straight forward test cases.
RisingWave
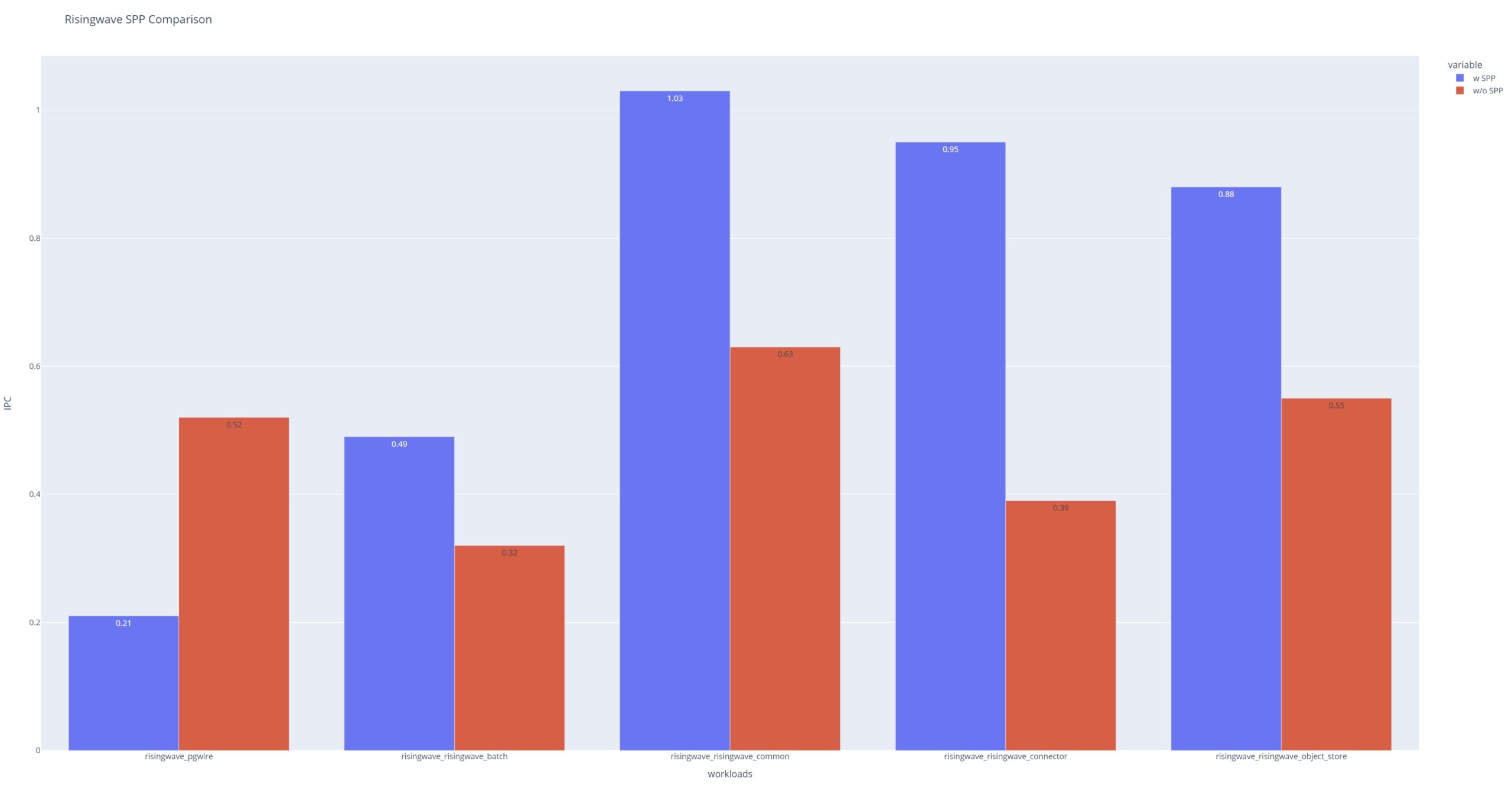
We see a great jump >1.5x speed up for in-memory database tests. It's because much of the hash merge join and sort-merge join requires page-level fetching to reduce the memory wall!
Conclusion
- For a short-term running time
- next line prefetcher or without prefetcher has better performance in benchmarks which has a more regular access pattern and higher overall miss rate
- Performance gain in random access pattern is ignorable