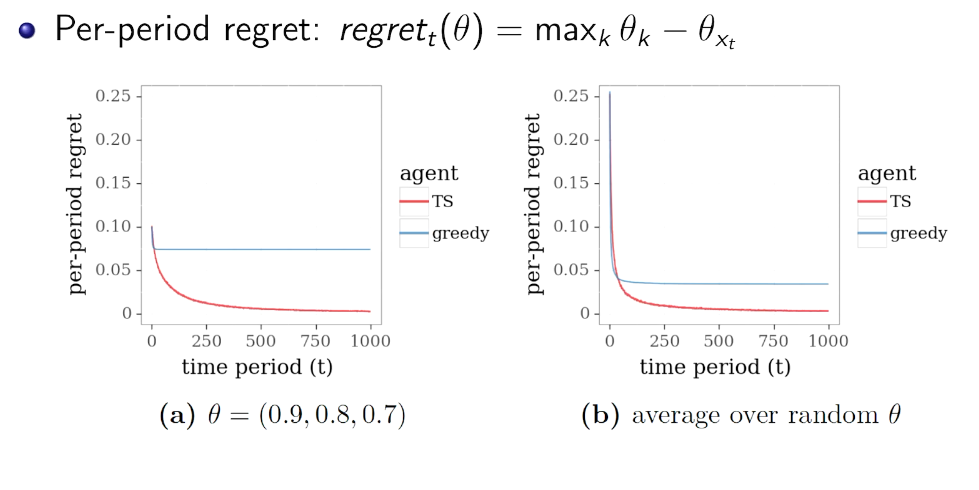
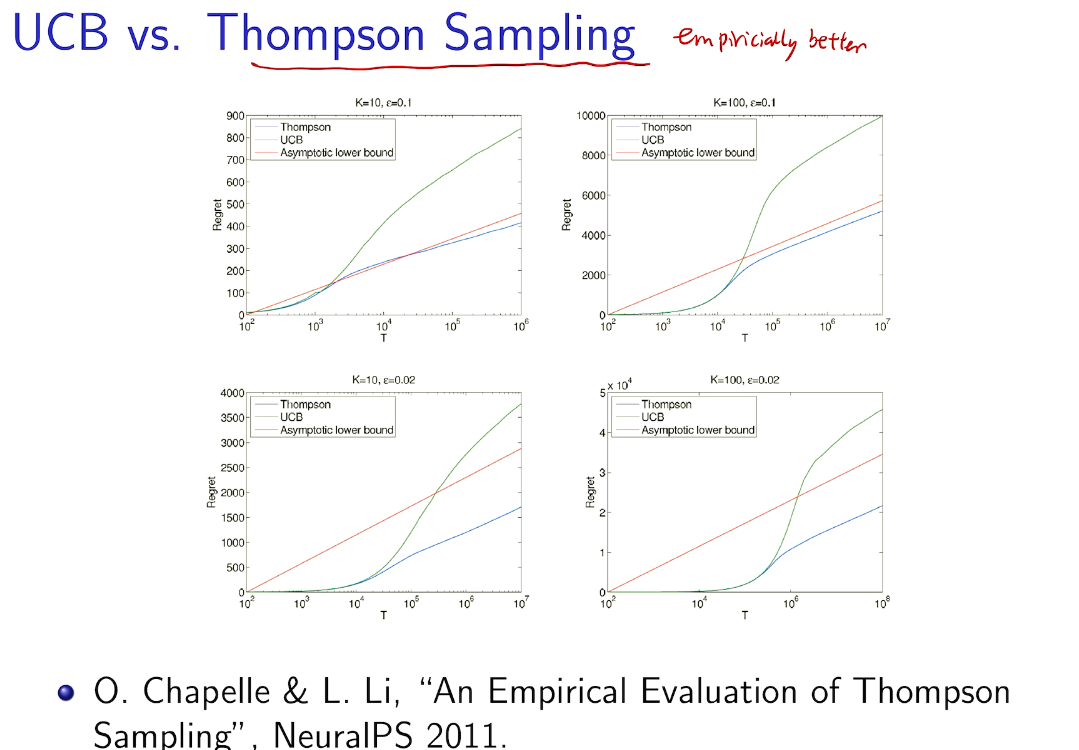
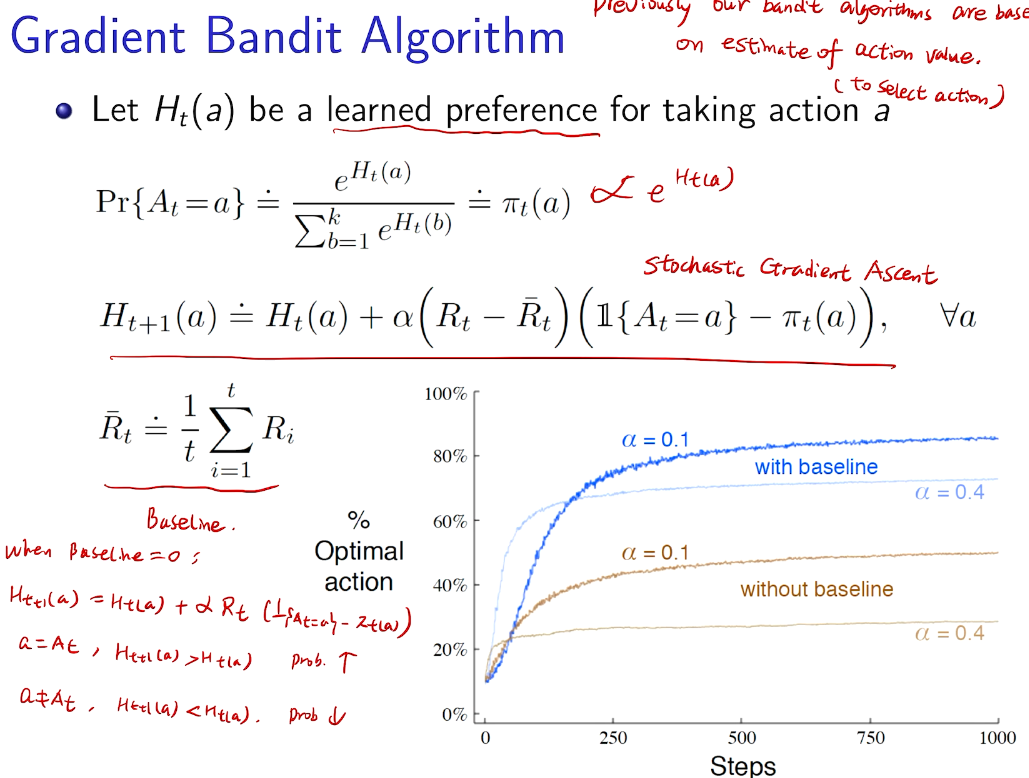
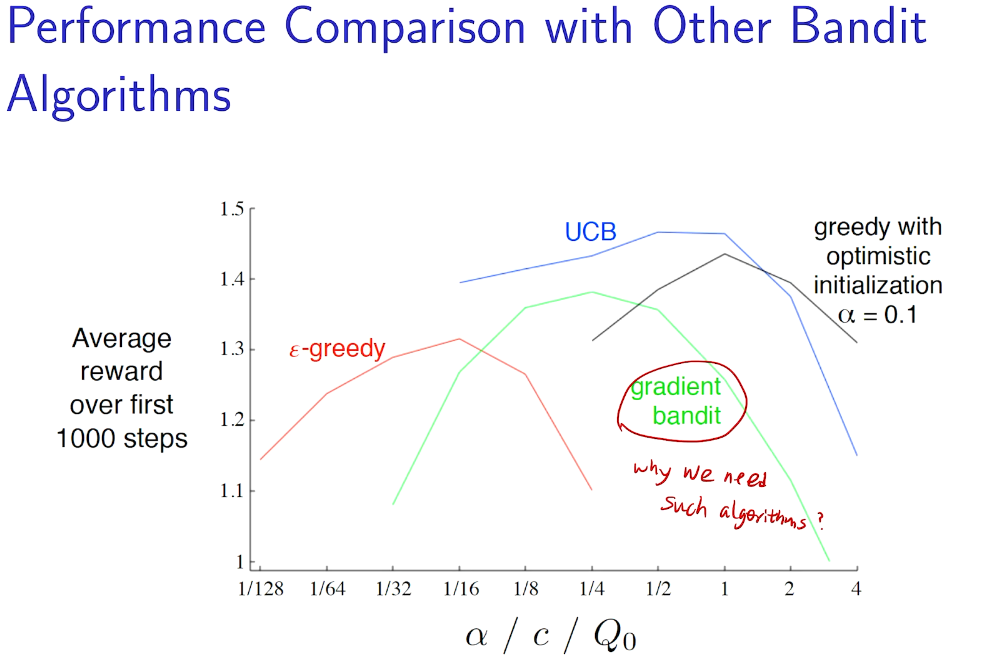
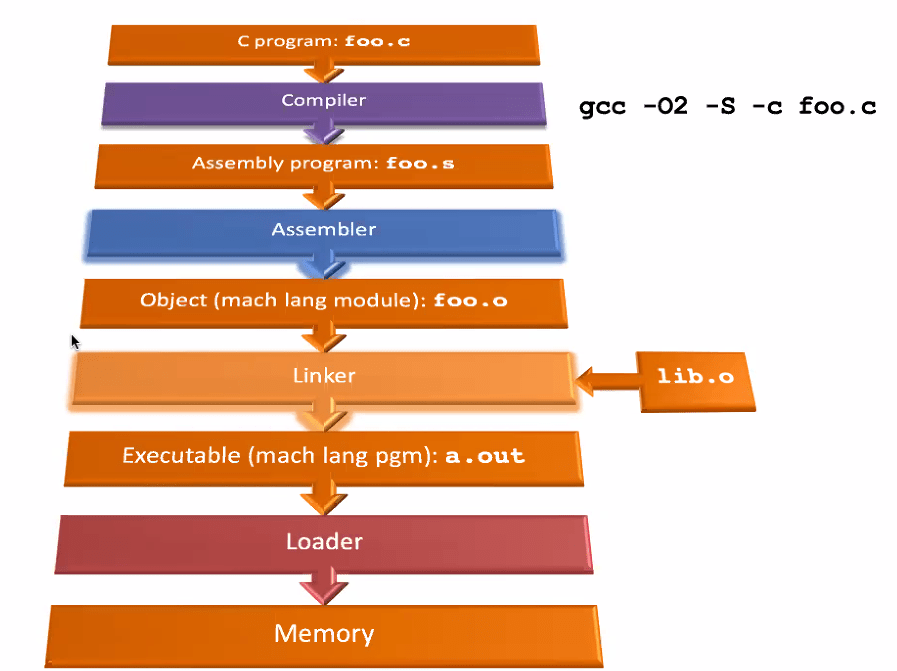
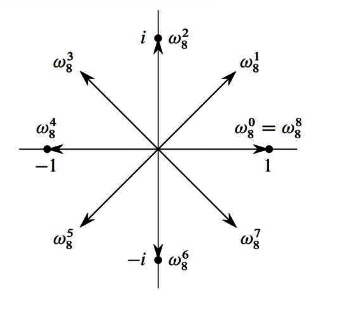
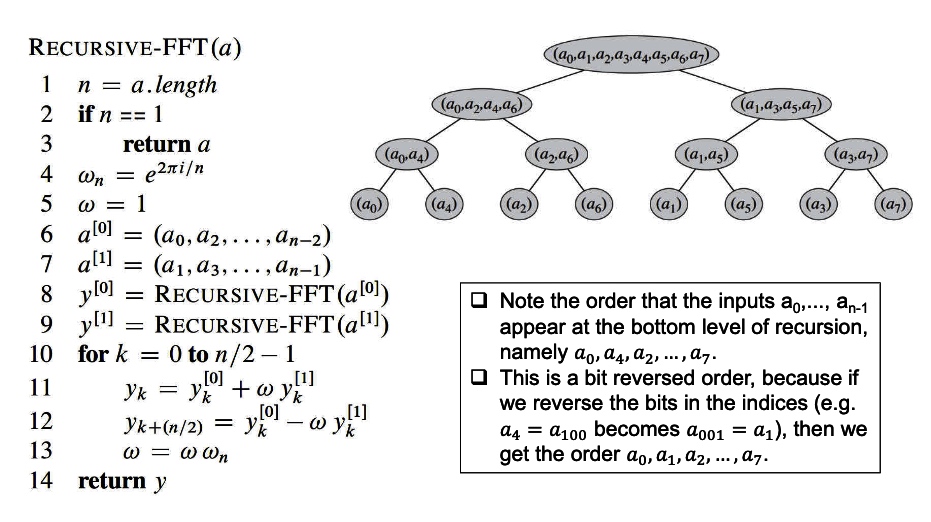
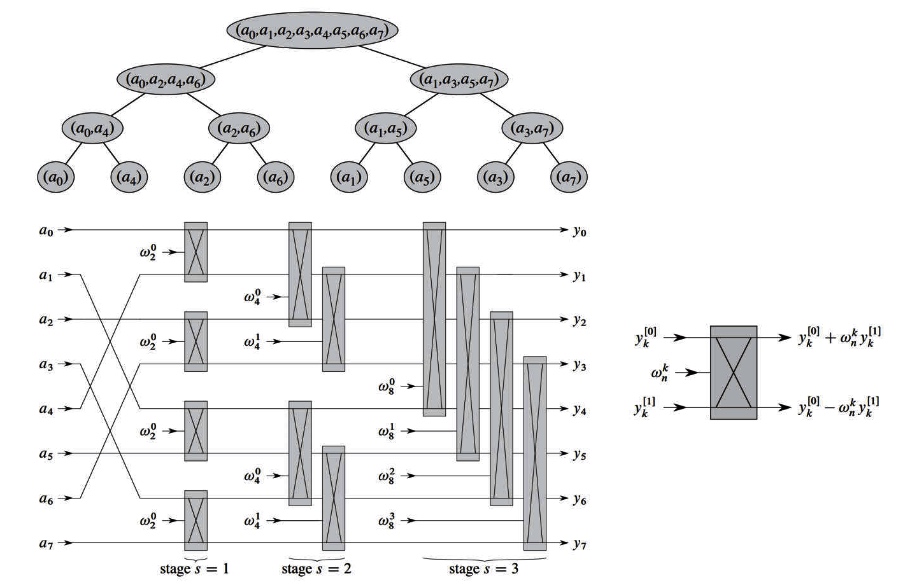
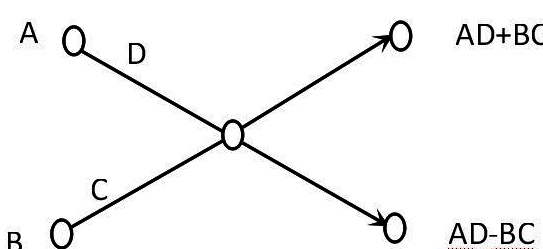
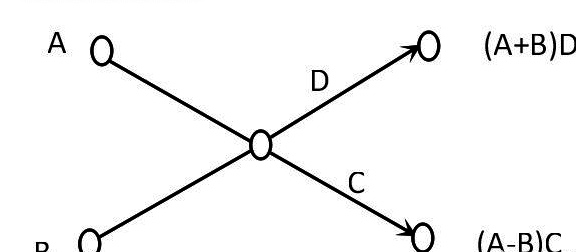
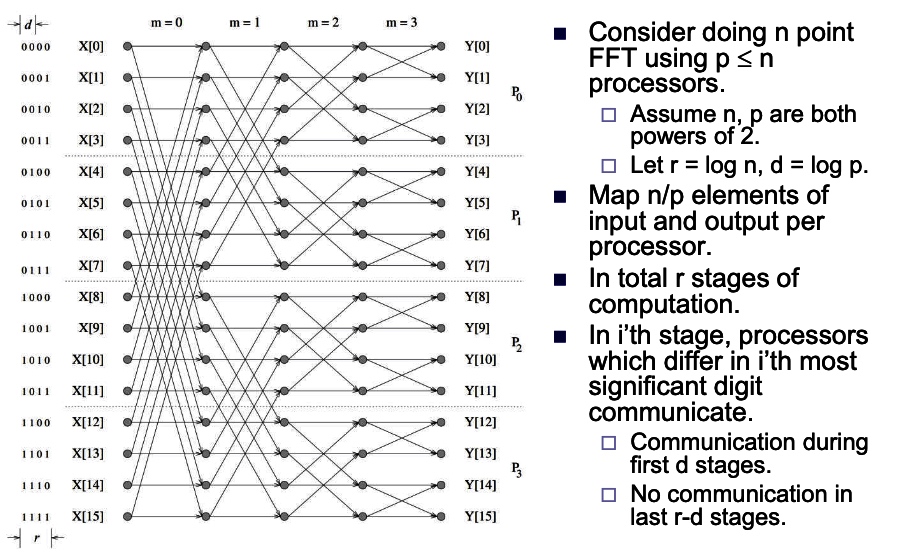
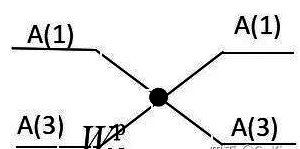
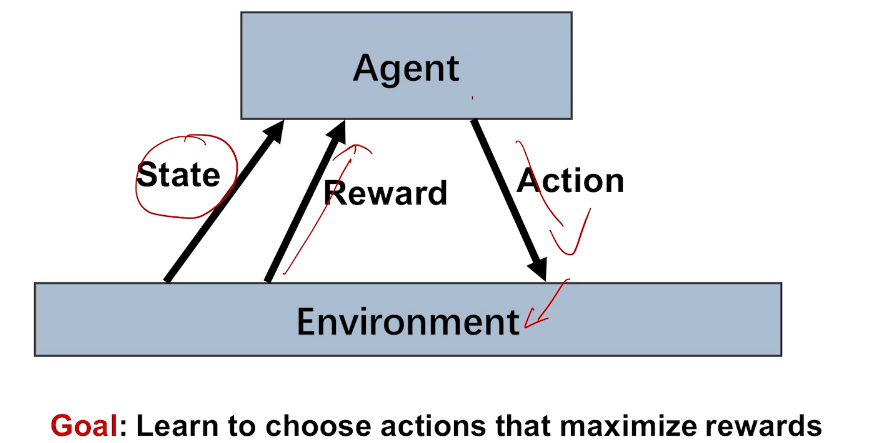
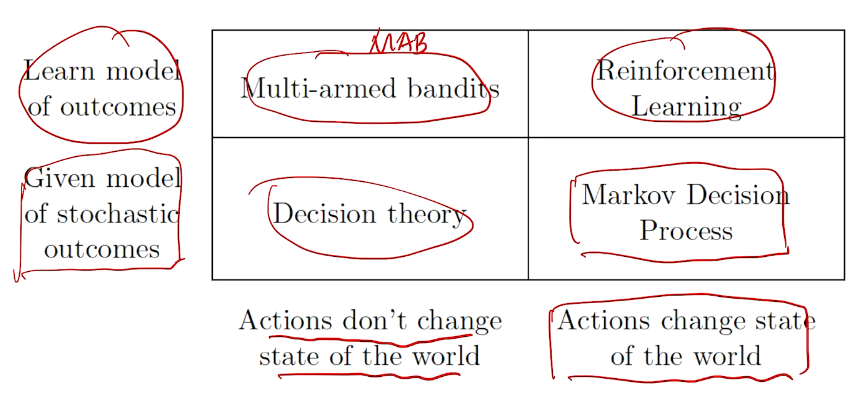
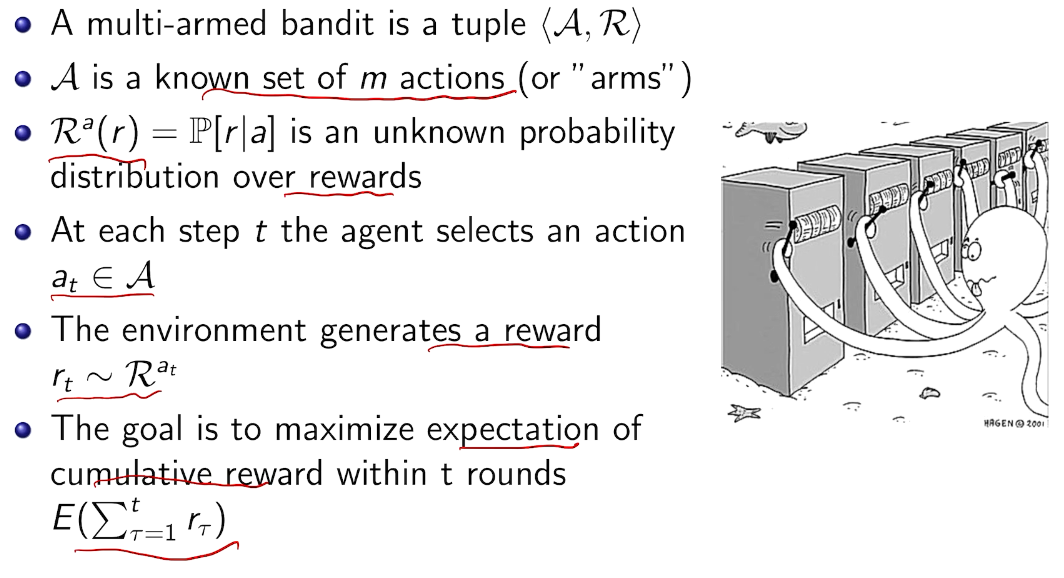
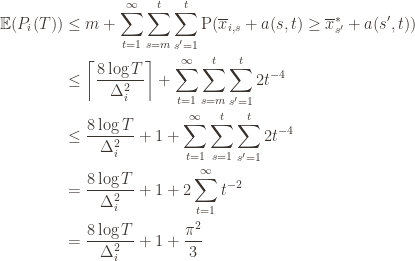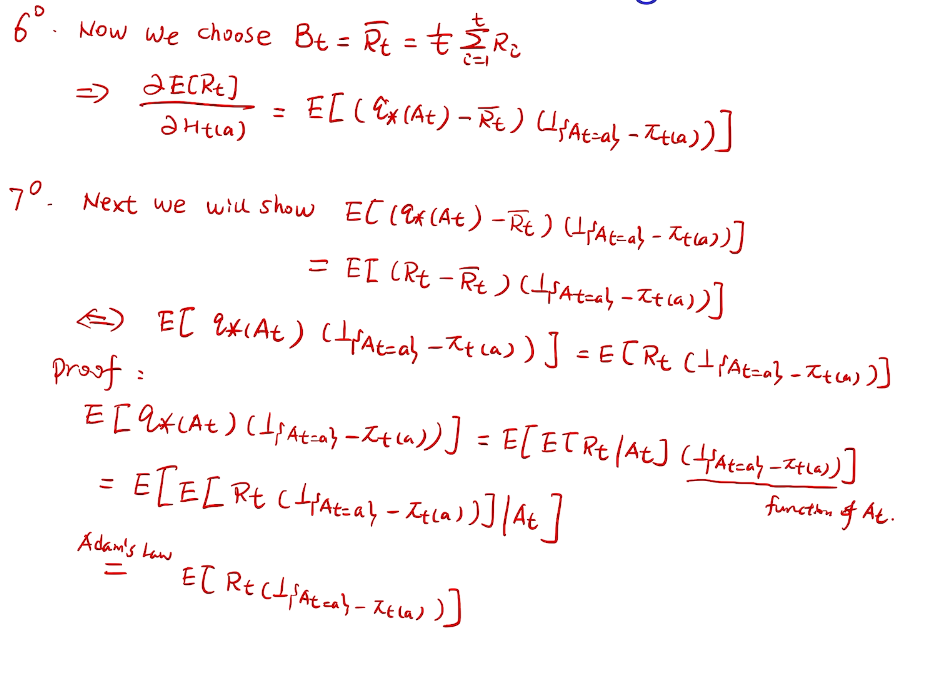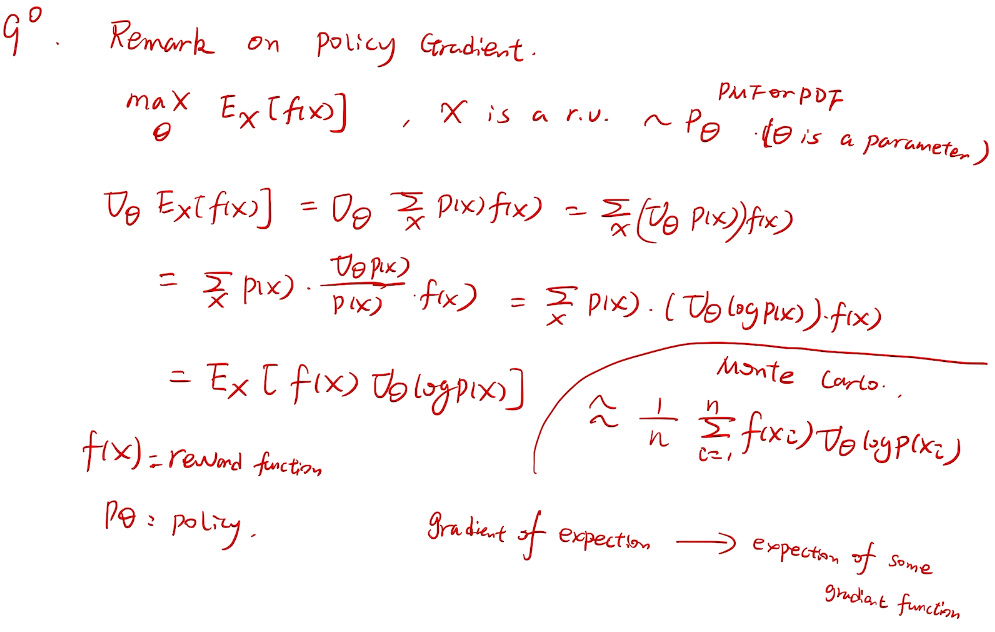intro
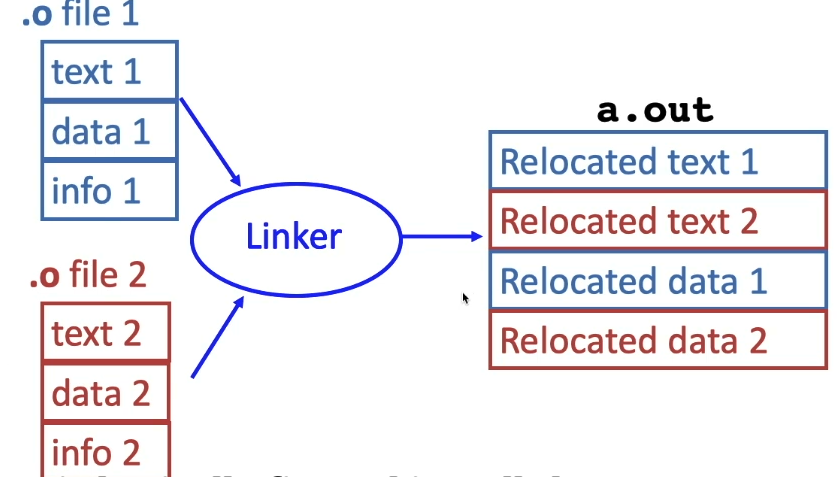
some of the volume is right in the root folder of the tar, for example.
.
├── AUTHORS
├── boards
│ ├── arm64.gni
│ ├── as370.gni
│ ├── BUILD.gn
│ ├── c18.gni
│ ├── chromebook-x64.gni
│ ├── cleo.gni
│ ├── hikey960.gni
│ ├── kirin970.gni
│ ├── msm8998.gni
│ ├── msm8x53-som.gni
│ ├── mt8167s_ref.gni
│ ├── OWNERS
│ ├── qemu-arm64.gni
│ ├── qemu-x64.gni
│ ├── toulouse.gni
│ ├── vim2.gni
│ ├── vim3.gni
│ ├── vs680.gni
│ └── x64.gni
├── build
│ ├── banjo
│ │ ├── banjo.gni
│ │ ├── banjo_library.gni
│ │ ├── BUILD.gn
│ │ ├── gen_response_file.py
│ │ ├── gen_sdk_meta.py
│ │ └── toolchain.gni
│ ├── bind
│ │ └── bind.gni
│ ├── board.gni
│ ├── BUILD.gn
│ ├── build_id.gni
│ ├── c
│ │ ├── banjo_c.gni
│ │ ├── BUILD.gn
│ │ └── fidl_c.gni
│ ├── cat.sh
│ ├── cipd.gni
│ ├── cmake
│ │ ├── HostLinuxToolchain.cmake
│ │ ├── README.md
│ │ └── ToolchainCommon.cmake
│ ├── cmx
│ │ ├── block_deprecated_misc_storage.json
│ │ ├── block_deprecated_shell.json
│ │ ├── block_rootjob_svc.json
│ │ ├── block_rootresource_svc.json
│ │ ├── cmx.gni
│ │ ├── facets
│ │ │ └── module_facet_schema.json
│ │ ├── internal_allow_global_data.cmx
│ │ └── OWNERS
│ ├── compiled_action.gni
│ ├── config
│ │ ├── arm.gni
│ │ ├── BUILDCONFIG.gn
│ │ ├── BUILD.gn
│ │ ├── clang
│ │ │ └── clang.gni
│ │ ├── compiler.gni
│ │ ├── fuchsia
│ │ │ ├── BUILD.gn
│ │ │ ├── rules.gni
│ │ │ ├── sdk.gni
│ │ │ ├── zbi.gni
│ │ │ ├── zircon.gni
│ │ │ ├── zircon_images.gni
│ │ │ └── zircon_legacy_vars.gni
│ │ ├── host_byteorder.gni
│ │ ├── linux
│ │ │ └── BUILD.gn
│ │ ├── lto
│ │ │ ├── BUILD.gn
│ │ │ └── config.gni
│ │ ├── mac
│ │ │ ├── BUILD.gn
│ │ │ ├── mac_sdk.gni
│ │ │ └── package_framework.py
│ │ ├── OWNERS
│ │ ├── profile
│ │ │ └── BUILD.gn
│ │ ├── sanitizers
│ │ │ ├── asan_default_options.c
│ │ │ ├── BUILD.gn
│ │ │ ├── debugdata.cmx
│ │ │ └── ubsan_default_options.c
│ │ ├── scudo
│ │ │ ├── BUILD.gn
│ │ │ ├── scudo_default_options.c
│ │ │ └── scudo.gni
│ │ └── sysroot.gni
│ ├── config.gni
│ ├── cpp
│ │ ├── binaries.py
│ │ ├── BUILD.gn
│ │ ├── extract_imported_symbols.gni
│ │ ├── extract_imported_symbols.sh
│ │ ├── extract_public_symbols.gni
│ │ ├── extract_public_symbols.sh
│ │ ├── fidl_cpp.gni
│ │ ├── fidlmerge_cpp.gni
│ │ ├── gen_sdk_prebuilt_meta_file.py
│ │ ├── gen_sdk_sources_meta_file.py
│ │ ├── sdk_executable.gni
│ │ ├── sdk_shared_library.gni
│ │ ├── sdk_source_set.gni
│ │ ├── sdk_static_library.gni
│ │ ├── verify_imported_symbols.gni
│ │ ├── verify_imported_symbols.sh
│ │ ├── verify_pragma_once.gni
│ │ ├── verify_pragma_once.py
│ │ ├── verify_public_symbols.gni
│ │ ├── verify_public_symbols.sh
│ │ └── verify_runtime_deps.py
│ ├── dart
│ │ ├── BUILD.gn
│ │ ├── dart.gni
│ │ ├── dart_library.gni
│ │ ├── dart_remote_test.gni
│ │ ├── dart_tool.gni
│ │ ├── empty_pubspec.yaml
│ │ ├── fidl_dart.gni
│ │ ├── fidlmerge_dart.gni
│ │ ├── gen_analyzer_invocation.py
│ │ ├── gen_app_invocation.py
│ │ ├── gen_dart_test_invocation.py
│ │ ├── gen_dot_packages.py
│ │ ├── gen_remote_test_invocation.py
│ │ ├── gen_test_invocation.py
│ │ ├── group_tests.py
│ │ ├── label_to_package_name.py
│ │ ├── OWNERS
│ │ ├── run_analysis.py
│ │ ├── sdk
│ │ │ ├── detect_api_changes
│ │ │ │ ├── analysis_options.yaml
│ │ │ │ ├── bin
│ │ │ │ │ └── main.dart
│ │ │ │ ├── BUILD.gn
│ │ │ │ ├── lib
│ │ │ │ │ ├── analyze.dart
│ │ │ │ │ ├── diff.dart
│ │ │ │ │ └── src
│ │ │ │ │ └── visitor.dart
│ │ │ │ ├── pubspec.yaml
│ │ │ │ ├── schema.json
│ │ │ │ └── test
│ │ │ │ ├── analyze_test.dart
│ │ │ │ └── diff_test.dart
│ │ │ ├── gen_meta_file.py
│ │ │ └── sort_deps.py
│ │ ├── test.gni
│ │ ├── toolchain.gni
│ │ └── verify_sources.py
│ ├── development.key
│ ├── driver_package.gni
│ ├── fidl
│ │ ├── BUILD.gn
│ │ ├── fidl.gni
│ │ ├── fidl_library.gni
│ │ ├── gen_response_file.py
│ │ ├── gen_sdk_meta.py
│ │ ├── linting_exceptions.gni
│ │ ├── OWNERS
│ │ ├── run_and_gen_stamp.sh
│ │ ├── toolchain.gni
│ │ └── wireformat.gni
│ ├── fuchsia
│ │ └── sdk.gni
│ ├── Fuchsia.cmake
│ ├── fuzzing
│ │ ├── BUILD.gn
│ │ ├── fuzzer.gni
│ │ └── OWNERS
│ ├── gn
│ │ ├── BUILD.gn
│ │ ├── gen_persistent_log_config.py
│ │ ├── OWNERS
│ │ ├── unpack_build_id_archives.sh
│ │ └── write_package_json.py
│ ├── gn_helpers.py
│ ├── gn_run_binary.sh
│ ├── go
│ │ ├── BUILD.gn
│ │ ├── build.py
│ │ ├── fidl_go.gni
│ │ ├── gen_library_metadata.py
│ │ ├── go_binary.gni
│ │ ├── go_build.gni
│ │ ├── go_fuzzer.gni
│ │ ├── go_fuzzer_wrapper.go
│ │ ├── go_library.gni
│ │ ├── go_test.gni
│ │ ├── OWNERS
│ │ └── toolchain.gni
│ ├── gypi_to_gn.py
│ ├── host.gni
│ ├── images
│ │ ├── add_tag_to_manifest.sh
│ │ ├── args.gni
│ │ ├── assemble_system.gni
│ │ ├── boot.gni
│ │ ├── bringup
│ │ │ └── BUILD.gn
│ │ ├── BUILD.gn
│ │ ├── collect_blob_manifest.gni
│ │ ├── create-shell-commands.py
│ │ ├── custom_signing.gni
│ │ ├── dummy
│ │ │ └── example.txt
│ │ ├── efi_local_cmdline.txt
│ │ ├── elfinfo.py
│ │ ├── filesystem_limits.gni
│ │ ├── finalize_manifests.py
│ │ ├── format_filesystem_sizes.py
│ │ ├── fvm.gni
│ │ ├── generate_flash_script.sh
│ │ ├── guest
│ │ │ ├── BUILD.gn
│ │ │ └── guest_meta_package.json
│ │ ├── manifest_add_dest_prefix.sh
│ │ ├── manifest_content_expand.sh
│ │ ├── manifest.gni
│ │ ├── manifest_list_collect_unique_blobs.py
│ │ ├── manifest.py
│ │ ├── max_fvm_size.gni
│ │ ├── OWNERS
│ │ ├── pack-images.py
│ │ ├── pkgfs.gni
│ │ ├── recovery
│ │ │ └── BUILD.gn
│ │ ├── shell_commands.gni
│ │ ├── system_image_prime_meta_package.json
│ │ ├── system_meta_package.json
│ │ ├── ta.gni
│ │ ├── update_package.json
│ │ ├── update_prime_package.json
│ │ ├── variant.py
│ │ ├── vbmeta.gni
│ │ ├── zedboot
│ │ │ ├── BUILD.gn
│ │ │ ├── efi_cmdline.txt
│ │ │ └── zedboot_args.gni
│ │ ├── zircon
│ │ │ ├── bootsvc.gni
│ │ │ └── BUILD.gn
│ │ └── zxcrypt.gni
│ ├── info
│ │ ├── BUILD.gn
│ │ ├── gen-latest-commit-date.sh
│ │ └── info.gni
│ ├── __init__.py
│ ├── json
│ │ └── validate_json.gni
│ ├── mac
│ │ └── find_sdk.py
│ ├── make_map.py
│ ├── module_args
│ │ └── dart.gni
│ ├── OWNERS
│ ├── package
│ │ └── component.gni
│ ├── package.gni
│ ├── packages
│ │ ├── BUILD.gn
│ │ ├── OWNERS
│ │ ├── prebuilt_package.gni
│ │ ├── prebuilt_package.py
│ │ ├── prebuilt_test_manifest.gni
│ │ └── prebuilt_test_package.gni
│ ├── persist_logs.gni
│ ├── README.md
│ ├── rust
│ │ ├── banjo_rust.gni
│ │ ├── banjo_rust_library.gni
│ │ ├── BUILD.gn
│ │ ├── config.gni
│ │ ├── fidl_rust.gni
│ │ ├── fidl_rust_library.gni
│ │ ├── list_files_in_dir.py
│ │ ├── OWNERS
│ │ ├── rustc_binary.gni
│ │ ├── rustc_binary_sdk.gni
│ │ ├── rustc_cdylib.gni
│ │ ├── rustc_fuzzer.gni
│ │ ├── rustc_library.gni
│ │ ├── rustc_macro.gni
│ │ ├── rustc_staticlib.gni
│ │ ├── rustc_test.gni
│ │ ├── stamp.sh
│ │ └── toolchain.gni
│ ├── sdk
│ │ ├── BUILD.gn
│ │ ├── compute_atom_api.py
│ │ ├── config.gni
│ │ ├── create_atom_manifest.py
│ │ ├── create_molecule_manifest.py
│ │ ├── export_sdk.py
│ │ ├── generate_archive_manifest.py
│ │ ├── generate_meta.py
│ │ ├── manifest_schema.json
│ │ ├── merged_sdk.gni
│ │ ├── meta
│ │ │ ├── banjo_library.json
│ │ │ ├── BUILD.gn
│ │ │ ├── cc_prebuilt_library.json
│ │ │ ├── cc_source_library.json
│ │ │ ├── common.json
│ │ │ ├── dart_library.json
│ │ │ ├── device_profile.json
│ │ │ ├── documentation.json
│ │ │ ├── fidl_library.json
│ │ │ ├── host_tool.json
│ │ │ ├── loadable_module.json
│ │ │ ├── manifest.json
│ │ │ ├── README.md
│ │ │ ├── src
│ │ │ │ ├── banjo_library.rs
│ │ │ │ ├── cc_prebuilt_library
conclusion
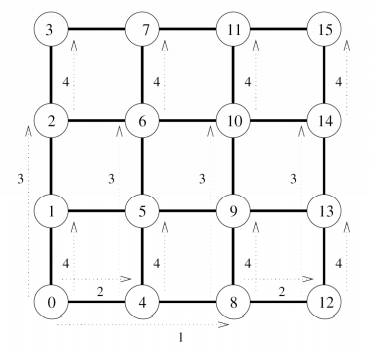
tar tjvf {}.bz2 | grep ^d | awk -F/ '{if(NF<4) print }'
insights
- NF in awk is the number of fields divided by '/'! Not the number of '/'!
- After the '/' at the end of the line, even if there are no more characters, it is then counted into a field!
- For example, the following: drwxr-xr-x root / root 0 2011-08-26 09:18 bin / This is 3 fields! !! !!






 vs
vs





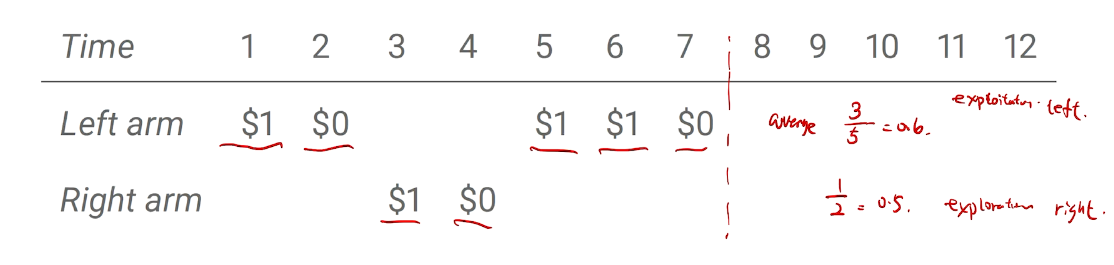









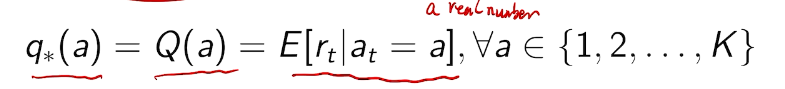
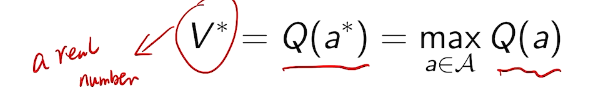
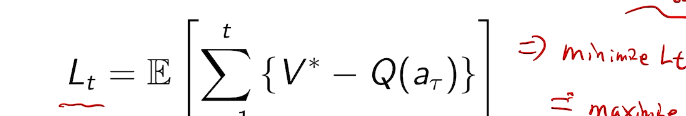
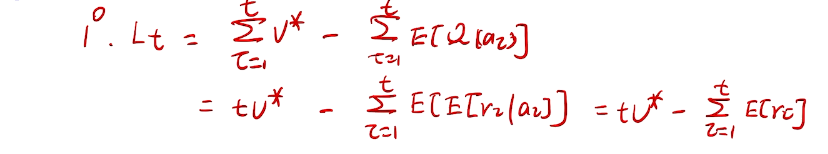

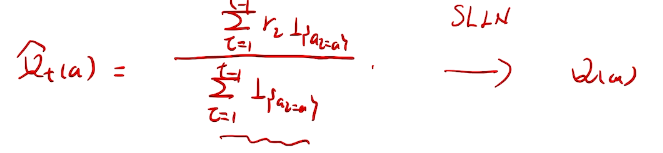


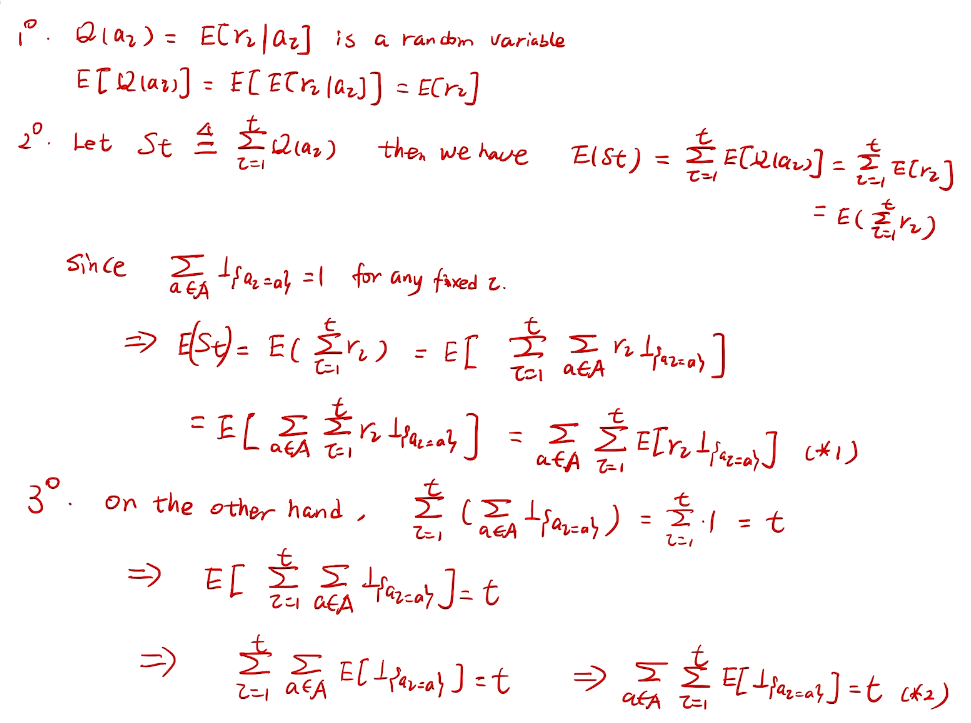
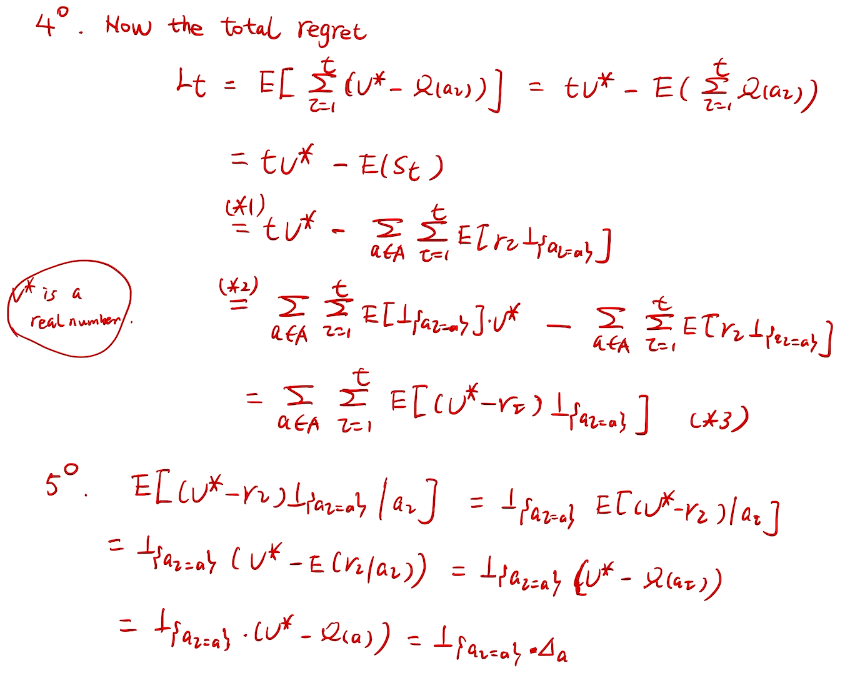
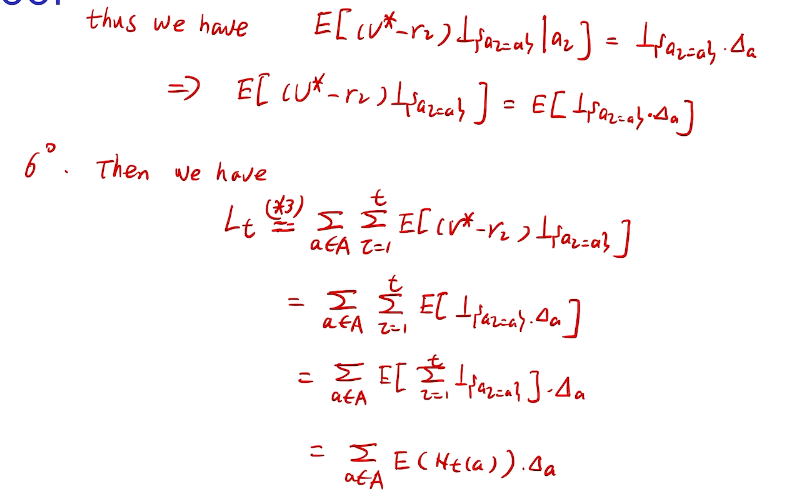
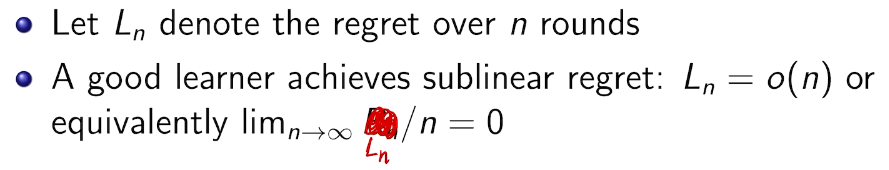



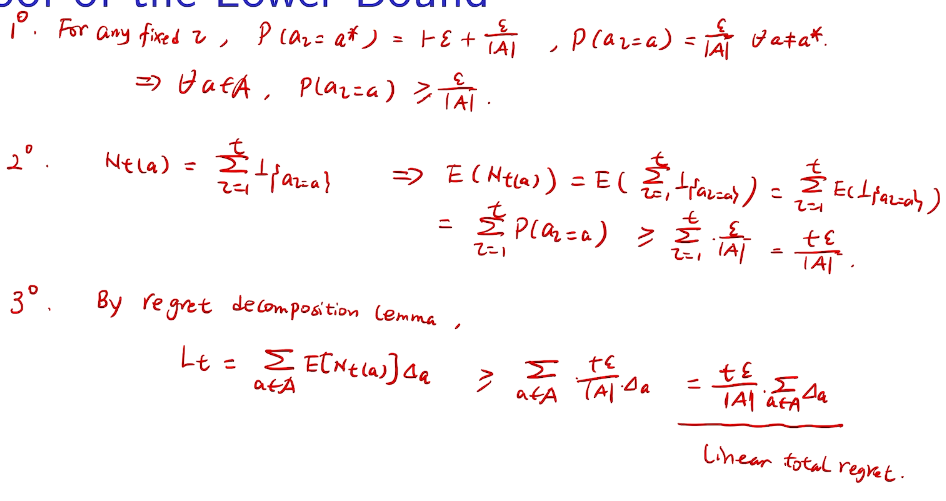
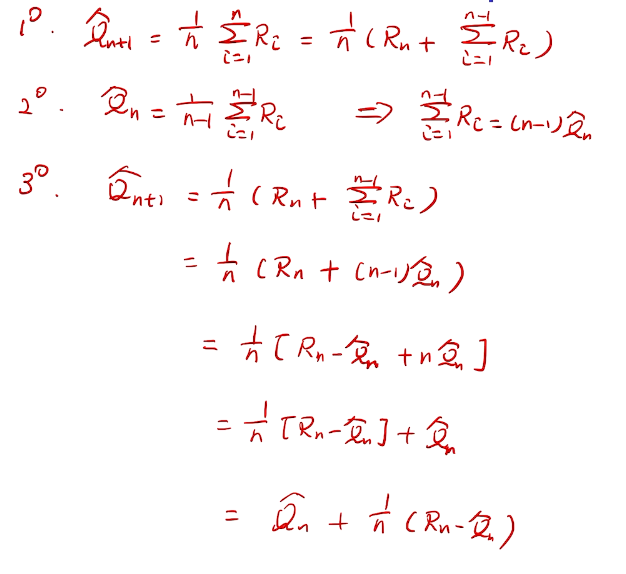

 which is 0 in this case. but we can do 5.
which is 0 in this case. but we can do 5.


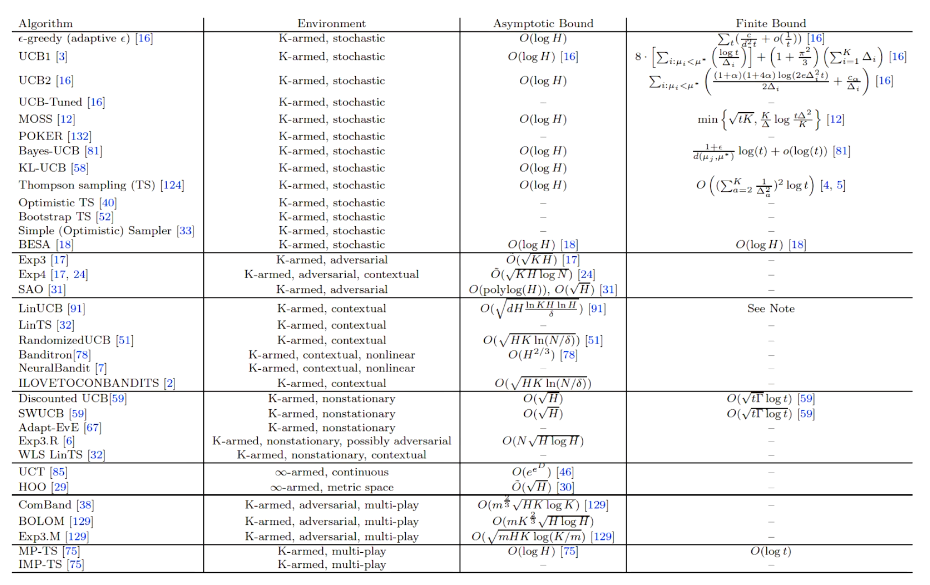
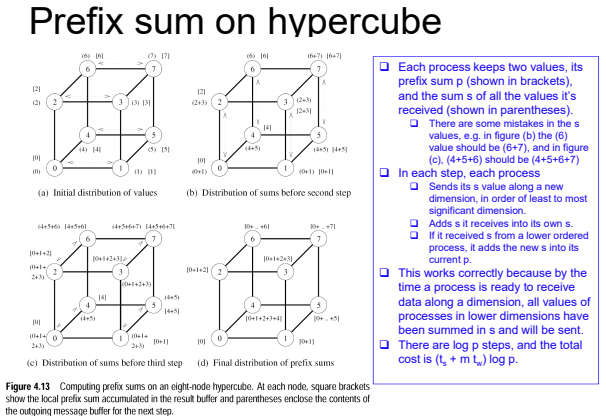
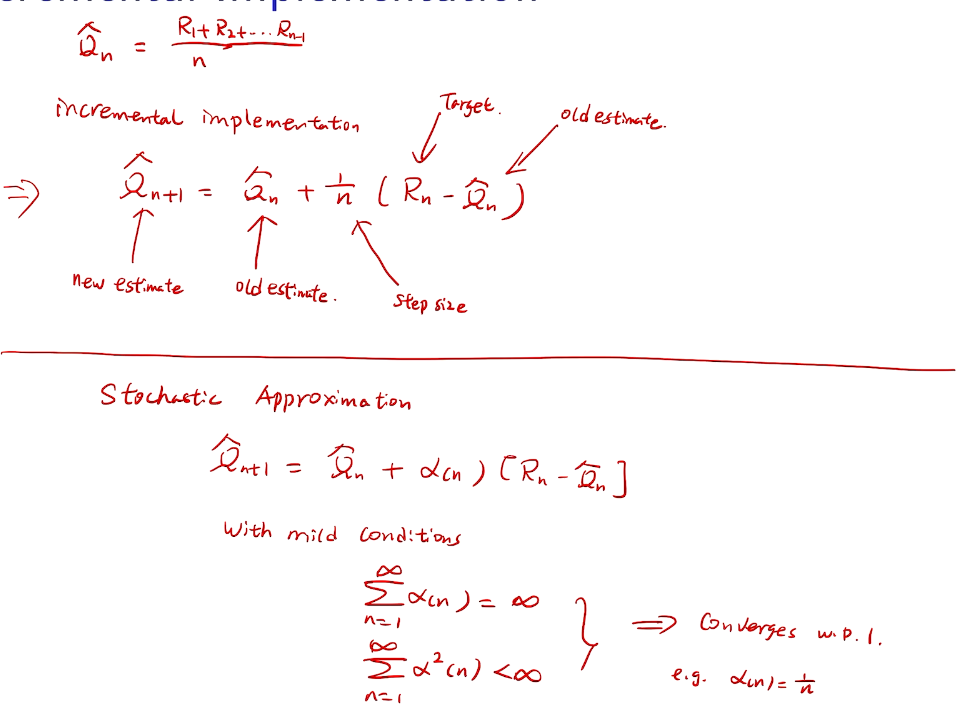
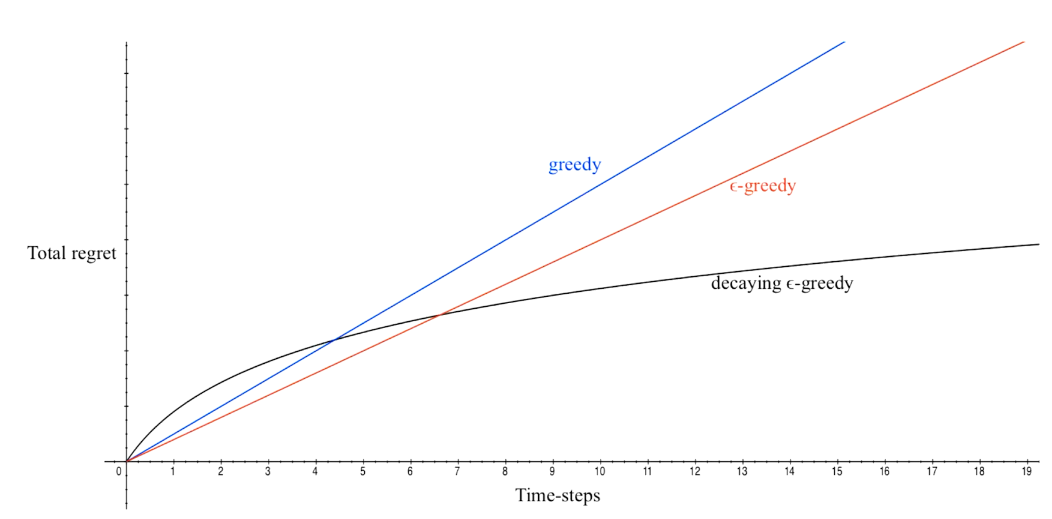 ## bandit algorithm lower bounds(depends on gaps)
## bandit algorithm lower bounds(depends on gaps)






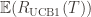 is at most$\displaystyle 8 \sum_{i : \mu_i < \mu^*} \frac{\log T}{\Delta_i} + \left ( 1 + \frac{\pi^2}{3} \right ) \left ( \sum_{j=1}^K \Delta_j \right )$
is at most$\displaystyle 8 \sum_{i : \mu_i < \mu^*} \frac{\log T}{\Delta_i} + \left ( 1 + \frac{\pi^2}{3} \right ) \left ( \sum_{j=1}^K \Delta_j \right )$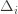 is small we will require more tries to know that action
is small we will require more tries to know that action 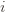 is suboptimal, and hence we will incur more regret. The second term represents a small constant number (the $1 + \pi^2 / 3$ part) that caps the number of times we’ll play suboptimal machines in excess of the first term due to unlikely events occurring. So the first term is like our expected losses, and the second is our risk.
is suboptimal, and hence we will incur more regret. The second term represents a small constant number (the $1 + \pi^2 / 3$ part) that caps the number of times we’ll play suboptimal machines in excess of the first term due to unlikely events occurring. So the first term is like our expected losses, and the second is our risk.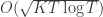 bound mentioned above. This will require familiarity with multivariable calculus, but such things must be endured like ripping off a band-aid. First consider the regret as a function
bound mentioned above. This will require familiarity with multivariable calculus, but such things must be endured like ripping off a band-aid. First consider the regret as a function  (excluding of course
(excluding of course 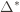 ), and let’s look at the worst case bound by maximizing it. In particular, we’re just finding the problem with the parameters which screw our bound as badly as possible, The gradient of the regret function is given by
), and let’s look at the worst case bound by maximizing it. In particular, we’re just finding the problem with the parameters which screw our bound as badly as possible, The gradient of the regret function is given by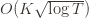
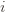 ,
, 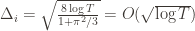 . However this is a minimum of the regret bound (the Hessian is diagonal and all its eigenvalues are positive). Plugging in the
. However this is a minimum of the regret bound (the Hessian is diagonal and all its eigenvalues are positive). Plugging in the 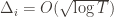 (which are all the same) gives a total bound of
(which are all the same) gives a total bound of 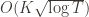 . If we look at the only possible endpoint (the
. If we look at the only possible endpoint (the 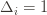 ), then we get a local maximum of
), then we get a local maximum of 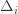 go to zero. But at the same time, if all the
go to zero. But at the same time, if all the 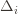 are small, then we shouldn’t be incurring much regret because we’ll be picking actions that are close to optimal!
are small, then we shouldn’t be incurring much regret because we’ll be picking actions that are close to optimal!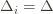 are the same, then another trivial regret bound is
are the same, then another trivial regret bound is 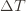 (why?). The true regret is hence the minimum of this regret bound and the UCB1 regret bound: as the UCB1 bound degrades we will eventually switch to the simpler bound. That will be a non-differentiable switch (and hence a critical point) and it occurs at
(why?). The true regret is hence the minimum of this regret bound and the UCB1 regret bound: as the UCB1 bound degrades we will eventually switch to the simpler bound. That will be a non-differentiable switch (and hence a critical point) and it occurs at 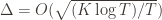 . Hence the regret bound at the switch is
. Hence the regret bound at the switch is 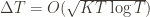 , as desired.
, as desired. , the expected number of times UCB chooses an action up to round
, the expected number of times UCB chooses an action up to round 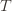 . Using the
. Using the 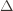 notation, the regret is then just
notation, the regret is then just 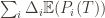 , and bounding the
, and bounding the 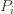 ‘s will bound the regret.
‘s will bound the regret. and let’s loosen it a bit to
and let’s loosen it a bit to 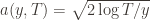 so that we’re allowed to “pretend” a action has been played
so that we’re allowed to “pretend” a action has been played 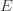 times. Recall further that the random variable
times. Recall further that the random variable 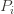 has as its value the index of the machine chosen. We denote by
has as its value the index of the machine chosen. We denote by  the indicator random variable for the event
the indicator random variable for the event 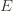 . And remember that we use an asterisk to denote a quantity associated with the optimal action (e.g.,
. And remember that we use an asterisk to denote a quantity associated with the optimal action (e.g., 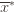 is the empirical mean of the optimal action).
is the empirical mean of the optimal action).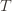 , the only way we know how to write down
, the only way we know how to write down 
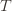 . Now we’re just going to pull some number
. Now we’re just going to pull some number 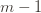 of plays out of that summation, keep it variable, and try to optimize over it. Since we might play the action fewer than
of plays out of that summation, keep it variable, and try to optimize over it. Since we might play the action fewer than 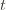 times overall, this requires an inequality.
times overall, this requires an inequality.
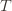 in round
in round 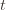 and we’ve already played
and we’ve already played 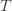 at least
at least 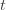 times. Now we’re going to focus on the inside of the summation, and come up with an event that happens at least as frequently as this one to get an upper bound. Specifically, saying that we’ve picked action
times. Now we’re going to focus on the inside of the summation, and come up with an event that happens at least as frequently as this one to get an upper bound. Specifically, saying that we’ve picked action 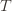 in round
in round 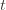 means that the upper bound for action
means that the upper bound for action 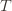 exceeds the upper bound for every other action. In particular, this means its upper bound exceeds the upper bound of the best action (and
exceeds the upper bound for every other action. In particular, this means its upper bound exceeds the upper bound of the best action (and 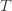 might coincide with the best action, but that’s fine). In notation this event is
might coincide with the best action, but that’s fine). In notation this event is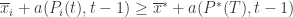
 for action
for action 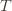 in round
in round 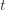 by
by  . Since this event must occur every time we pick action
. Since this event must occur every time we pick action 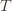 (though not necessarily vice versa), we have
(though not necessarily vice versa), we have
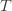 exceeds that of the optimal machine, it is also the case that the maximum upper bound for action
exceeds that of the optimal machine, it is also the case that the maximum upper bound for action 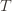 we’ve seen after the first
we’ve seen after the first 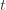 trials exceeds the minimum upper bound we’ve seen on the optimal machine (ever). But on round
trials exceeds the minimum upper bound we’ve seen on the optimal machine (ever). But on round 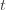 we don’t know how many times we’ve played the optimal machine, nor do we even know how many times we’ve played machine
we don’t know how many times we’ve played the optimal machine, nor do we even know how many times we’ve played machine 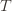 (except that it’s more than
(except that it’s more than 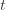 ). So we try all possibilities and look at minima and maxima. This is a pretty crude approximation, but it will allow us to write things in a nicer form.
). So we try all possibilities and look at minima and maxima. This is a pretty crude approximation, but it will allow us to write things in a nicer form.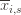 the random variable for the empirical mean after playing action
the random variable for the empirical mean after playing action 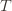 a total of
a total of  times, and
times, and 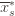 the corresponding quantity for the optimal machine. Realizing everything in notation, the above argument proves that
the corresponding quantity for the optimal machine. Realizing everything in notation, the above argument proves that
 for which the max is greater than the min, there will be at least one pair
for which the max is greater than the min, there will be at least one pair  for which the values of the quantities inside the max/min will satisfy the inequality. And so, even worse, we can just count the number of pairs
for which the values of the quantities inside the max/min will satisfy the inequality. And so, even worse, we can just count the number of pairs  for which it happens. That is, we can expand the event above into the double sum which is at least as large:
for which it happens. That is, we can expand the event above into the double sum which is at least as large: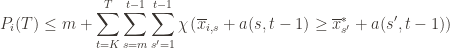
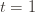 to
to 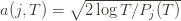 . This will become clear later, but it means we can replace
. This will become clear later, but it means we can replace 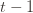 with
with 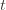 and thus have
and thus have
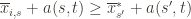 . Then what can we say? Well, consider the following three events:
. Then what can we say? Well, consider the following three events: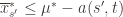
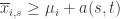

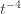 . Likewise, (2) is the event that the empirical mean payoff of action
. Likewise, (2) is the event that the empirical mean payoff of action 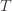 is larger than the upper confidence bound, which also occurs with probability
is larger than the upper confidence bound, which also occurs with probability 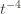 . We will see momentarily that (3) is impossible for a well-chosen
. We will see momentarily that (3) is impossible for a well-chosen 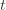 (which is why we left it variable), but in any case the claim is that one of these three events must occur. For if they are all false, we have
(which is why we left it variable), but in any case the claim is that one of these three events must occur. For if they are all false, we have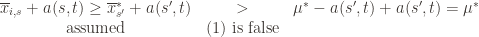


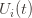 plus whatever the probability of (3) being true is. But as we said, we’ll pick
plus whatever the probability of (3) being true is. But as we said, we’ll pick 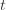 to make (3) always false. Indeed
to make (3) always false. Indeed 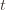 depends on which action
depends on which action 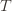 is being played, and if
is being played, and if 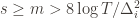 then
then 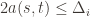 , and by the definition of
, and by the definition of 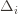 we have
we have .
.