

Monte-Carlo RL
- MC learn directly from episodes of experience.
- MC is model-free. No knowledge of MDP transitions or rewraeds.
- MC learns fro complete episodes. no bootstrapping
- Here Bootstrapping means Using one or more estimated values in the update step fro the same kind of estimated value.. like in \(SARSA(\lambda)\) or \(Q(\lambda)\)

- The single-step TD is to utilize the bootstrap by using a mix of results from different length trajectories.
- Here Bootstrapping means Using one or more estimated values in the update step fro the same kind of estimated value.. like in \(SARSA(\lambda)\) or \(Q(\lambda)\)
- MC uses the simplest possible idea: value = mean return
- 2 ways:
- model-free: no model necessary and still attains optimality
- Simulated: needs only a simulation, not a full model
- Caveat: can only apply MC to episodic MDPs
- All episodes must terminate
policy evaluation
The goal is to learn \(v_\pi\) from episodes of experience under policy \(\pi\)
\[S_1,A_1,R_2,....S_k \sim 1\]
and the return is the total discounted reward: \(G_t=R_{t+1}+\gamma R_{t+2}+...\gamma ^{T-1}T_T\).
The value function is the expected return : \(v_\pi(x)=\mathbb{E}_{\pi}[G_t~S_t=s]\)
P.S. This policy use empirical mean rather than expected return.
By different visits during an episode, they can be diverged into Every-Visit and First-visit, and both converge asymptotically.
First-visit

proof of convergence

In fact it's the "backward mean \(\frac{S(s)}{N(s)}\)" to update \(V(s)\)
blackjack (21 points)
In Sutton's book, we get the exploration graph like
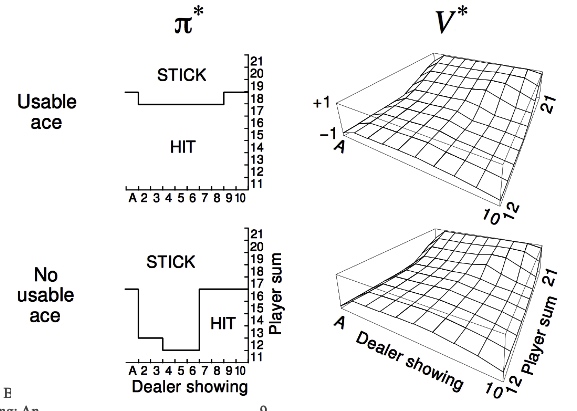
Every-Visit Monte-Carlo Policy Evaluation
the difference is every visits.

Incremental Mean
The mean \(\mu_1,\mu_2.... \) of the sequent can be computed incrementally by
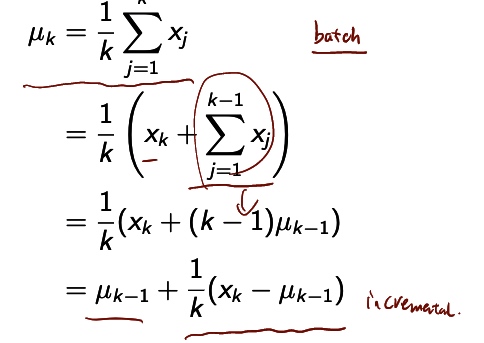
incremental MC-updates

Monte-Carlo Estimation of Action Values

Backup Diagram for Monte-Carlo
Similar to Bandit, is to find optimal from the explore/exploit dilemma the entire rest of episode included. and the only choice considered is at each state and doesn't bootstrap.(unlike DP).
Time required to estimate one state does not depend onthe total number of states
Temporal-Difference Learning
Bootstrapping
Saying: To lift one up, strap the boot of sb. again and again which is incompletable.
Modern definition: re-sampling technique from the same sample again and again which has the statistical meaning.
intro
- TD methods learn directly from episodes of experience
- TD is model-free:no knowledge of MDP transitions/rewards
- TD learns from incomplete episodes, by bootstrapping
- TD updates a guess towards a guess
\((number)\) the number represent the look ahead times.
driving home example
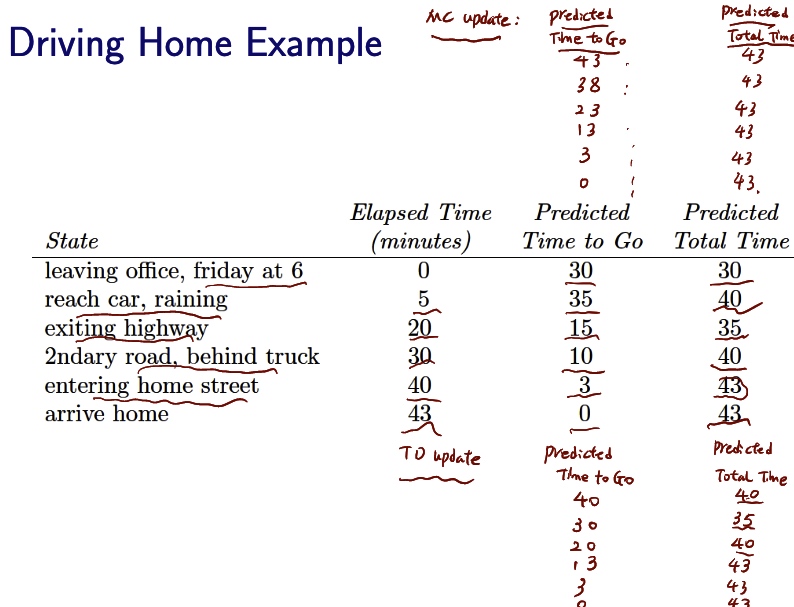
TD is more flexible for MC have to wait for the final result for the update. On policy vs. off policy.
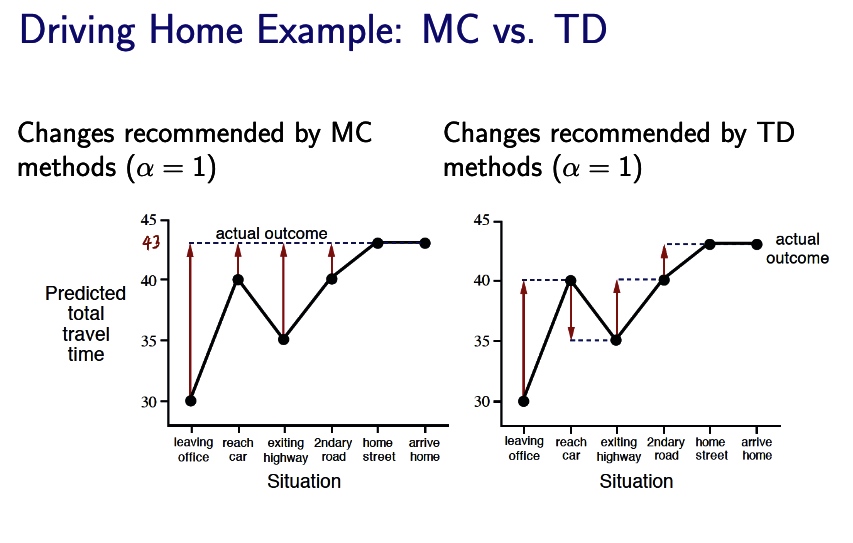

MC make a nearest prediction
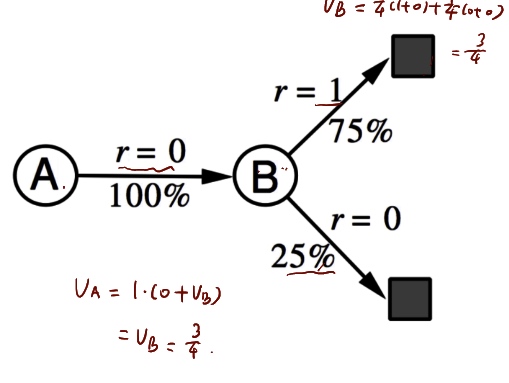

We actually can generate the estimated MDP graph and corresponding example for AB example.
Comparison
- TD can learn before knowing the final outcome
- TD can learn online after every step (less memory & peak computation)
- MC must wait until end of episode before return is known
- TD can learn without the final outcome
- TD can learn from incomplete sequences
- MC can only learn from complete sequences
- TD works in continuing (non-terminating) environments
- MC only works for episodic (terminating) environment
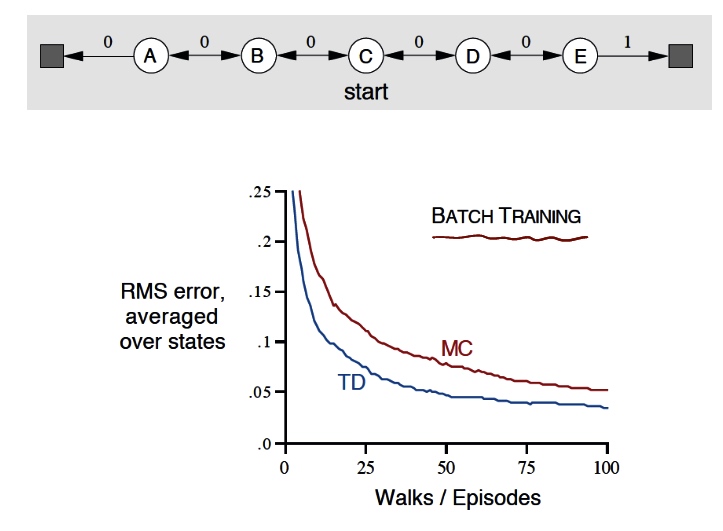
### result is TD performs better in random walk
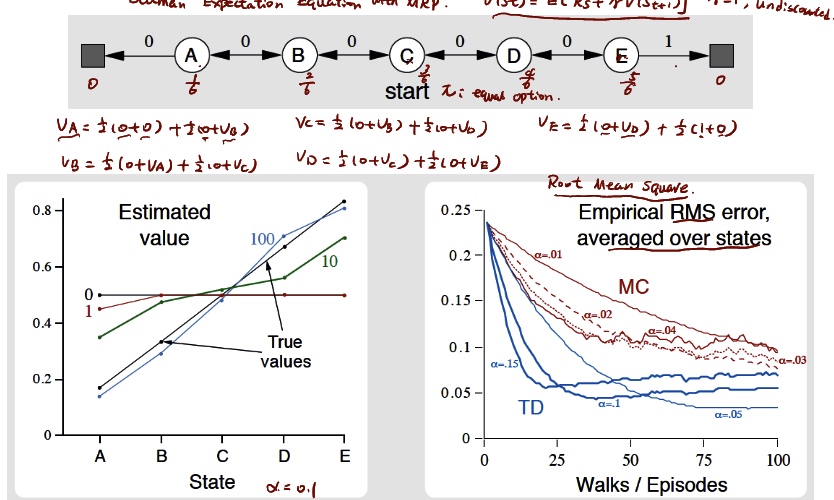


batch MC and TD
add step parameter \(\alpha\)

Unified comparison
 \(\to\)
\(\to\)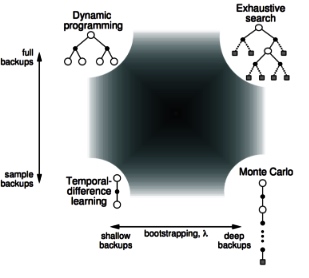
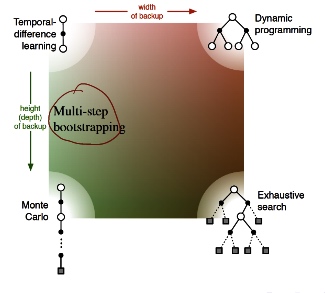
- Bootstrapping: update involves an estimate
- MC does not bootstrap
- DP bootstraps
- TD bootstraps
- Sampling:update samples an expectation
- MC samples
- DP does not sample
- TD samples
n-step TD
⁃ $
\begin{array}{l}\text { n-Step Return } \ \qquad \begin{aligned} \text { Consider the following } n \text { -step returns for } n=1,2, \infty \ \qquad \begin{aligned} n=1 &(T D) & \frac{G_{t}{(1)}}{G_{t}{(2)}}=\frac{R_{t+1}+\gamma V\left(S_{t+1}\right)}{R_{t+1}+\gamma R_{t+2}+\gamma{2} V\left(S_{t+2}\right)} \ & \vdots \end{aligned} \ \qquad n=\infty \quad(M C) \quad G_{t}{(\infty)}=R_{t+1}+\gamma R_{t+2}+\ldots \gamma{T-1} R_{T} \end{aligned} \ \text { - Define the } n \text { -step return } \ \qquad \underbrace{G_{t}{(n)}=R_{t+1}+\gamma R_{t+2}+\ldots+\gamma{n-1} R_{t+n}+\gamma{n} V\left(S_{t+n}\right)}_{The\ General\ case}\ \text { - n} \text { -step temporal-difference learning } \ \qquad V\left(S_{t}\right) \leftarrow V\left(S_{t}\right)+\alpha\left(G_{t}{(n)}-V\left(S_{t}\right)\right)\end{array}
$$