

深造加油站——给学弟学妹的一些建议

本页使用 react-pdf 模版 https://github.com/victoryang00/react-pdf-switcher
https://asplos.dev/wordpress/wp-content/uploads/2022/03/深造加油站第六期-SOP-杨易为.pdf https://asplos.dev/wordpress/wp-content/uploads/2022/03/深造加油站第二期-暑期科研-杨易为.pdfSegCache: a memory-efficient and scalable in-memory key-value cache for small objects NSDI 21'
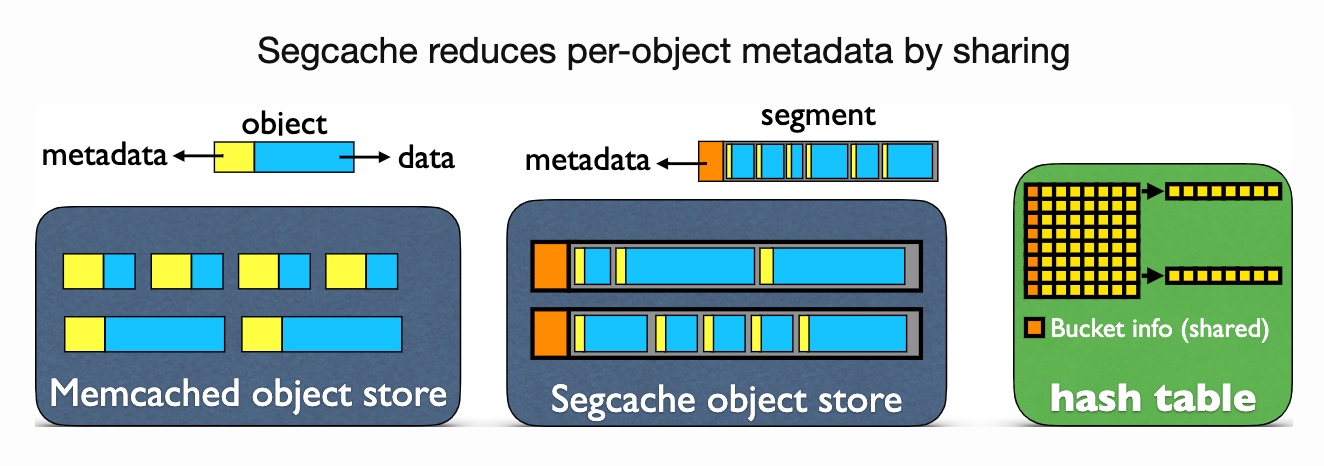
Yue Lu from Twitter, and collaborator Juncheng Yang and Rashmi from CMU. Pelikan (starting 2020), mostly written by Brian Martin(I really like his obsession to rust) is the current production in-memory cache for small data in twitter which is inspired by the traces captured with eBPF last year can do a smaller granularity analysis of memory cache.
EuroSys 22 Atendency

这次花了100💶。还是看看未来可能的合作者的文章长啥样。极其可恶的是我并没有被给予zoom权限,过了两天才拿到。
NSDI 22 Attendency

最终还是决定花这200🔪一睹世界最强Distributed System 长什么样。感觉整个Network的趋势就是当programmable switches & NICs 有计算能力以后,大家在尝试offload计算到端 。
[Program Analysis] Intraprocedural Analysis
CHA analysis is used to make too conservative assumptions to the method call in the Intraprocedural Analysis. All the results of the analysis should be. save. According to the Lattice Theory, the must and may analysis should be less precise. So the Interprocedural Analysis to see the data flow in the BB and the Call Graph to see the data flow propagation between functions and raise the precision of the analysis is very important.
Continue reading "[Program Analysis] Intraprocedural Analysis"
Inside the Nvidia Hopper Architecture

Nvidia has a lot of talented architects, like Michael Andersch and Gregg Palmer, to design GPU. But Grace is just a glued arm GPU, shameful! But I don't think the idea of launching Grace is just an armv9 CPU, Nvidia has integrated TEE, CCA, UCIe into the CPU, and NVLink C2C, which is great. Nvidia is for real good at turning all the tech into business.
Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning
A command line string to the class constructor.
There's the demand of passing a name and doing the class construction of this name. I don't want to make the switch case on the construct. Let's do the hack!
I found the base implementation in stackoverflow.
template <class T> void* constructor() { return (void*)new T(); }
struct factory
{
typedef void*(*constructor_t)();
typedef std::map<std::string, constructor_t> map_type;
map_type m_classes;
template <class T>
void register_class(std::string const& n)
{ m_classes.insert(std::make_pair(n, &constructor<T>)); }
void* construct(std::string const& n)
{
map_type::iterator i = m_classes.find(n);
if (i == m_classes.end()) return 0; // or throw or whatever you want
return i->second();
}
};
factory g_factory;
#define REGISTER_CLASS(n) g_factory.register_class<n>(#n)
The problem is it does not allow the arg passing in construction. My class accepts the arguments module.
template <class T, typename M_> void *constructor(M_ *module_) {
return (void *)new T{reinterpret_cast<M_ *>(module_)};
}
template <typename M_> struct arg_to_pass {
typedef void *(*constructor_t)(M_ *);
typedef std::map<std::string, constructor_t> map_type;
map_type m_classes;
M_ *module;
template <class T> void register_class(std::string const &n, M_ *&module_) {
module = module_;
m_classes.insert(std::make_pair(n, &constructor<T, M_>));
}
void *construct(std::string const &n) {
auto i = m_classes.find(n);
if (i == m_classes.end())
return nullptr; // or throw or whatever you want
return i->second(module);
}
};
arg_to_pass<Module> pass_factory;
#define REGISTER_CLASS(n, m_) pass_factory.register_class<n>(#n, m_)
This will resolve all the problem.
FusionFS: Fusing I/O Operations using $CISC_{Ops}$ in Firmware File Systems
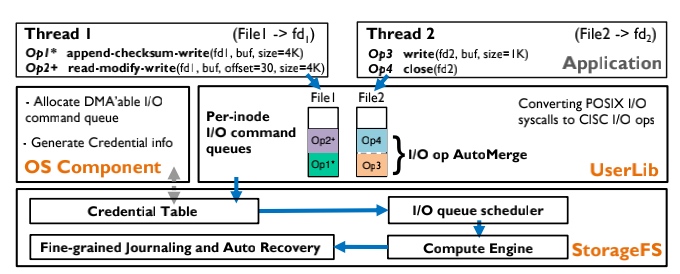
The paper is joined work between my upperclassman Jian Zhang who's currently taking Ph.D. at Rutgers.
Current Hw-Sw co-design
- Hardware Trend
- Design a fast path to reduce latency.
- Software Trend
- Do kernel bypass/zero-copy
Good
FusionFS comes up with aggregated I/O ops into $CISC_{Ops}$, the fuses and offloads data ops are carried out on the co-processor on storage. These higher throughputs are gained with assurance to the resource management fairness, crash consistency, and fast recovery.
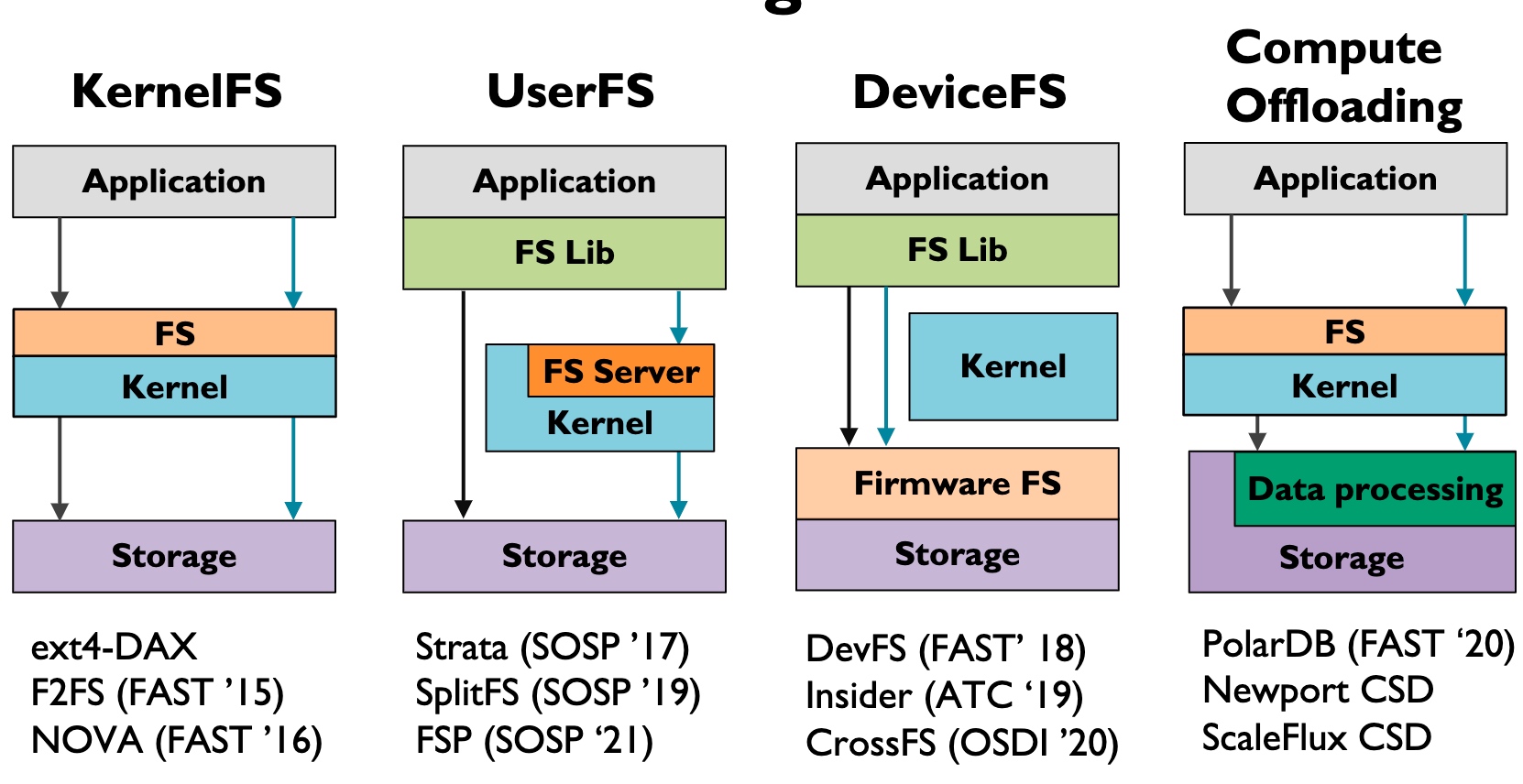
-
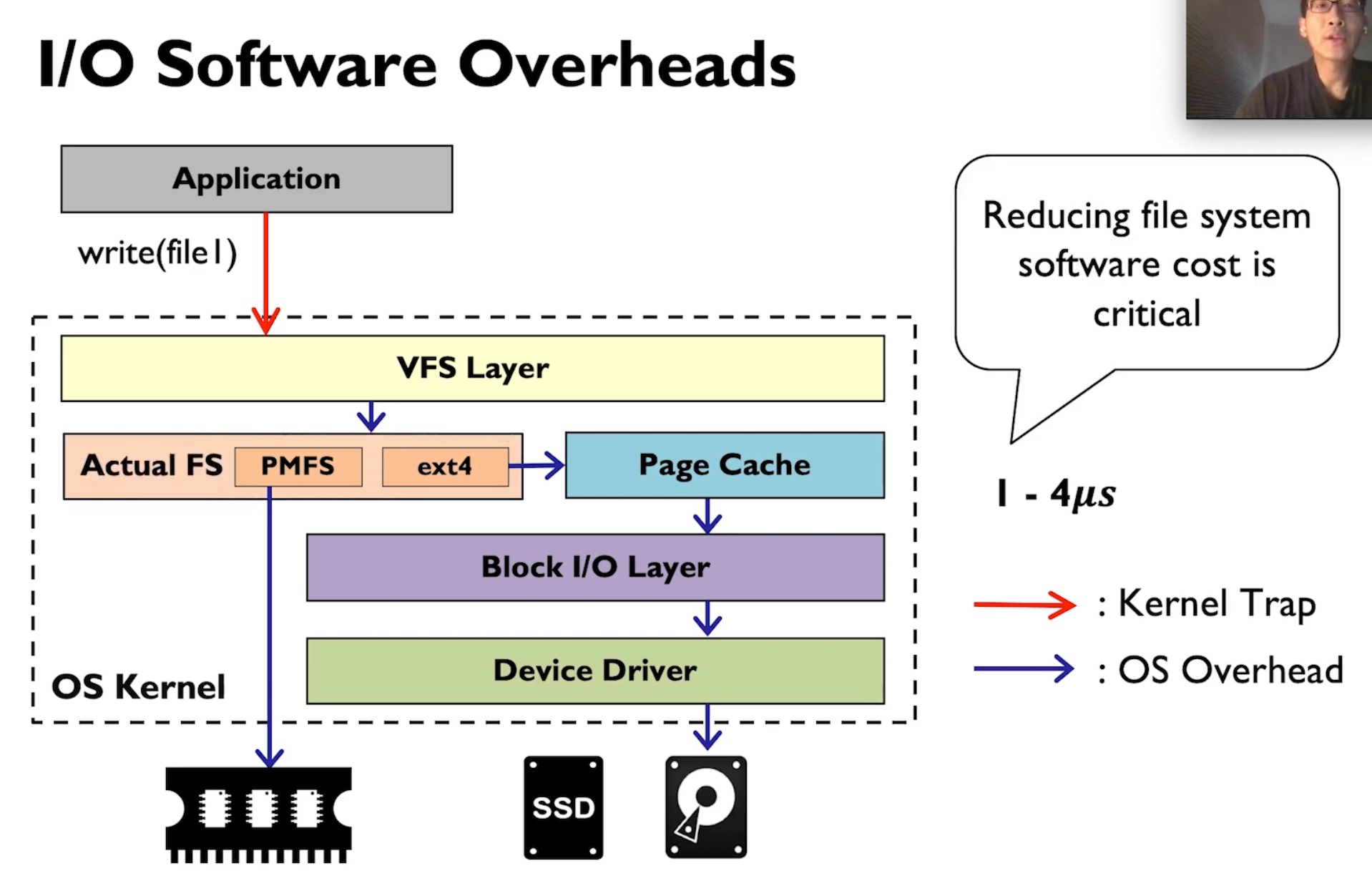
Kernel FS pushes all the W/R to the VFS Layer, this does not necessarily mean it's slow, often the time waiting for heavy-weighted Writeback, page cache is not hit, I/O queue locks waiting for the device ready, or deep VFS calls.
-
User FS may have some of the W/R intercepted and bypass the kernel. Some of the userspace semantic fusion is implemented using FUSE.
-
Device FS(Before CrossFS is Firmware FS) makes FS Lib directly call the firmware to wait until it can make DMA to memory.
- Good for Disaggregation & Concurrency throughput
- Mainly for NVM when speed is high, not applicable to SSDs
-
This paper used Compute Offloading, which is greatly applied in the SMartNIC. Storage plus the data processing makes transparent to the kernel, the kernel only needs to know some of the results is fused.
- write fusion
- read fusion
- data replacement for locality
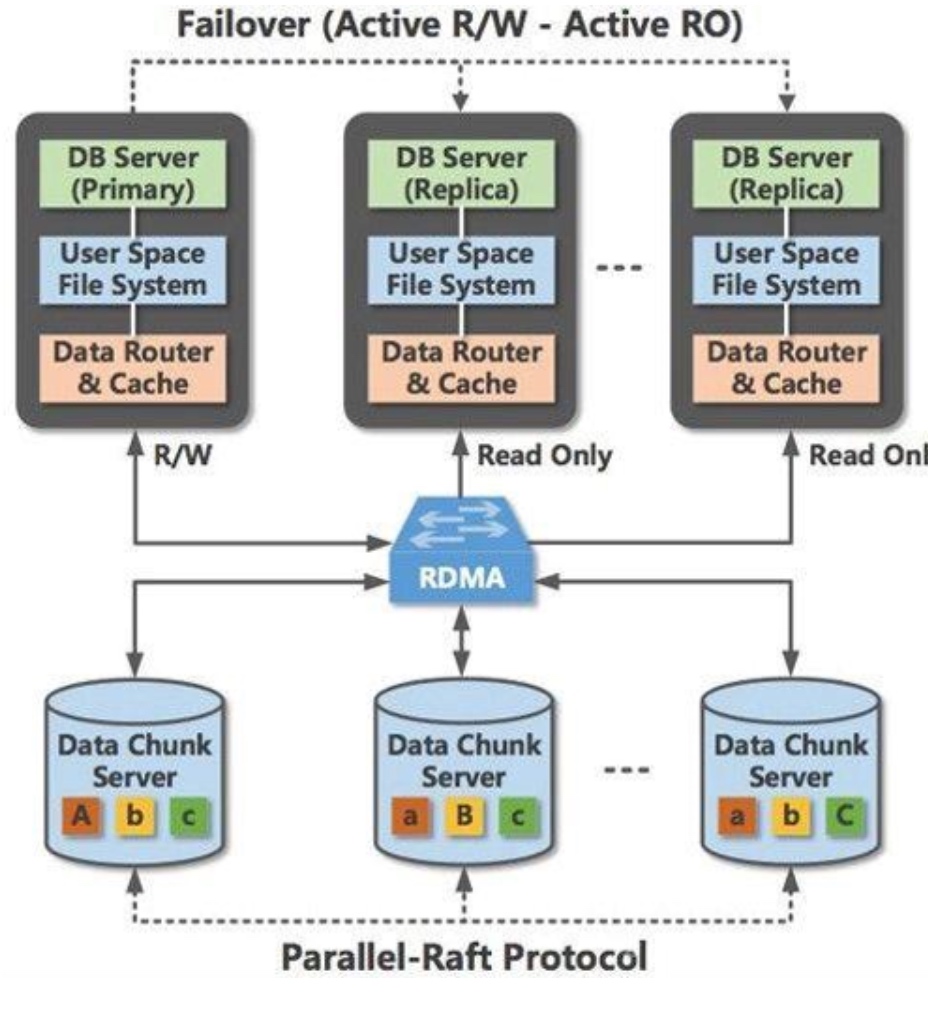
- PolarDB - PCIe layer compute offloading. I think it could be replaced by CXL.
-
crc-append interpreted into CISCops
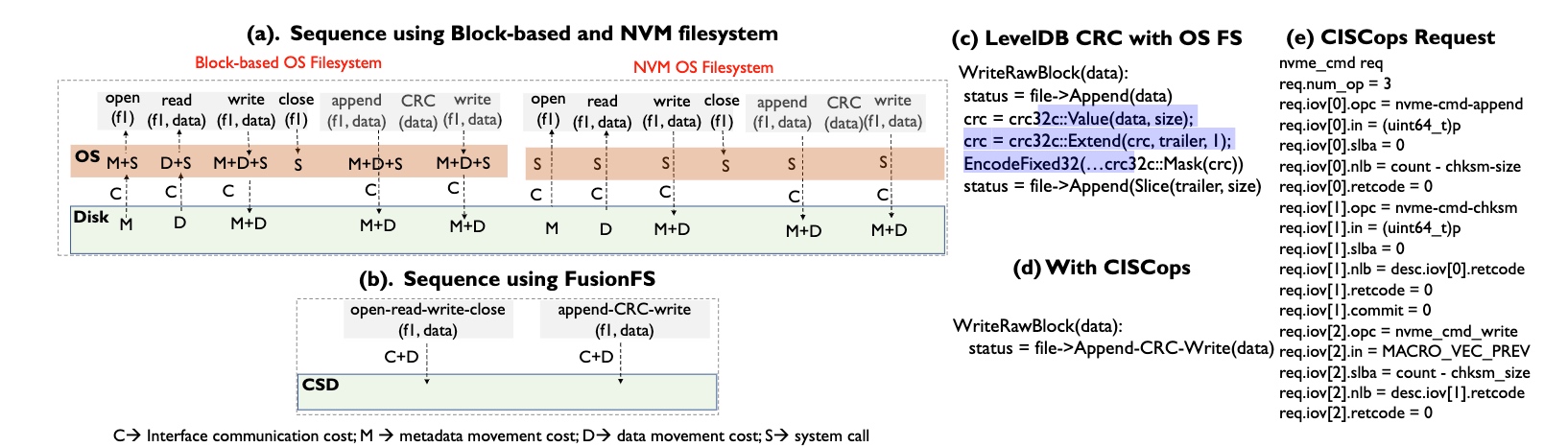 Basically, based on the predefined rules, the co-processor is able to fuse most of the data operations like LevelDB CRC, open read-write close.
Basically, based on the predefined rules, the co-processor is able to fuse most of the data operations like LevelDB CRC, open read-write close. -
CFS I/O scheduling.
-
Durability maintained by Micro Tx.
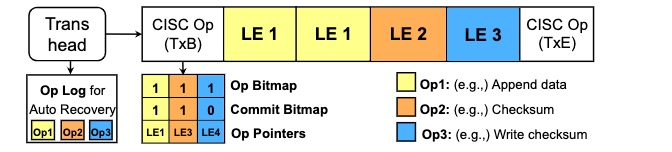
Bad
-
Large sequential data read/write will introduce preprocessor overhead, at least for data calculation and buffer store. Can pattern matching and make bypass the data processing.
-
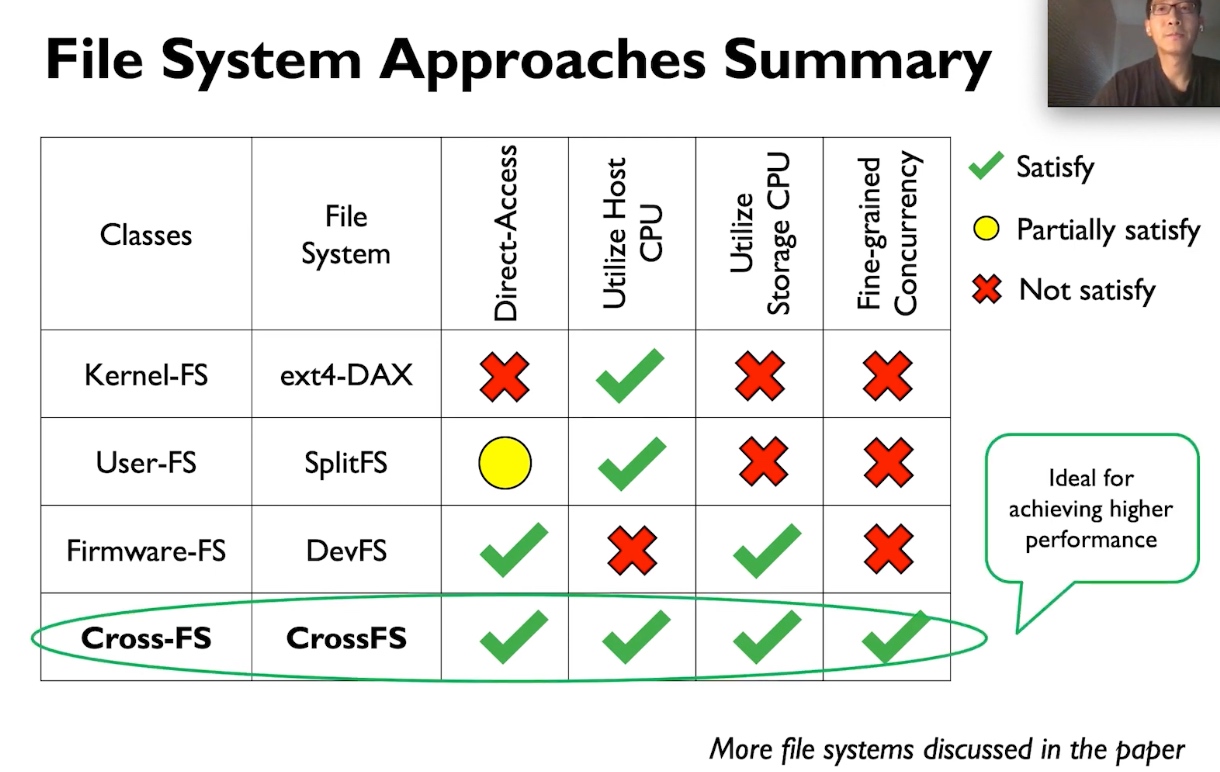
This paper shared a lot of similar designs with CrossFS for resource management, durability, and Permission checks.
-
 I'm curious why not implement the SSD main controller? It's meaningless to write on NVM because programmers must do handmade I/O fusion on such devices.
I'm curious why not implement the SSD main controller? It's meaningless to write on NVM because programmers must do handmade I/O fusion on such devices. -

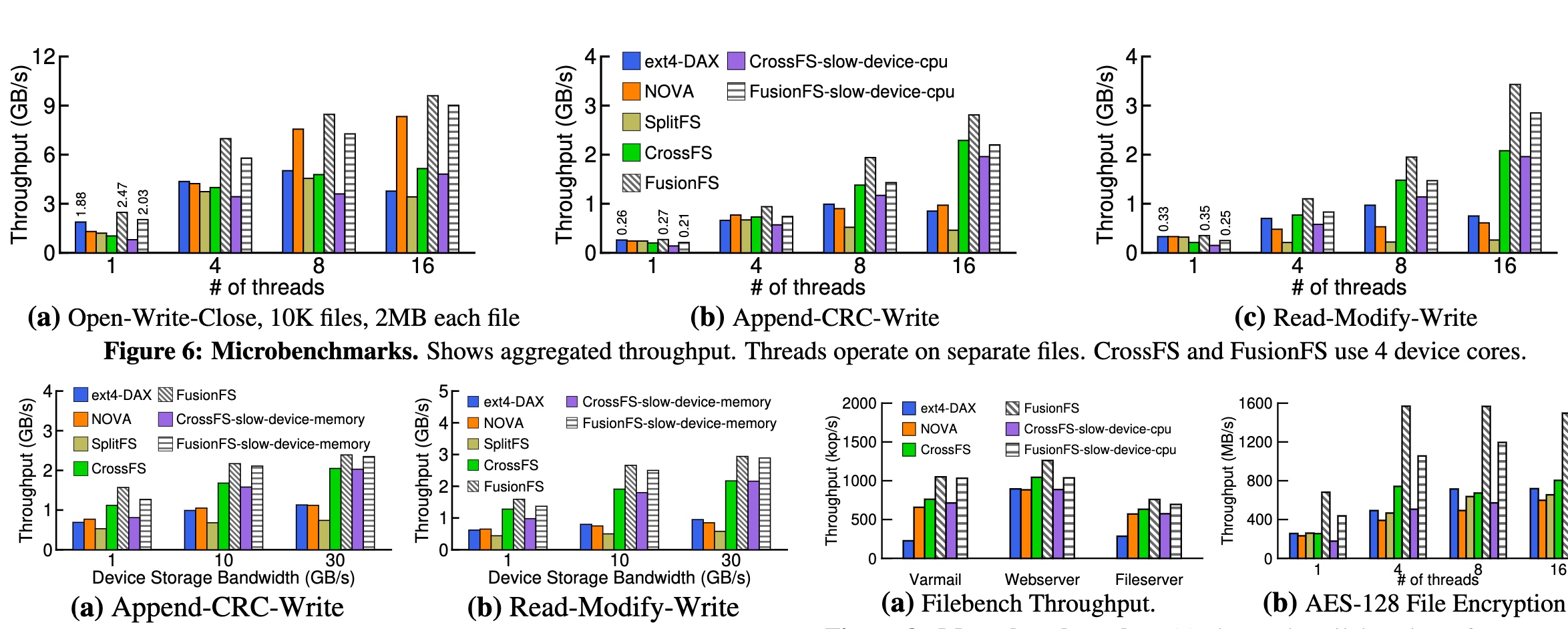 Performance is roughly the same with NOVA when with slow device CPU. I don't know if IO thread affinity and other kernel optimization are applied, the additional hardware has real benefits. However, the recovery speed is really quick because of MicroTx.
Performance is roughly the same with NOVA when with slow device CPU. I don't know if IO thread affinity and other kernel optimization are applied, the additional hardware has real benefits. However, the recovery speed is really quick because of MicroTx.
Refinement
- Still could apply kernel bypass over the FusionFS.
- SSD main controller/ Memory controller implementation is better than adding another CPU.
Reference
- POLARDB Meets Computational Storage: Efficiently Support AnalyticalWorkloads in Cloud-Native Relational Database
- CrossFS: A Cross-layered Direct-Access File System