

文章目录[隐藏]
最近听了 Hongzheng 大师的 alpa("all-parallel") talk,最近超算又正好在打 yuan(一个基于transfomer 改的),同时又在帮忙de ray 和 hoplite 的一些 bug。所以温习这篇 Ion Stoica 大师的论文。
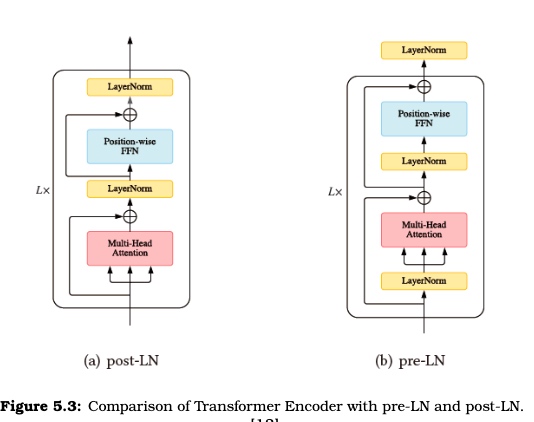
Data Parallelism vs. Model Parallelism.
需要大规模并行一个模型,有两种实现方法,数据并行和模型并行。
在前人的实践中已经有了
-
需要同时手动求解上述问题的工作,如 Megatron-LM。但如同 yuan 的调参一样,如果一个模型需要数天跑完,就需要花费更多时间移植和调参。
这样一个层数英文改中文+多加一些layer的Transformer LM模型也花了很多时间去做细粒度的 pipeline parallel。
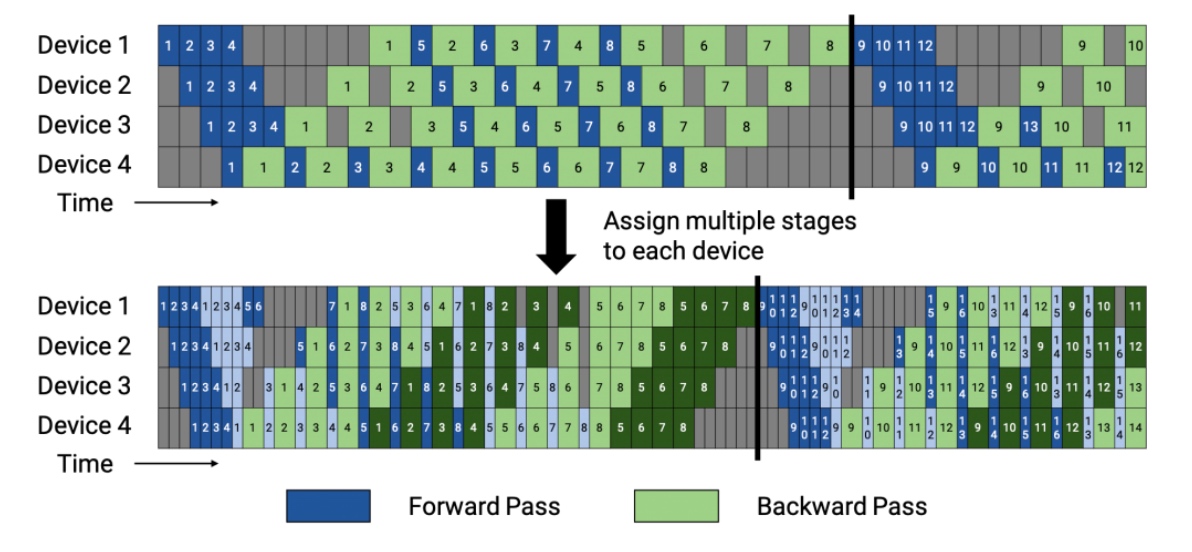
1F1B(一个 Post LM 的 layer 给定 Op 的情况下) 的 interleaved stages,其中每个设备被分配到多个阶段。第一阶段用深色表示,而第二阶段用浅色表示。第二阶段由浅色表示。由于阶段的数量增加了因为阶段的数量增加了一倍,所以需要更多的通信;然而,管道气泡的大小已经减少,所以需要更少的通信。但是,流水线气泡的大小减少了,所以需要更少的通信(在interleaved Timeline中,流水线冲刷发生得更快在interleaved Timeline中,假设通信忽略不计)。我们在yuan里面计算bubble cost的公式也比较粗糙bubble time fraction $=\frac{(p-1) \cdot\left(t_{f}+t_{b}\right)}{v}$。这其实增加了超参数的调整,需要一个静态分析模型,可以算出最优解的 Scheduler,支持NCCL等并行后端。
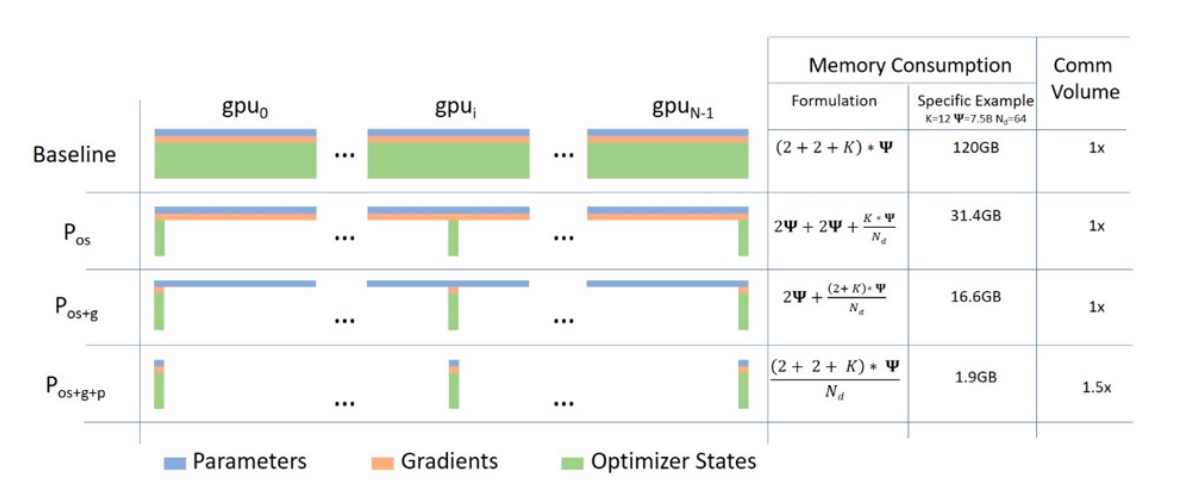
-
自动化求解并行化的其他工作没有兼顾Data/Op/Pipeline。而且三者不能同时考虑。
对于纯数据并行,有Zero Offload 这种强制把模型掐头去重复塞进GPU,再喂尽可能多batch的数据,为的是减少在小显存情况下能optimize Memory 和 Gradient。

Code & Experiment
- 考虑cost model hierarchy 和模型的特性进行划分。
- 考虑算子内并行和算子间并行的带宽分布,也即是简单流水线算法即可求解。

在实现中还是有XLA对模型的summary信息收集,cluster cost的收集,使用 XLA marker 做 pipeline 计算
namespace kernel {
void pipelineMarker(cudaStream_t stream, void **buffers, const char *opaque, size_t opaque_len) {
const int64_t *sizes = reinterpret_cast<const int64_t *>(opaque);
size_t n_inputs = opaque_len / sizeof(int64_t);
for (size_t i = 0; i < n_inputs; i++) {
const float *input = reinterpret_cast<const float *>(buffers[i]);
float *output = reinterpret_cast<float *>(buffers[i + n_inputs]);
cudaMemcpy(output, input, sizes[i], cudaMemcpyDeviceToDevice);
}
}
void identity(cudaStream_t stream, void **buffers, const char *opaque, size_t opaque_len) {
}
最后使用 jax 做 jit, xla instrumentation。
hierarchy的求解先pipeline后算子最后放数据。下面是pipeline的结果:
"""
Generate a Gpipe-like schedule.
Note that here we always assume num_pipeline_workers = num_stage / 2.
The schedule will look like below:
i: index of micro-batch
j: index of partition/device
k: clock number
k (i,j) (i,j) (i,j)
- ----- ----- -----
0 (0,0)
1 (1,0) (0,1)
2 (2,0) (1,1) (0,2)
3 (2,1) (1,2)
4 (2,2)
5 reverse...
"""
sharding 用的还是 XLA 的 sharding pass
"""Use the auto sharding pass in XLA.
The compilation passes and status of an HloModule:
UNOPTIMIZED
|
| pre_spmd_partitioner passes
|
| auto_sharding pass
V
SHARDING_ANNOTATED
|
| spmd partitioner pass
V
SPMD_PARTITIONED
|
| post_spmd_partitioner passes
V
FULLY_OPTIMIZED
"""
其他的算子优化及GPU Affinity论文
Astitch & Ansor
做算子 Fusion 和 Stitch 还有 SIMT 架构其他的小 trick。能中也是单纯改XLA不能完成自动化地为大粒度的复杂访存密集算子子图生成高效的GPU代码,还是写个compiler发asplos比较好。一作是交大xBerkeleyx阿里的。

Achieving μs-scale Preemption for Concurrent GPU-accelerated DNN Inferences.
这篇是按照 AMD Driver 改的 GPU code,做推理优化的affinity。还没放,先不写了。