去是去不了了, 但是还是看了一下paper list.然后发现只要去就能提前看到paper list,这种传统还挺有意思的。
MICRO attendency



A Tech Nerd with a finance mind.
去是去不了了, 但是还是看了一下paper list.然后发现只要去就能提前看到paper list,这种传统还挺有意思的。
I was writing a rust version of tokio-rs/io-uring together with @LemonHX. First, I tried the official windows-rs trying to port the Nt API generated from ntdll. But it seems to be recurring efforts by bindgen to c API. Therefore, I bindgen from libwinring with VLDS generated.
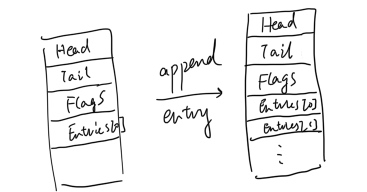
Original struct, the flags should not be 0x08 size big. I don't know it's a dump bug or something.
typedef struct _NT_IORING_SUBMISSION_QUEUE
{
/* 0x0000 */ uint32_t Head;
/* 0x0004 */ uint32_t Tail;
/* 0x0008 */ NT_IORING_SQ_FLAGS Flags; /*should be i32 */
/* 0x0010 */ NT_IORING_SQE Entries[];
} NT_IORING_SUBMISSION_QUEUE, * PNT_IORING_SUBMISSION_QUEUE; /* size: 0x0010 */
static_assert (sizeof (NT_IORING_SUBMISSION_QUEUE) == 0x0010, "");
The above struct should be aligned as:
Generated struct
#[repr(C)]
#[derive(Default, Clone, Copy)]
pub struct __IncompleteArrayField<T>(::std::marker::PhantomData<T>, [T; 0]);
impl<T> __IncompleteArrayField<T> {
#[inline]
pub const fn new() -> Self {
__IncompleteArrayField(::std::marker::PhantomData, [])
}
#[inline]
pub fn as_ptr(&self) -> *const T {
self as *const _ as *const T
}
#[inline]
pub fn as_mut_ptr(&mut self) -> *mut T {
self as *mut _ as *mut T
}
#[inline]
pub unsafe fn as_slice(&self, len: usize) -> &[T] {
::std::slice::from_raw_parts(self.as_ptr(), len)
}
#[inline]
pub unsafe fn as_mut_slice(&mut self, len: usize) -> &mut [T] {
::std::slice::from_raw_parts_mut(self.as_mut_ptr(), len)
}
}
#[repr(C)]
#[derive(Clone, Copy)]
pub struct _NT_IORING_SUBMISSION_QUEUE {
pub Head: u32,
pub Tail: u32,
pub Flags: NT_IORING_SQ_FLAGS,
pub Entries: __IncompleteArrayField<NT_IORING_SQE>,
}
The implemented __IncompleteArrayField seems right for its semantics of translating with slice and ptr. However, when I called the NtSubmitIoRing API, the returned data inside Field is random same result no matter moe the fiel d for what distance of Head.
在LLVM上用concolic exuction拿到DFG path feed 给fuzzer和santinizer。算法上有很多剪枝优化。还在看实现。
For the HPC system, prefetching both hw/sw requires sophisticated simulation and measurement to perform better.
The purpose of the author is because first, there is not much explanation of how best to insert prefetch intrinsic. Second, not a good understanding of the complex interactions between hardware prefetching and software prefetching.
The target of soft prefetching is found to be short array streams, irregular memory address patterns, L1 cache miss reduction. There is a positive effect, however, since software prefetching trains hardware prefetching, a further part of the situation is a bad effect. Since stream and stride prefetchers are the only two currently implemented commercially, our hardware prefetching strategies are restricted to those.
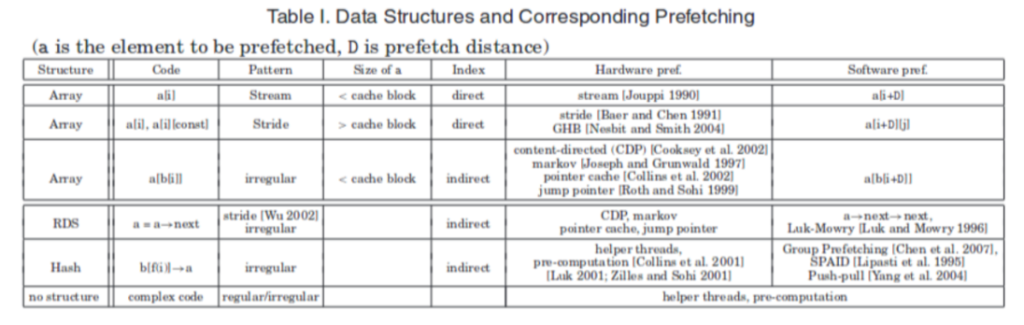
As the picture depicted above, the software can easily anticipate array accesses and prefetch data in advance. Stream means accessing data across a single cache line while stride means accessing across more than two cache lines.
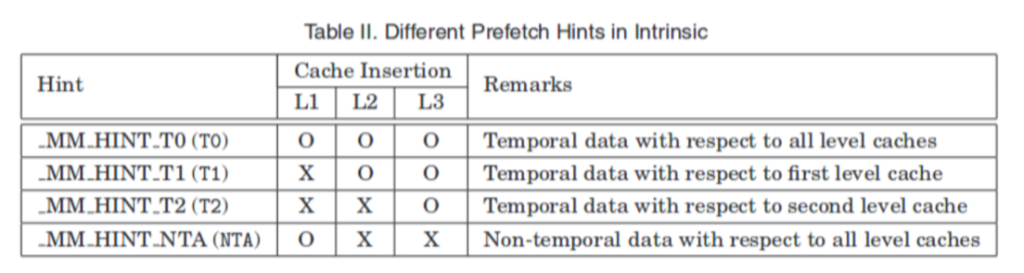
For Software Prefetch Intrinsics, temporal for the use of the data to be used again, so the next layer still have to put, such as L1 have to put L2, L3 are put, so that when the data is kicked out of the L1 cache can still be loaded from L2, L3 and None - temporal for the use of the data no longer used, so L1 put on the good, was kicked out will not be loaded from L2, L3.

In the software prefetch distance graph, prefetching data too early will make the data stay in the cache for too long, and the data will be kicked out of the cache before it is really used, while prefetching data too late causes cache miss latency to occur. The equation $D \geq \left. \ \left\lceil \frac{l}{s} \right.\ \right\rceil$ shows, where l is prefetch latency, and s is the length of the shortest path through the loop body. When D (D is a[i+D] of table) is large enough to cover the cache miss latency but when D is too large it may cause the prefetch to kick out useful data from the cache and the beginning of the array may not prefetch which may cause more cache misses
Indirect memory indexing is dependent on software calculation, so we expect software prefetch will be more effective than hardware prefetch.
Hardware-baselined prefetch mechanism has a stream, GHB, and contend-based algorithm.
The good point of soft prefetch that outweighs hardware prefetch is a large number of streams
short streams, irregular Memory Access, Cache Locality Hint, and possible Loop Bounds. However, the negative impacts of software prefetching lie in increased instruction count because, it actually requires more instruction to calculate the memory offset, static insertion without adaptivity, and code structure change. For antagonistic effects, both of them have negative training and may be harmful to the original program.
In the evaluation part, the author first introduced the prefetch intrinsic insertion algorithm which first quantitatively measured the distance by IPCs and memory latency. The method has been used in C++ static prefetcher. Second, the author implemented different hardware prefetchers by MacSim and use the different programs in SPEC 2006 and compilers icc/gcc etc. to test the effectiveness of those prefetchers. They found one of the restrictions is typically thought to be the requirement to choose a static prefetch distance, The primary metric for selecting a prefetching scheme should be coverage. By using this metric, we can see that data structures with weak stream behavior or regular stride patterns are poor candidates for software prefetching and may even perform worse than hardware prefetching. In contrast, data structures with strong stream behavior or regular stride patterns are good candidates for software prefetching.
用LegoOS和Linux的不同性能对比得出了未来DBMS disaggregation 怎么设计。
FAAS对resource(CPU/Memory) disaggregation的map-reduce化?这显然是一个完全不考虑NUMA/NIC latency的考虑,就是在说dynamic memory allocation/placement大过latency的tradeoff,重点落在了怎么藏RDMA/NUMA的时延.但是为什么要套一个FAAS呢?然后就和MemTrade没啥大区别,只是多家了一套用户配置.
Both of the papers are from Dimitrios
Because the memory occupation on a single node is huge, we are required to offload them into far memory.
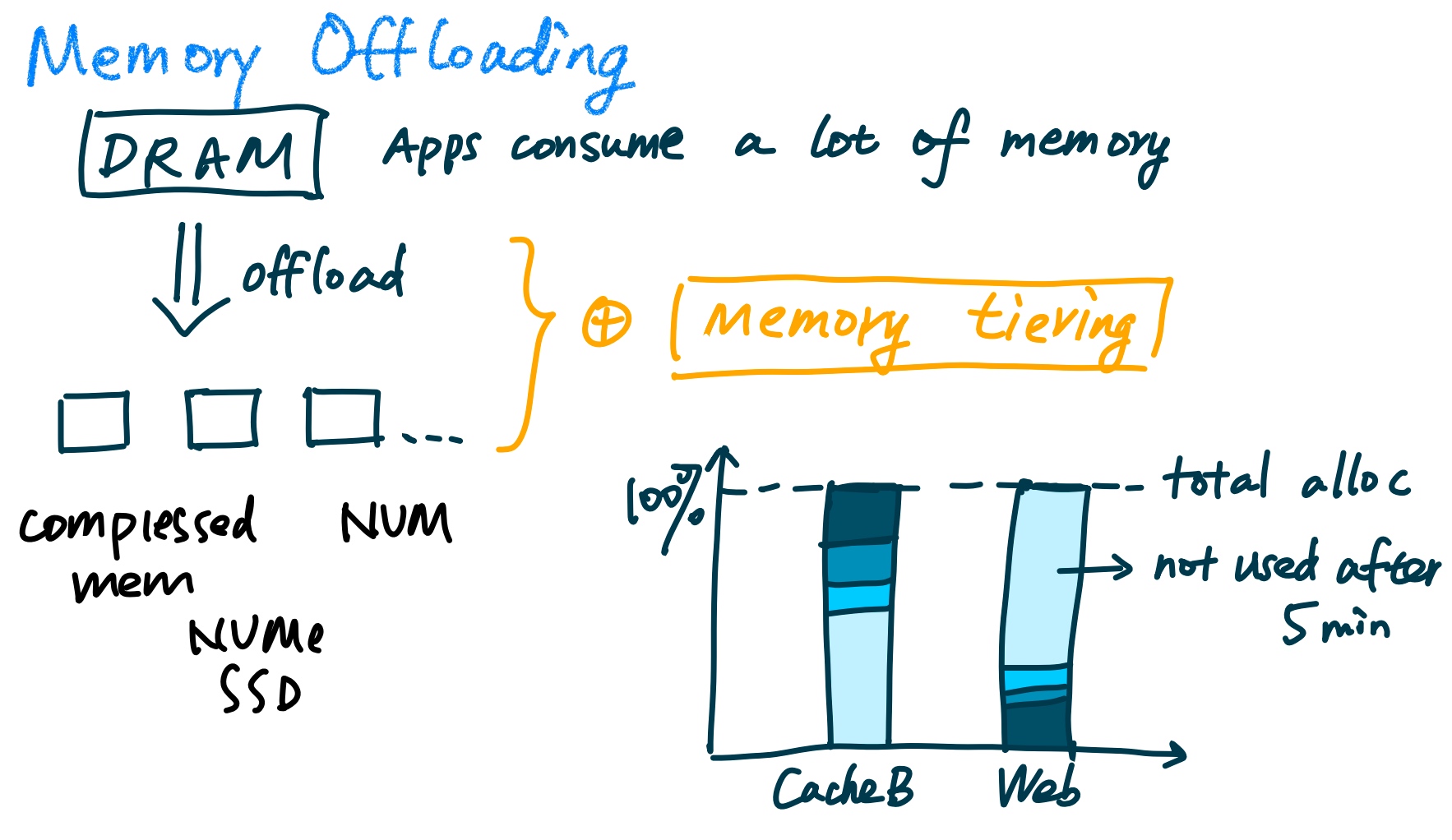
They have to model what the memory footprint is like. And what's shown in the previous work zswap, it only has a single slow memory tier with compressed memory and they only have offline application profiling, which the metric is merely page-promotion rate.
Memory Tax comes can be triggered by infrastructure-level functions like packaging, logging, and profiling and microservices like routing and proxy. The primary target of offloading is memory tax SLA.
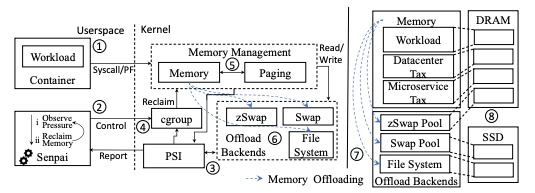
TMO basically sees through the resulting performance info like pressure stall info to predict how much memory to offload.
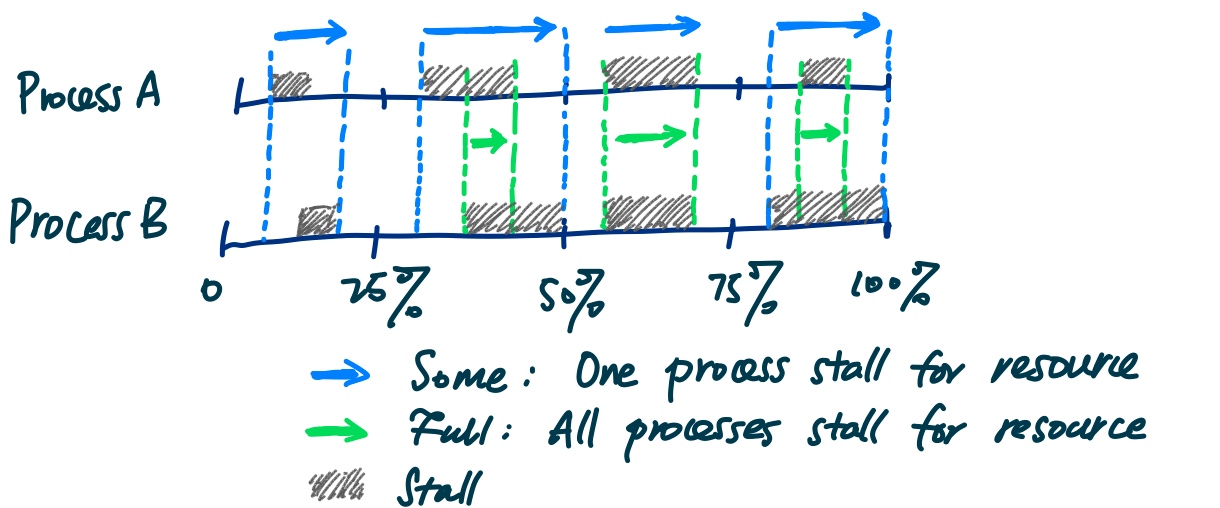
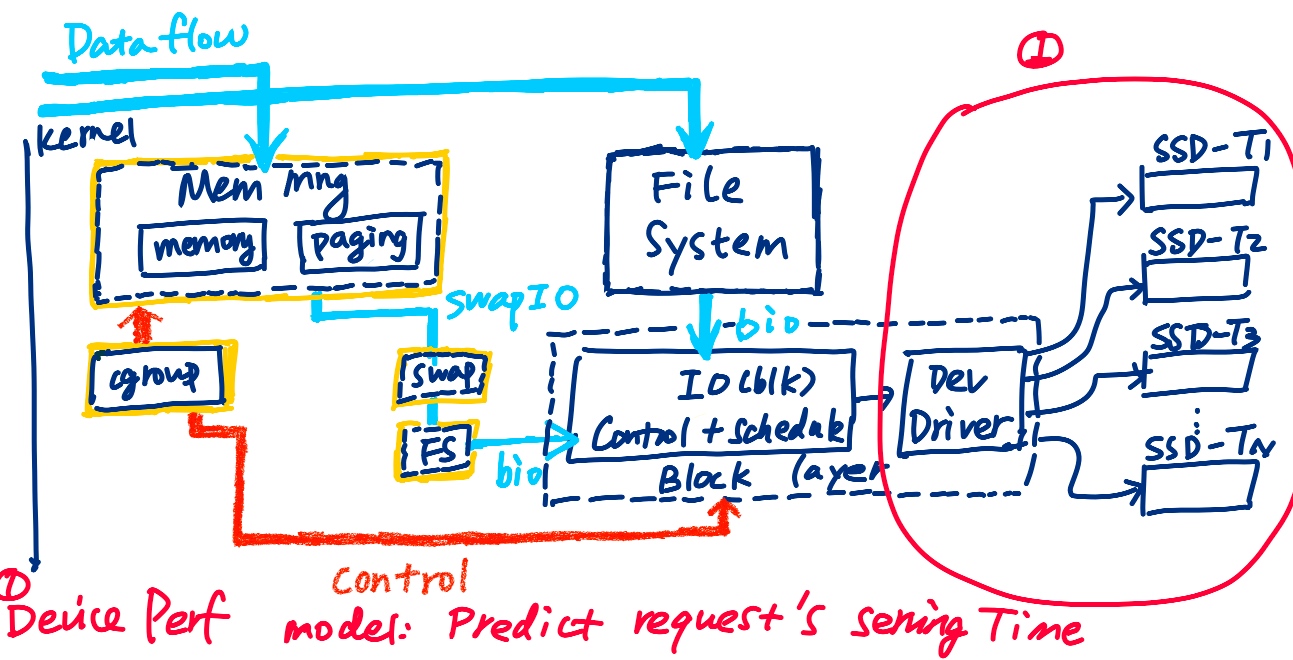
Then they use the PSI tracking to limit the memory/IO/CPU using cgroup, which they called Senpai.
IOCost reclaims not frequently used pages to SSD.