习题课 - 1A106 - 周一8-9
关系型数据库
- 容器存储关系的集合
- Relation
- schema - fixed
- Instance - change often
- Tuple
- Attribute
- DDL
- Sailor

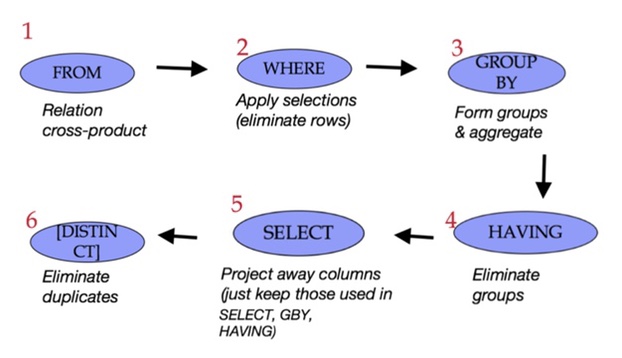
Group by 聚合函数或select
- DML
SELECT S.dept, AVG(S.gpa), COUNT(\*) FROM Students S
WHERE S.gender = 'F'
GROUP BY S.dept
HAVING COUNT(\*) >= 2 ORDER BY S.dept;
Distinct Aggregate
SELECT COUNT(**DISTINCT** S.name)
FROM Students S
WHERE S.dept = 'CS';
2
SELECT **DISTINCT** COUNT(S.name)
FROM Students S
WHERE S.dept = 'CS';
10
e.g
SELECT S.name, AVG(S.gpa)
FROM Students S
GROUP BY S.dept;
name has multiple of them. Should be S.name or coercion function
SUMMARY for SQL1
- Relational model has well-defined query semantics
- Modern SQL extends “pure” relational model (some extra goodies for duplicate row, non-atomic types... more in next lecture)
- Typically, many ways to write a query
- DBMS figures out a fast way to execute a query, regardless of how it is written.
DML 多表
SELECT [DISTINCT]
FROM <single table>
[WHERE <predicate>]
[GROUP BY <column list>
[HAVING <predicate>] ] [ORDER BY <column list>] [LIMIT <integer>];
select - collection
join Queries 链接查询
SELECT [DISTINCT] <column expression list>
FROM <table1 [AS t1], ... , tableN [AS tn]>
[WHERE <predicate>]
[GROUP BY <column list>[HAVING <predicate>] ] [ORDER BY <column list>];
cross(Catesian) product
All pairs of tuples, concatenated
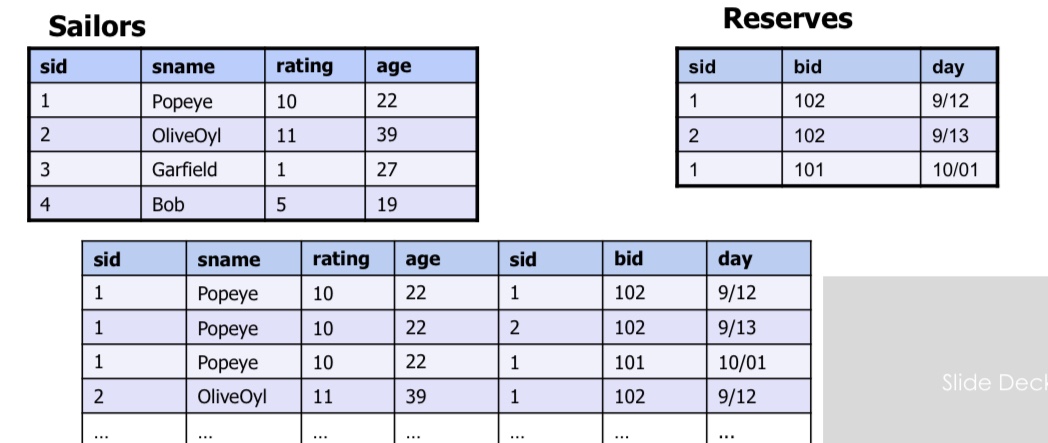
Use where to filter - 有预约记录的信息
SELECT S.sid, S.sname, R.bid
FROM Sailors AS S, Reserves AS R
WHERE S.sid=R.sid #外键==内键
先找到再去除,先行后列
AS is column Name and Table Aliases
self-join

AS can be used as the product's col name.
In a must in this case
Arithmetic Expression
SELECT S.age, S.age-5 AS age1, 2*S.age AS age2
FROM Sailors AS S
WHERE 2*S.age = S2.age - 1
SQL calculator
SELECT
log(1000) as three,
exp(ln(2)) as two,
cos(0) as one,
ln(2*3) = ln(2) + ln(3) as sanity;
4 - 1
string comparisons
Old School SQL (Like)
SELECT S.sname
FROM Sailors S
WHERE S.sname LIKE 'B_%’
Standard Regular Expressions
SELECT S.sname
FROM Sailors S
WHERE S.sname ~ 'B.*’
combining Predicates
Subtle connections between:
- Boolean logic in WHERE (i.e., AND, OR)
- Traditional Set operations (i.e. INTERSECT, UNION)
Sid’s of sailors who reserved a red OR a green boat.
SELECT R.sid
FROM Boats B, Reserves R
WHERE R.bid=B.bid AND (B.color='red' OR B.color='green')
Sid’s of sailors who reserved a red AND a green boat.
SELECT R.sid
FROM Boats B, Reserves R
WHERE R.bid=B.bid AND B.color='red'
UNION ALL
SELECT R.sid
FROM Boats B, Reserves R
WHERE R.bid=B.bid AND B.color='green'
UNION ALL ~ OR set operation
INTERSECT ~ AND set operation
set semantics
- Set: acollection of distinct elements
- Standard ways of manipulating / combining sets
- Treat tuples within a relation as elements of a set
Default to set semantics
Relational tables
| SQL |
Relation |
| Set/Multiset |
Set |
| ordering |
non-order |
Table is just the interpretation of the relation.
Distinct
\(A=<x,y>\)
\(B=<y>\)
\(A/B=<x>\)
Relational Division: “Find sailors who’ve reserved all boats.” Said differently: “sailors with no counterexample missing boats”
SELECT S.sname FROM Sailors S WHERE NOT EXISTS
(SELECT B.bid
FROM Boats B
WHERE NOT EXISTS (SELECT R.bid
FROM Reserves R WHERE R.bid=B.bid AND R.sid=S.sid ))
ARGMAX
max's other property
SELECT *
FROM Sailors S WHERE S.rating >= ALL
(SELECT S2.rating FROM Sailors S2)
SELECT *
FROM Sailors S WHERE S.rating =
(SELECT MAX(S2.rating) FROM Sailors S2)
both are okay, the second is not stable and does not produce 并列。
INNER JOIN
减少cross product 的and
SELECT s.*, r.bid
FROM Sailors s, Reserves r WHERE s.sid = r.sid
AND ...
SELECT s.*, r.bid
FROM Sailors s INNER JOIN Reserves r ON s.sid = r.sid
WHERE ...
join variable
SELECT <column expression list> FROM table_name
[INNER | NATURAL
| {LEFT |RIGHT | FULL } {OUTER}] JOIN
table_name
ON <qualification_list> WHERE ...
The shadowed manifest list capacity.
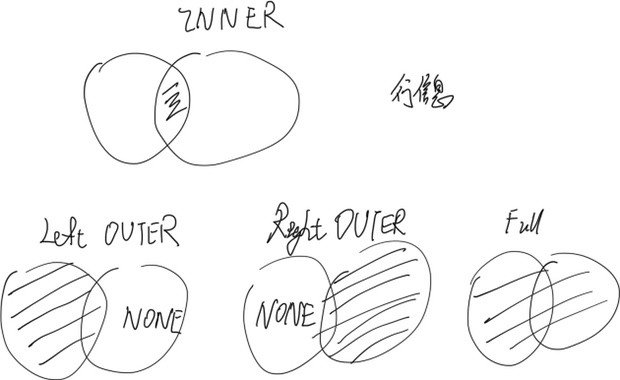
Left Outer join
SELECT s.sid, s.sname, r.bid
FROM Sailors2 s LEFT OUTER JOIN Reserves2 r
ON s.sid = r.sid;
不匹配赋NULL
行数和sailor一样
SELECT r.sid, b.bid, b.bname
FROM Reserves2 r RIGHT OUTER JOIN Boats2 b
ON r.bid = b.bid
不匹配赋NULL
行数和boat一样
NATURAL & INNER
SELECT s.sid, s.sname, r.bid FROM Sailors s, Reserves r WHERE s.sid = r.sid
AND s.age > 20;
SELECT s.sid, s.sname, r.bid
FROM Sailors s INNER JOIN Reserves r ON s.sid = r.sid
WHERE s.age > 20;
SELECT s.sid, s.sname, r.bid
FROM Sailors s NATURAL JOIN Reserves r WHERE s.age > 20;
Equal, natural 只输出on 行成立的部分
FULL OUTER JOIN
「s.bname」不存在它置为NULL
「b.name, b.bid」不存在它置为NULL
Views
Named Queries
- Makes development simpler
- Often used for security
- Not Materialized
CREATE VIEW Redcount
AS SELECT B.bid, COUNT(*) AS scount FROM
Boats2 B, Reserves2 R
WHERE R.bid=B.bid AND B.color='red' GROUP BY B.bid
Subqueries in FROM
Like a “view on the fly”!
SELECT bname, scount FROM Boats2 B,
(SELECT B.bid, COUNT (*)
FROM Boats2 B, Reserves2 R
WHERE R.bid = B.bid AND B.color = 'red' GROUP BY B.bid) AS Reds(bid, scount)
WHERE Reds.bid=B.bid AND scount < 10
Common table experssion (WITH)
another view on the fly
WITH Reds(bid, scount) AS
(SELECT B.bid, COUNT (*)
FROM Boats2 B, Reserves2 R
WHERE R.bid = B.bid AND B.color = 'red' GROUP BY B.bid)
ARGMAX GROUP BY
The sailor with the highest rating per age
WITH maxratings(age, maxrating) AS (SELECT age, max(rating)
FROM Sailors
GROUP BY age)
SELECT S.*
FROM Sailors S, maxratings m
WHERE S.age = m.age
AND S.rating = m.maxrating;
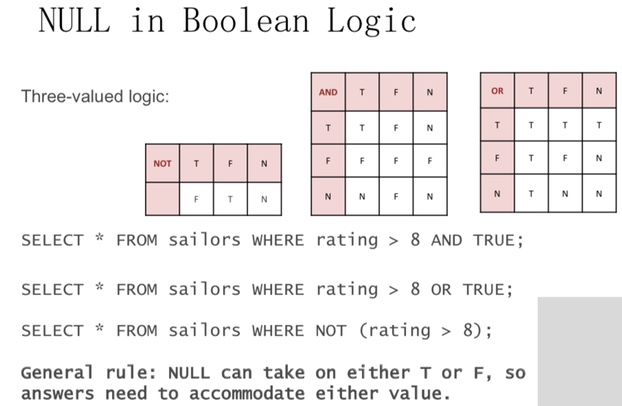
NULL values
- Field values are sometimes unknown
– SQL provides a special value NULL for such situations.
– Every data type can be NULL
- The presence of null complicates many issues. E.g.:
– Selection predicates (WHERE)
– Aggregation
- But NULLs comes naturally from Outer joins
NULL op x is NULL
Explicit NULL checks
SELECT * FROM sailors WHERE rating IS NOT NULL;
if NULL is after WHERE, it will not output
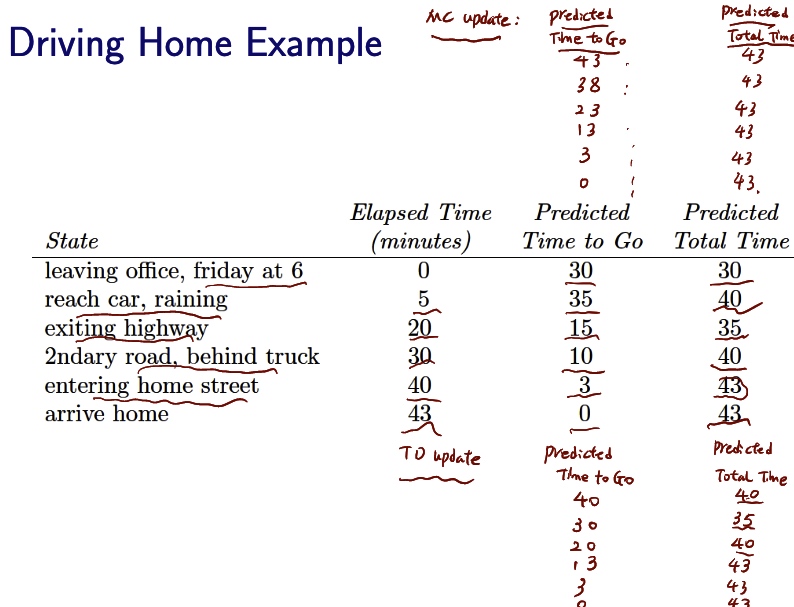
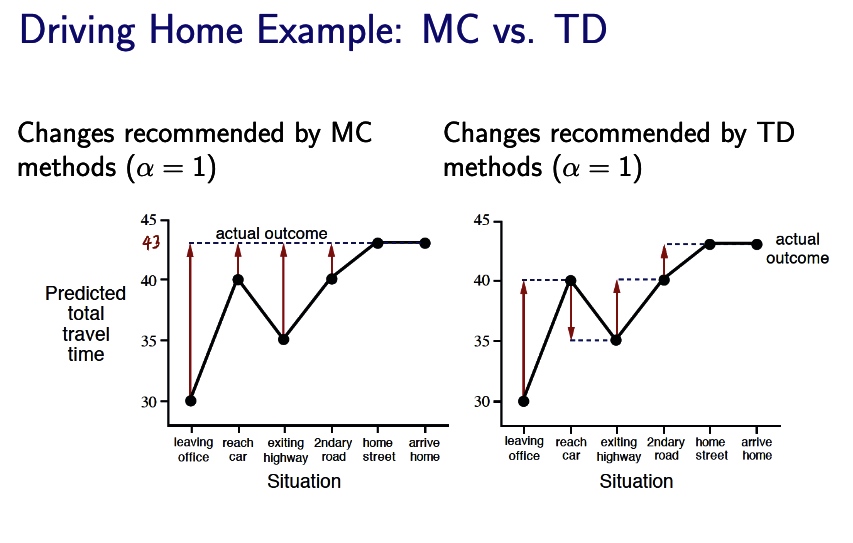
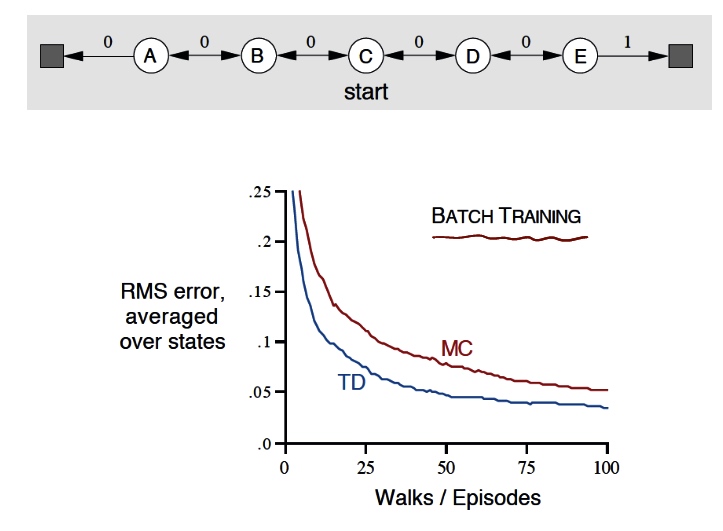
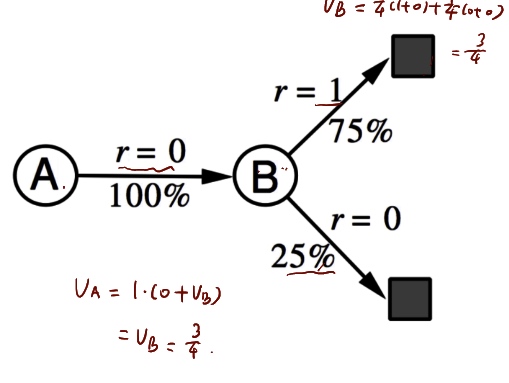
NULL and Aggregation


















 \(\to\)
\(\to\)