lab0
snipher
指令怎么处理,的到trace
report gradescope
HW1
2 week 4 ques
Paper reading
one compulsory and one optional
ISA
Stack and accumulator
Stack vs. Accumulator(implicitly)
e.g. C \(\leftarrow\) A + B
| Stack | Accumulator | GPR | GPR |
|---|---|---|---|
| Push A | Load A | Load R1, A | Load R1, A |
| Push B | Add B | Add R3, R1, B | Load R2, B |
| Add | Store C | Store R3, C | |
| Pop C |
Stack: no register, but stack
- Pros
- Simple Model of expression evaluation (Reverse Polish Notation)
- Short instruction, i.e., push, pop, etc.
- Cons
- Stackcan‘tberandomlyaccessed
- Stack accessed every operation, to be a bottleneck
Accumulator: one register, i.e., accumulator
- Pros
- Shortinstructions
- Cons
- Accumulator is only temporary storage, thus with high memory traffics.
CISC vs. RISC
- CISC
- Complex instruction set computer • Rep: x86
- RISC
- Reduced instruction set computer • Reps: RSIC-V, MIPS, SPARC
- Main features of RISC, in contrast to CISC
- A large number of registers and a highly regular instruction pipeline, allowing a low number of clock cycles per instruction (CPI) for high throughput
- SPARC and RISC-V both with 32 general-purpose integer registers
- X86, 8 general-purpose integer registers
- Uniform instruction format
- Load-store architecture
- Only load and store instruction can access memory
- A large number of registers and a highly regular instruction pipeline, allowing a low number of clock cycles per instruction (CPI) for high throughput
Hardwired vs. Microcoded
- Microcoded control (PLA)
- Implemented using ROMs/RAMs
- Indirect next_state function: “here’s how to compute next state”
- Slower ... but can do complex instructions
- Multi-cycle execution (of control)
- Hardwired control
- Implemented using logic (“hardwired” can’t re-program)
- Direct next_state function: “here is the next state”
- Faster ... for simple instructions (speed is function of complexity)
- Single-cycle execution (of control)
Why Microcode
How RISC to CISC and then to RISC
Control vs. Datapath
control can be split between datapath, where numbers are stored and arithmetic operations computed and control, which sequences operations on datapath.
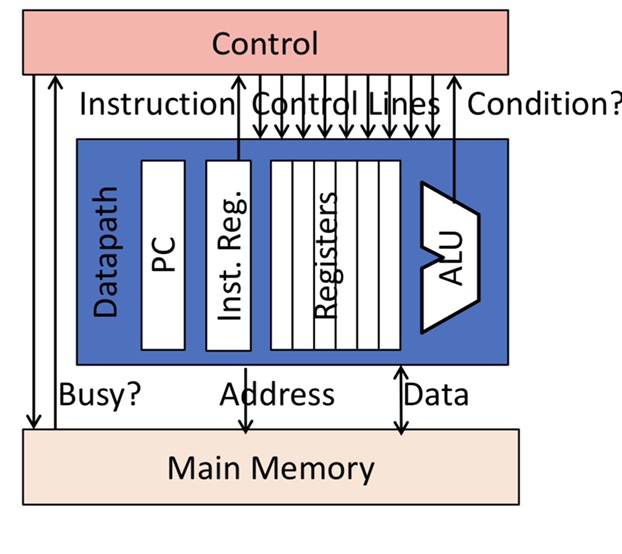
Single-Bus Datapath for Mircrocoded RISC-V
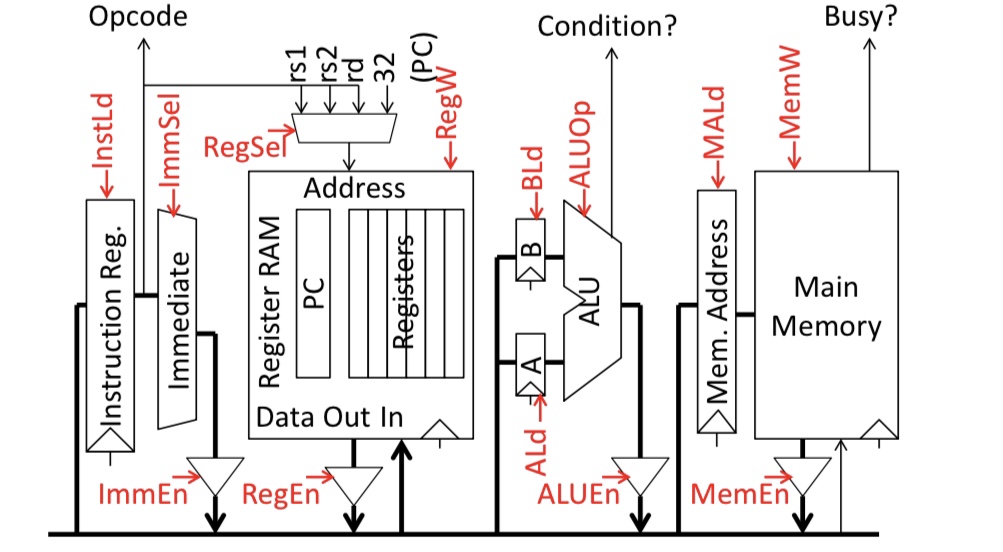
Microinstructions written as register transfers:
- MA:=PC means RegSel=PC; RegW=0; RegEn=1; MALd=1
- B:=Reg[rs2] means RegSel=rs2; RegW=0; RegEn=1; BLd=1
- Reg[rd]:=A+B means ALUop=Add; ALUEn=1; RegSel=rd; RegW=1
Microcode Sketches
Instruction Fetch:
- MA,A:=PC
- PC:=A+4
- wait for memory
- IR:=Mem
- dispatch on opcode
Pure Rom Implementation
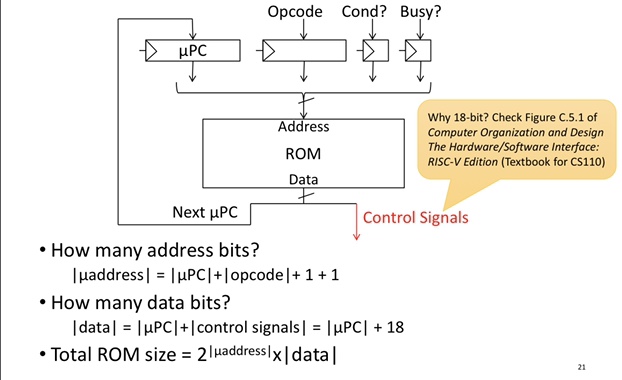
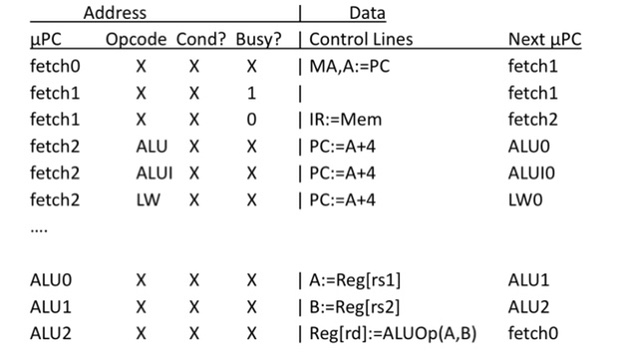
- Instruction fetch sequence 3 common steps
- ~12 instruction groups
- Each group takes ~5 steps (1 for dispatch)
- Total steps 3+12*5 = 63, needs 6 bits for µPC
- Opcode is 5 bits, ~18 control signals
- Total size = \(2^{6+5+2}*(6+18)=2^{13}*24 = ~25KiB\)!
Reduce Control Store Size
- Reduce ROM height (#address bits)
- Use external logic to combine input signals
- Reduce #states by grouping opcodes
- Reduce ROM width (#data bits)
- Restrict µPC encoding (next, dispatch, wait on memory, …)
- Encode control signals (vertical µcoding, nanocoding)
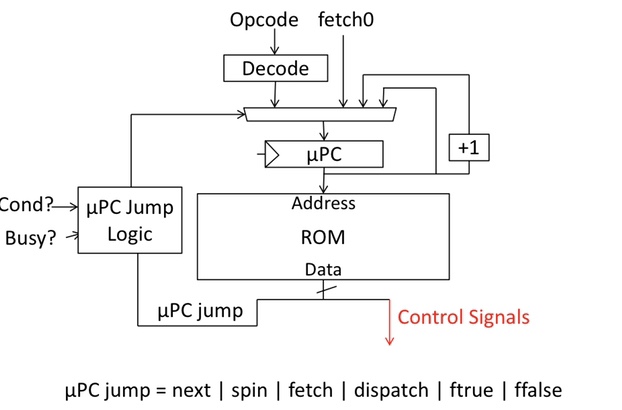
Microcoded r Hardcoded -> Hardwired
Horizontal vs. Vertical µCode
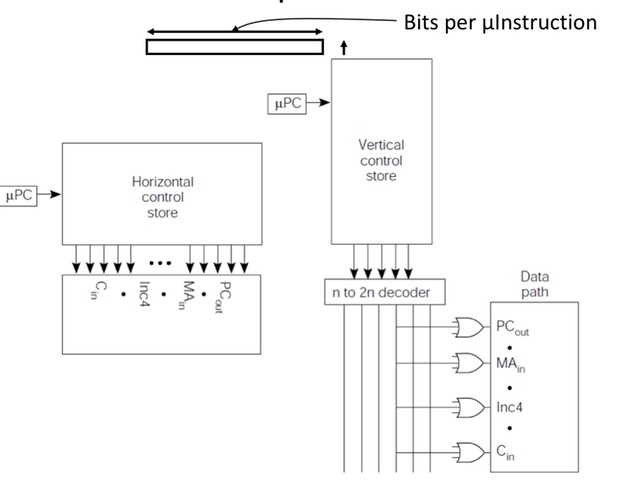
- Horizontal µcode has wider µinstructions
- Multiple parallel operations per µinstruction
- Fewer microcode steps per macroinstruction
- Sparser encoding ⇒ more bits
- Vertical µcode has narrower µinstructions
- Typically a single datapath operation per µinstruction
- separate µinstruction for branches
- More microcode steps per macroinstruction
- More compact ⇒ less bits but requires more capability of paralization
- Typically a single datapath operation per µinstruction
- Nanocoding
- Tries to combine best of horizontal and vertical µcode
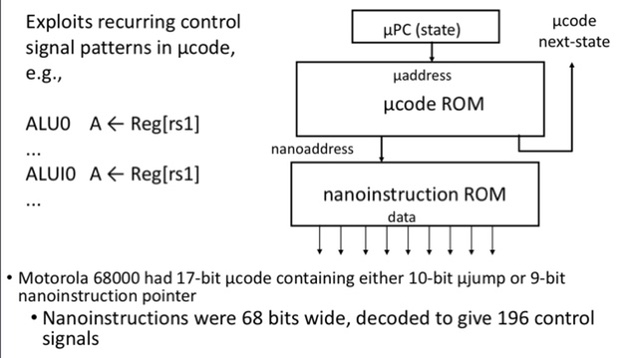
WCS 可编程
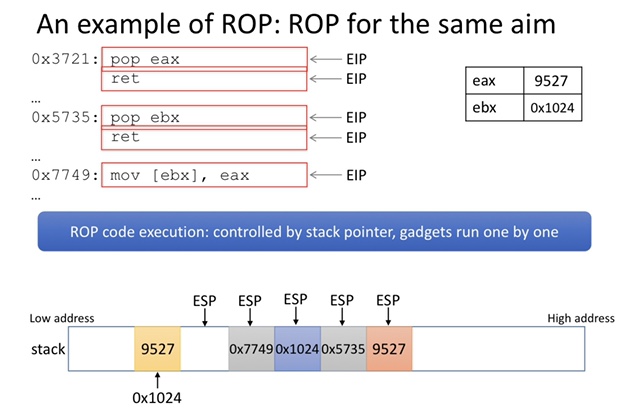
ROP
buffer overflow 攻击 Return-Oriented-Programing
图灵完备 在这个系统中写程序能够找到解决方法(尽管不保证运行时和内存)