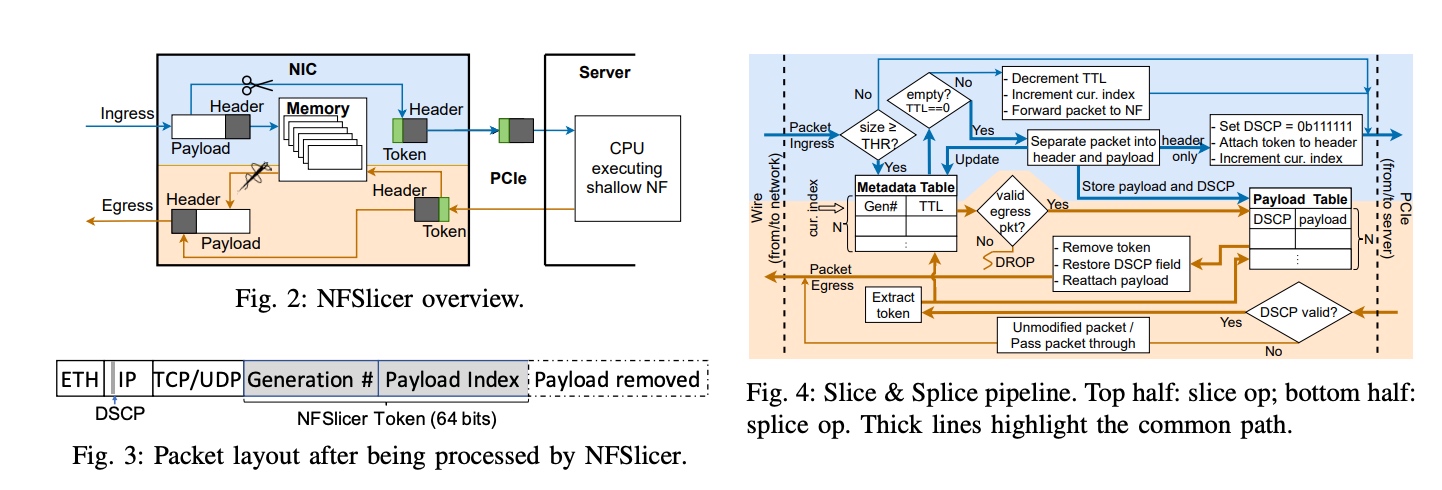
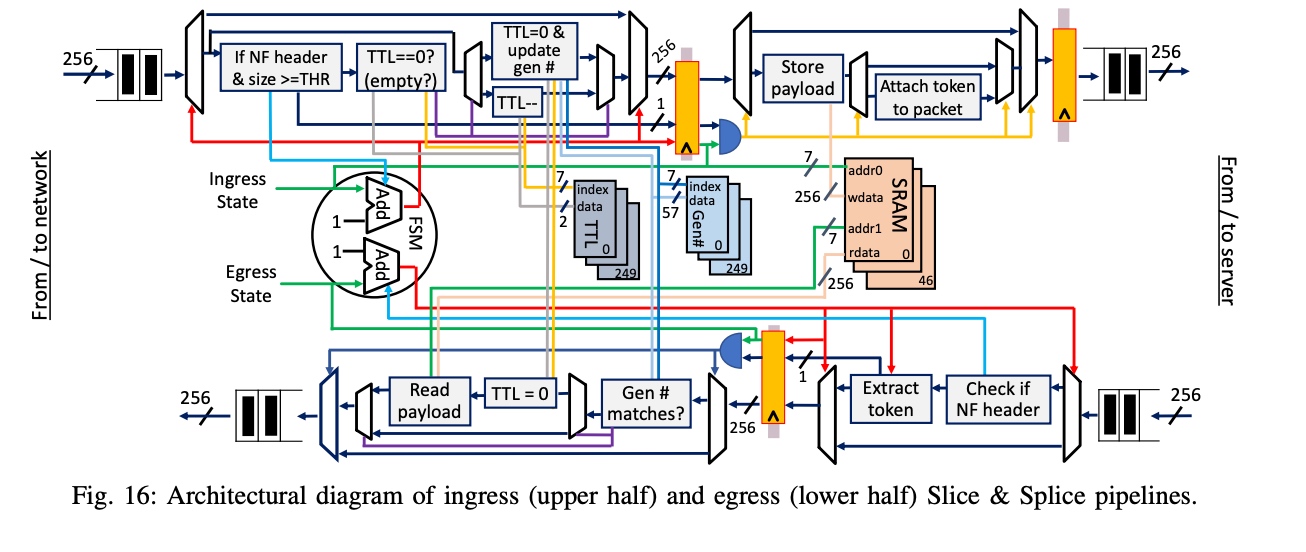
I was writing a rust version of tokio-rs/io-uring together with @LemonHX. First, I tried the official windows-rs trying to port the Nt API generated from ntdll. But it seems to be recurring efforts by bindgen to c API. Therefore, I bindgen from libwinring with VLDS generated.
Original struct, the flags should not be 0x08 size big. I don't know it's a dump bug or something.
typedef struct _NT_IORING_SUBMISSION_QUEUE
{
/* 0x0000 */ uint32_t Head;
/* 0x0004 */ uint32_t Tail;
/* 0x0008 */ NT_IORING_SQ_FLAGS Flags; /*should be i32 */
/* 0x0010 */ NT_IORING_SQE Entries[];
} NT_IORING_SUBMISSION_QUEUE, * PNT_IORING_SUBMISSION_QUEUE; /* size: 0x0010 */
static_assert (sizeof (NT_IORING_SUBMISSION_QUEUE) == 0x0010, "");
The above struct should be aligned as:
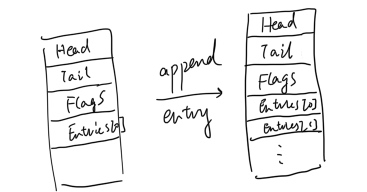
Generated struct
#[repr(C)]
#[derive(Default, Clone, Copy)]
pub struct __IncompleteArrayField<T>(::std::marker::PhantomData<T>, [T; 0]);
impl<T> __IncompleteArrayField<T> {
#[inline]
pub const fn new() -> Self {
__IncompleteArrayField(::std::marker::PhantomData, [])
}
#[inline]
pub fn as_ptr(&self) -> *const T {
self as *const _ as *const T
}
#[inline]
pub fn as_mut_ptr(&mut self) -> *mut T {
self as *mut _ as *mut T
}
#[inline]
pub unsafe fn as_slice(&self, len: usize) -> &[T] {
::std::slice::from_raw_parts(self.as_ptr(), len)
}
#[inline]
pub unsafe fn as_mut_slice(&mut self, len: usize) -> &mut [T] {
::std::slice::from_raw_parts_mut(self.as_mut_ptr(), len)
}
}
#[repr(C)]
#[derive(Clone, Copy)]
pub struct _NT_IORING_SUBMISSION_QUEUE {
pub Head: u32,
pub Tail: u32,
pub Flags: NT_IORING_SQ_FLAGS,
pub Entries: __IncompleteArrayField<NT_IORING_SQE>,
}
The implemented __IncompleteArrayField seems right for its semantics of translating with slice and ptr. However, when I called the NtSubmitIoRing API, the returned data inside Field is random same result no matter moe the fiel d for what distance of Head.