

文章目录[隐藏]
This doc is frequently updated.
I'm looking into the design of WAMR because this fits the heterogeneous device migration.
Interperter vs. AOT vs. JIT
- Interpreter has 2-5x slow down.
- AOT and JIT have a near-native slowdown, but JIT has load time compilation which takes time. If the program is long enough, load time doesn't care.
Interpreter
The interpreter mode has two modes; the main difference between classic and fast is the handle table and indirect jump; they make it cache-friendly.
AOT and JIT
Fast JIT is a lightweight implementation that has the auxiliary stack for interp frame. But has 50%-80% performance of LLVM JIT.
Basically, they share the same LLVM infrastructure, but AOT has more internal states that have been updated pretty well with a struct name starting with AOT*. AOT has a standalone compiler called wamrc for compiling the bytecode to AOT Module. On loading the program, AOT will load into the LLVM section and update the struct. JIT will not be called out, but they will call the same memory instance.
; ModuleID = 'WASM Module'
source_filename = "WASM Module"
define void @"aot_func#0"(i8** %e) {
f:
%a = getelementptr inbounds i8*, i8** %e, i32 2
%a1 = load i8*, i8** %a, align 8
%c = getelementptr inbounds i8, i8* %a1, i32 104
%f2 = getelementptr inbounds i8, i8* %a1, i32 40
%f3 = bitcast i8* %f2 to i8**
%f4 = load i8*, i8** %f3, align 8
%f5 = bitcast i8* %f4 to i8**
br label %f6
f6: ; preds = %f
ret void
}
define void @"aot_func#0_wrapper"() {
f:
ret void
}
We will lose the symbol for the function generation without the debug symbol. But they have a definition of dwarf for wasm specifically, which WAMR implemented on load.
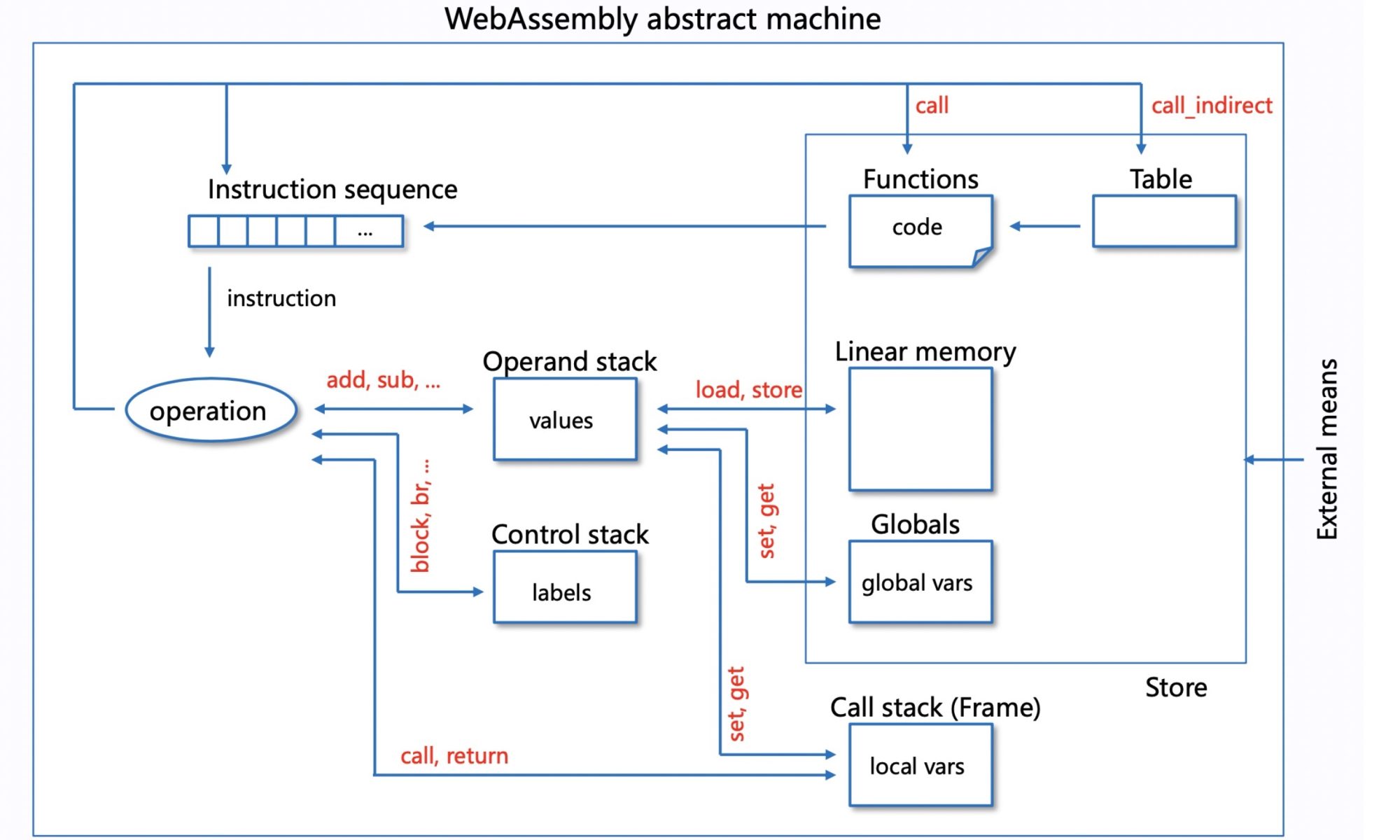
Abstract machine
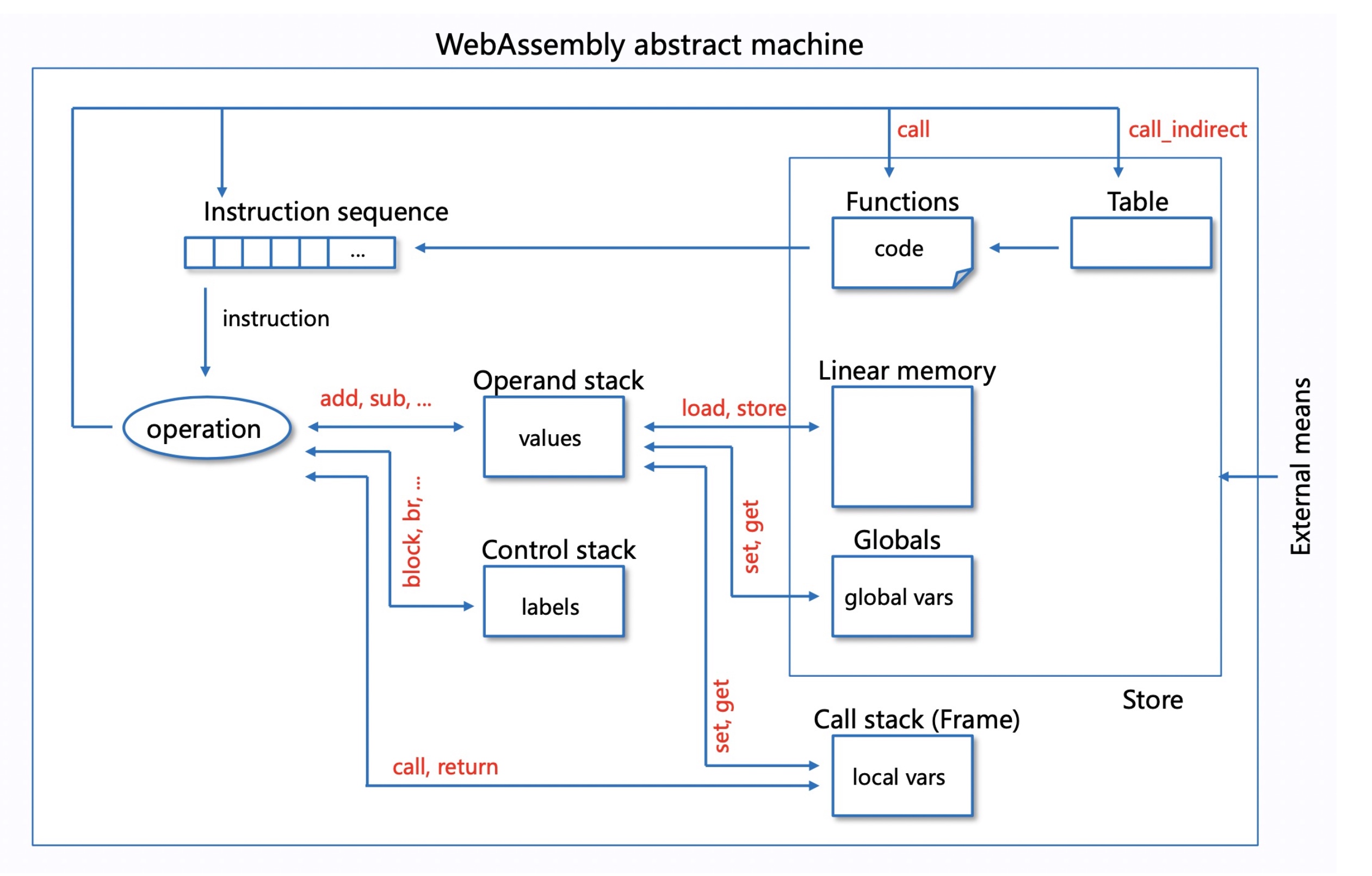
For Interpreter and AOT, every step has a state of every component stored at the C++ language level.
Memory
First, init with memory allocation on options.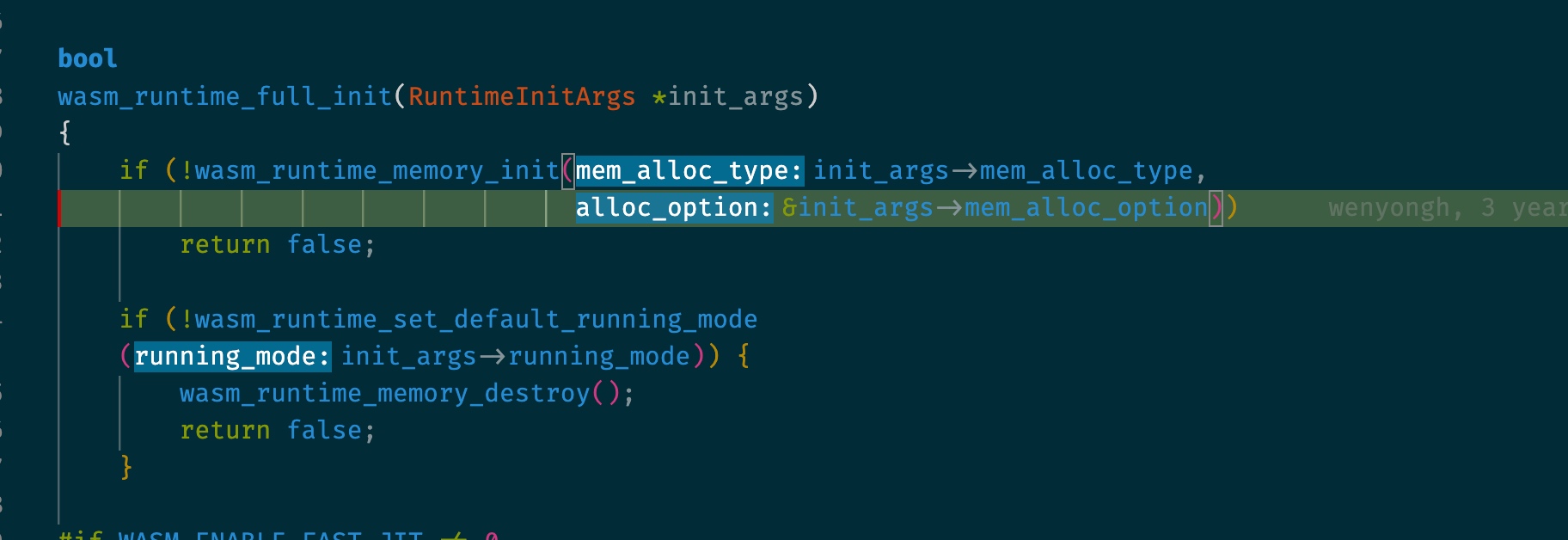
You can define the memory serialized data section in the same place and first initialize them into desired memory format.
RuntimeInitArgs wasm_args;
memset(&wasm_args, 0, sizeof(RuntimeInitArgs));
wasm_args.mem_alloc_type = Alloc_With_Allocator;
wasm_args.mem_alloc_option.allocator.malloc_func = ((void *)malloc);
wasm_args.mem_alloc_option.allocator.realloc_func = ((void *)realloc);
wasm_args.mem_alloc_option.allocator.free_func = ((void *)free);
wasm_args.max_thread_num = 16;
if(!is_jit)
wasm_args.running_mode = RunningMode::Mode_Interp;
else
wasm_args.running_mode = RunningMode::Mode_LLVM_JIT;
OS Bound Check does, from stack bottom to top, iterate to check whether is overflow every time access. as it was hardware accelerated by Flexible Hardware-Assisted In-Process Isolation with HFI
Other component
WASI
- fd open impl: On VM instantiation on _start->wasm_call_ctors, it will do populate preopens and malloc the corresponding ntwritten and fd_app, by default mapping the fd 0 1 2 to the wasm app.
WASI-nn
The wasm layer provides an interface for TensorFlow to call on, which is like a very lightweight abi for a better backend to codegen. As the tensor has different impl for CPU/NPU/GPU, it can easily be plugged and played for different platforms.
struct WAMRWASINNContext {
bool is_initialized;
graph_encoding current_encoding;
uint32_t current_models;
Model models[MAX_GRAPHS_PER_INST]; // From TFLite
uint32_t current_interpreters;
Interpreter interpreters[MAX_GRAPH_EXEC_CONTEXTS_PER_INST];
};
WASI-crypto
WASI-socket
The specifi