Problem Setup
I found in the linux manual that if I want to divide memory by X:Y on 2 NUMA nodes. I can leverage the policy of cpuset that has a higher priority of cgroup memory policy. A formal description of this lies here and there.


A Tech Nerd with a finance mind.
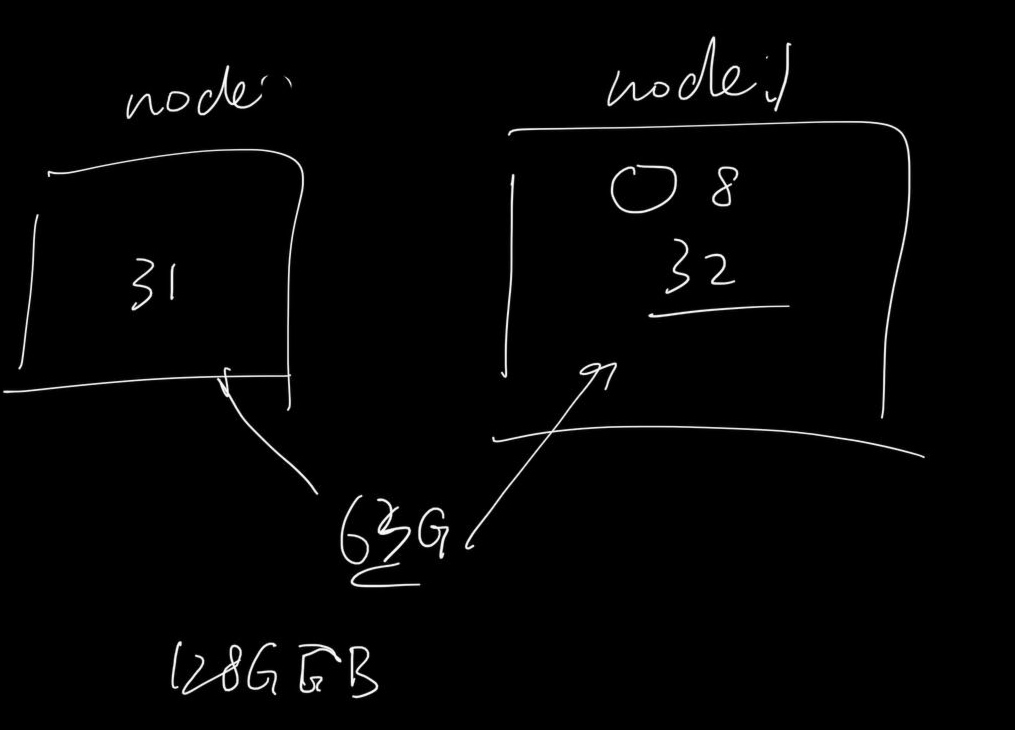
I found in the linux manual that if I want to divide memory by X:Y on 2 NUMA nodes. I can leverage the policy of cpuset that has a higher priority of cgroup memory policy. A formal description of this lies here and there.
首先,我们为什么需要一个PCIe attached memory or cache协议,重点是CPU上memory channel的局限性,你无法多加过多的并行的Memory Bus。虽然这对memory的随机读写有好处,现在的channel个数大概满足了CPU-memory Ratio,开多少线程跑load&store都能满足CPU的需求。
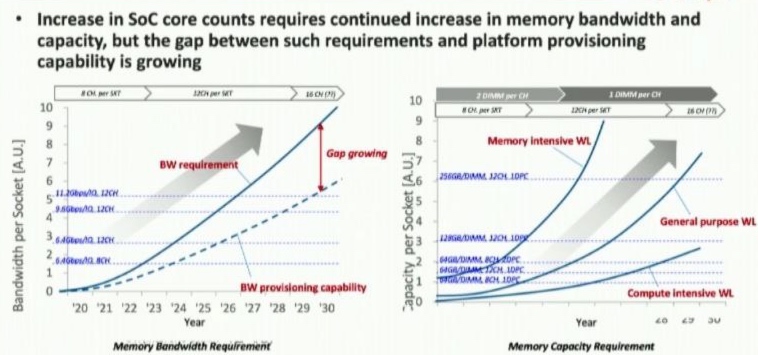
过多的线程会在核内空转也不会issue超过CPU频率和算力的内存指令。大家可以想象一个roofline model x轴为什么是arithmatic density的原因。同时淘汰浪费内存带宽的3D Xpoint也成了必然。那么串行的PCIe协议访问memory就非常有意义了,Meta的workload告诉我们80%的互联网应用是capacity bound,意思是我有一个很大的data warehouse,需要low latency访问的,也即是用户即将要显示在终端设备上的其实很少。只需要保证在短时间内load到private DRAM,就满足了。
让我们从两个实际例子开始。
如果今天有人要创建一个基于PCIe的内存扩展设备,并希望该设备能够暴露相干字节寻址的内存,那么实际上只有两个可行的选择。一个人可以通过基础地址寄存器(BAR)暴露这个内存映射的输入/输出(MMIO)。如果没有Hack,唯一合理的方法是需要有CPU支持,将MMIO映射为未缓存(UC),这对性能有明显的影响。关于对GPU的连贯性内存访问的更多细节,可以看看Nvidia 的Hack。对设备内存的访问不受协议的限制,而我们还没有设法完成这个目标。事实上,NVMe 1.4规范引入了持久性内存区域(PMR,区别于C++20的pmr),它可以做到这一点,但仍然是有限的。
如果创建一个基于PCIe的设备,其主要工作是进行网络地址转换(NAT)(或其他一些IP数据包修改),这将由CPU完成,为此需要关键的内存带宽。这是因为CPU将不得不从设备中读取数据,对其进行修改,并将其写回,而通过PCIe的唯一方法就是通过主内存来完成。
通过串行的传输协议我们会获得Non-deterministic memory latency,除了极端情况下放在核电厂旁边不停丢包以外,更会受到CXL Switch over subscription的影响.
使用DRAM介质直连CPU的内存和NVDIMM不到100ns,通过PCIe串行连接的缓存一致性协议CXL(XMM、NV-XMM模组和AIC)、CCIX可以达到350ns延时;OpenCAPI的DDIMM也只有40ns;而Gen-Z这样经过外部Switch/网络连接的在800ns水平。
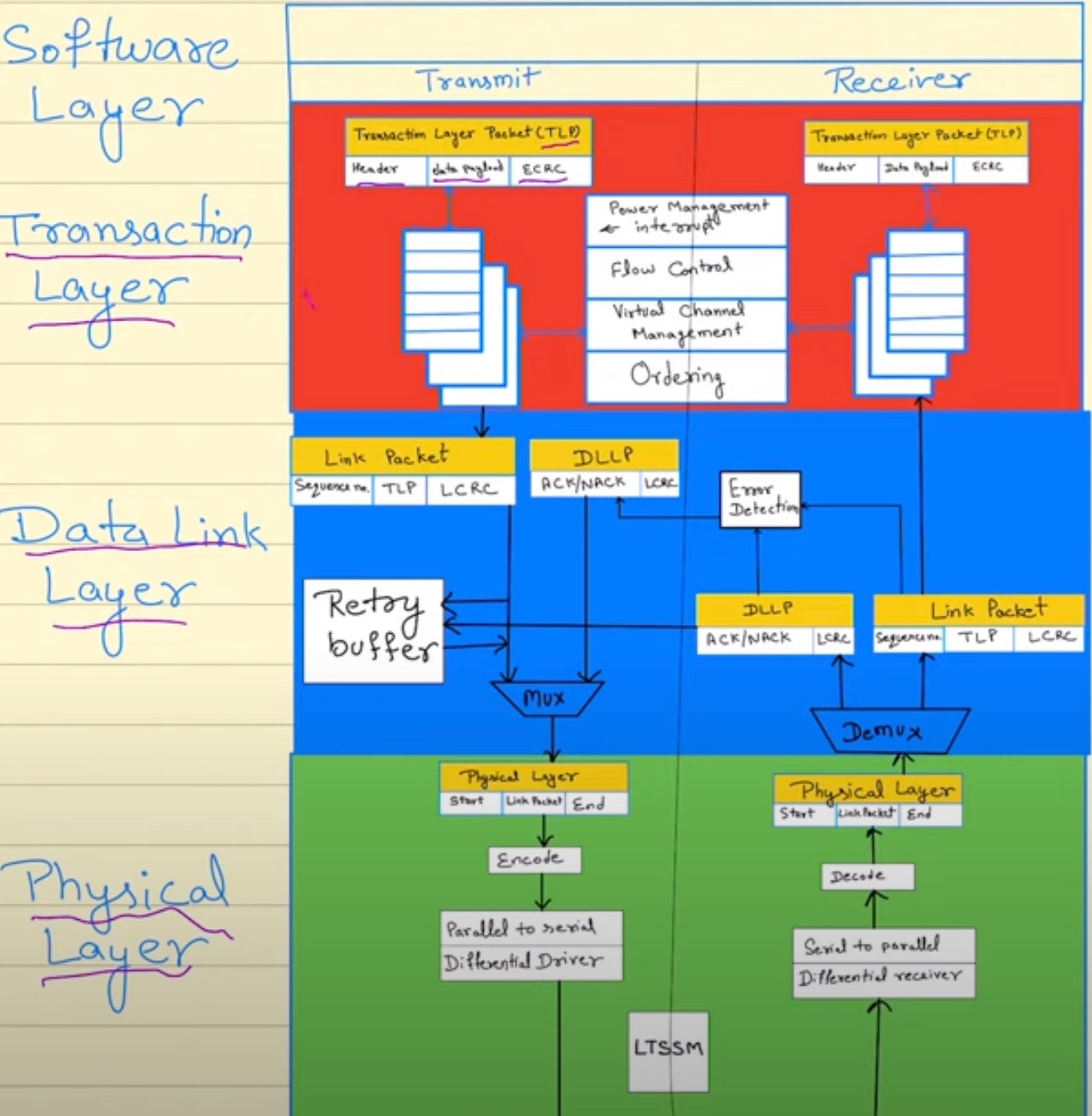
包头所对应的不同层传输格式
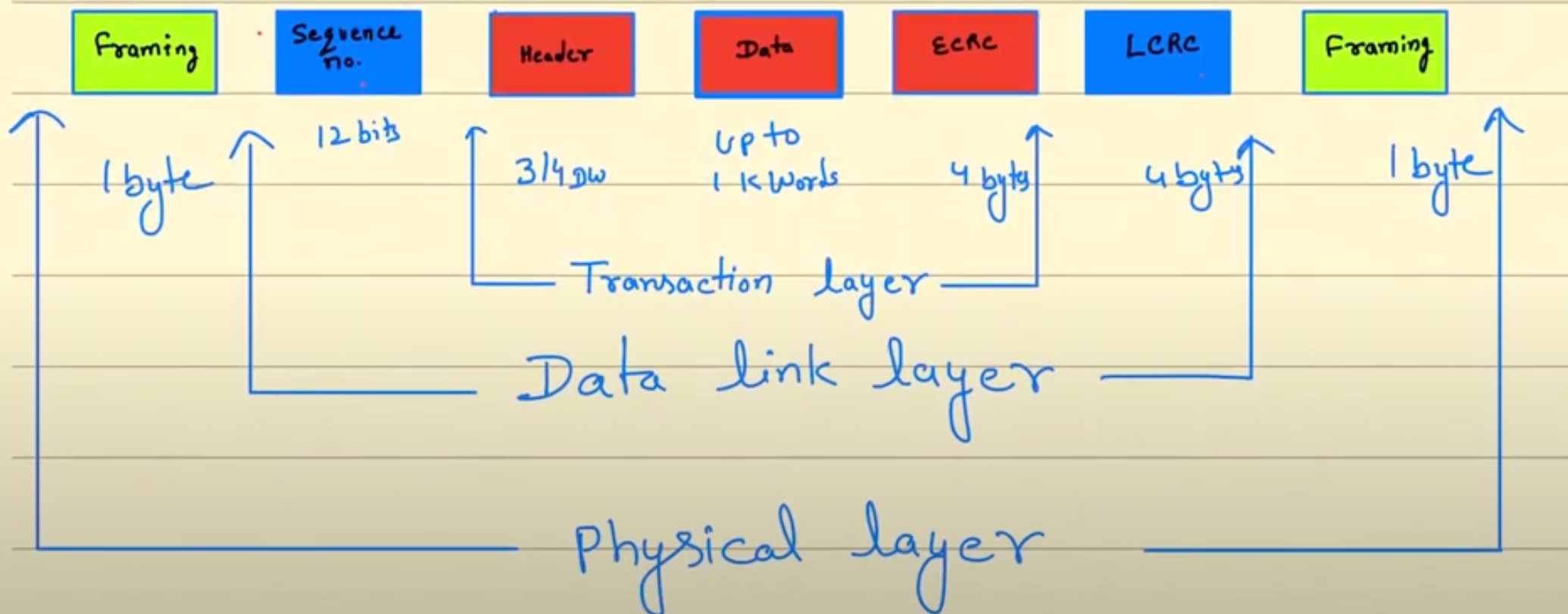
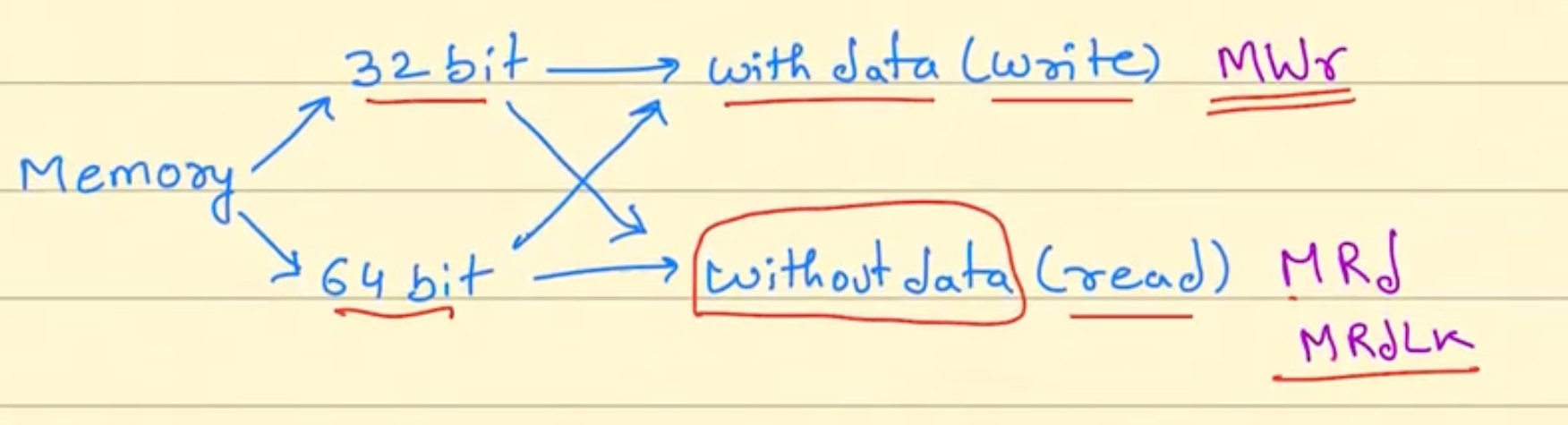
Memory configuration space有32bit BAR限制.需要一开始就指定是32/64来获得3DW还是4DW
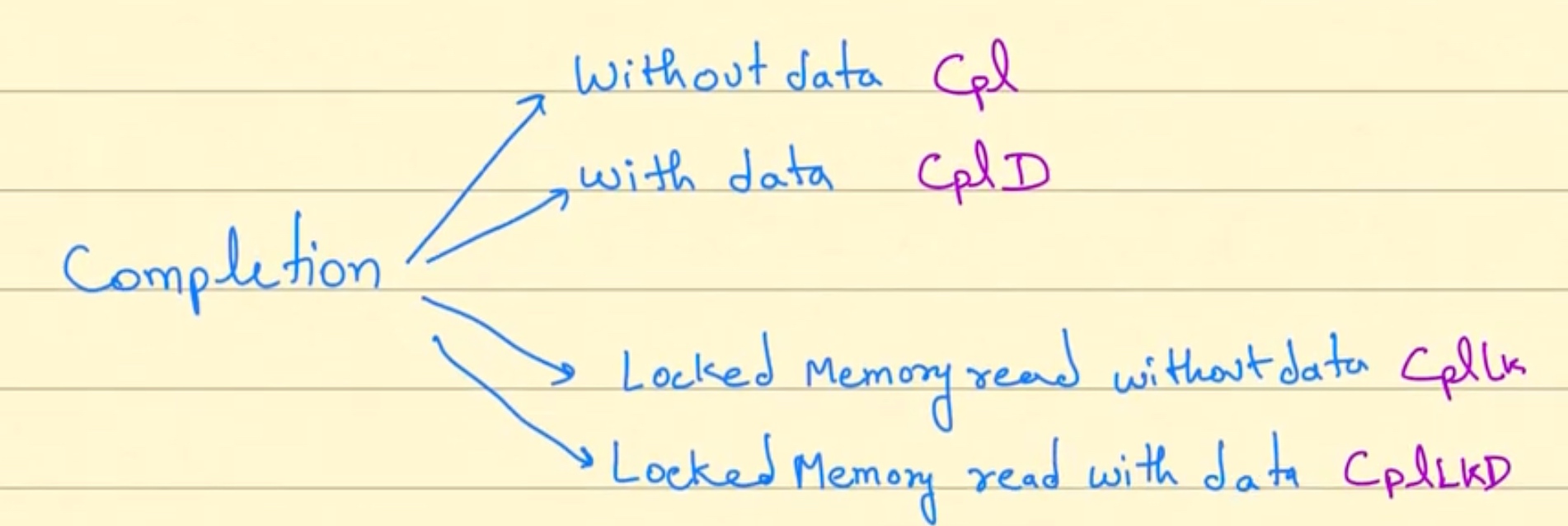
Completion 返回的 Ack 是分别对应之前的 Memory 请求。

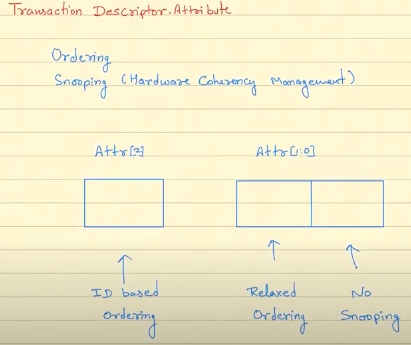
最后值得注意的是Transaction Descriptor Attribute 会指定IO的Ordering和CPU的Ordering/Snooping
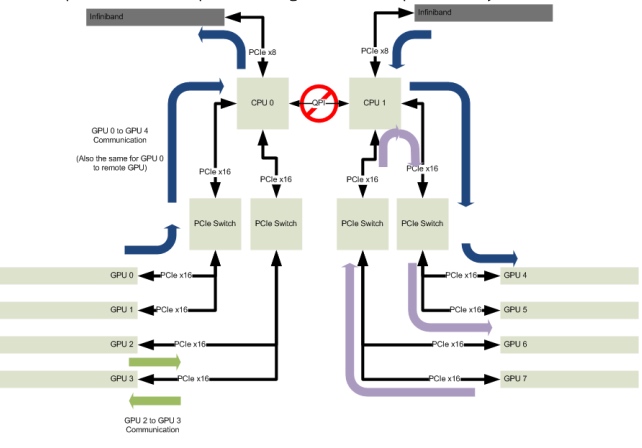
End Point通常是我们最感兴趣的,因为那是我们放置高性能设备的地方。它是样本框图中的GPU,而在实时情况下,它可以是一个高速以太网卡或数据收集/处理卡,或一个infiniband卡与大型数据中心的一些存储设备communication。下面是一个框图,放大了这些组件的互连。
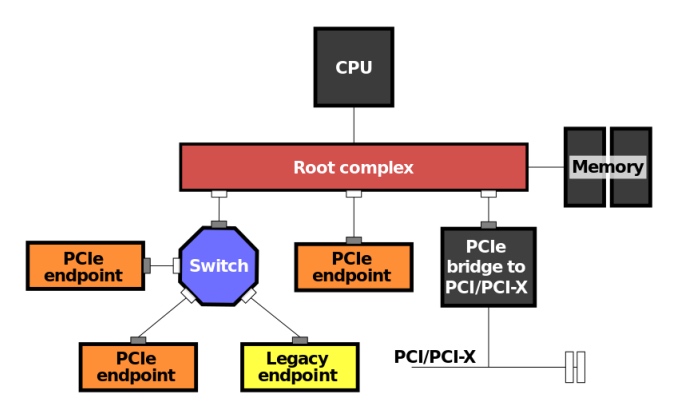
基于这个拓扑结构,让我们来谈谈一个典型的场景,其中远程直接内存访问(RDMA)被用来允许终端PCIE设备在数据到达时直接写入预先分配的系统内存,这最大限度地卸载了CPU的任何参与。因此,设备将发起一个带有数据的写入请求,并将其与希望的Root ComplexRoot一起发送,其将数据输入系统内存.
2.0 .mem也需要在背后维护一套directory based的coherency protocol,如何实现是个问题。3.0有很多的内存序问题,MESI是否是一个过于慢的设计?总线怎么设计?
Keven的文章, 之前在王老师的课上读过HMM, 当时同时看的是ccNUMA, 而这篇着重讲了如何应对Row Hammer bit flip 的NUMA aware 策略。

去是去不了了, 但是还是看了一下paper list.然后发现只要去就能提前看到paper list,这种传统还挺有意思的。
I was writing a rust version of tokio-rs/io-uring together with @LemonHX. First, I tried the official windows-rs trying to port the Nt API generated from ntdll. But it seems to be recurring efforts by bindgen to c API. Therefore, I bindgen from libwinring with VLDS generated.
Original struct, the flags should not be 0x08 size big. I don't know it's a dump bug or something.
typedef struct _NT_IORING_SUBMISSION_QUEUE
{
/* 0x0000 */ uint32_t Head;
/* 0x0004 */ uint32_t Tail;
/* 0x0008 */ NT_IORING_SQ_FLAGS Flags; /*should be i32 */
/* 0x0010 */ NT_IORING_SQE Entries[];
} NT_IORING_SUBMISSION_QUEUE, * PNT_IORING_SUBMISSION_QUEUE; /* size: 0x0010 */
static_assert (sizeof (NT_IORING_SUBMISSION_QUEUE) == 0x0010, "");
The above struct should be aligned as:
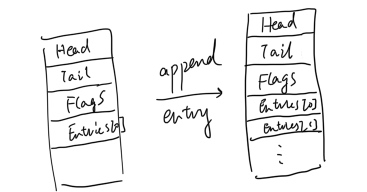
Generated struct
#[repr(C)]
#[derive(Default, Clone, Copy)]
pub struct __IncompleteArrayField<T>(::std::marker::PhantomData<T>, [T; 0]);
impl<T> __IncompleteArrayField<T> {
#[inline]
pub const fn new() -> Self {
__IncompleteArrayField(::std::marker::PhantomData, [])
}
#[inline]
pub fn as_ptr(&self) -> *const T {
self as *const _ as *const T
}
#[inline]
pub fn as_mut_ptr(&mut self) -> *mut T {
self as *mut _ as *mut T
}
#[inline]
pub unsafe fn as_slice(&self, len: usize) -> &[T] {
::std::slice::from_raw_parts(self.as_ptr(), len)
}
#[inline]
pub unsafe fn as_mut_slice(&mut self, len: usize) -> &mut [T] {
::std::slice::from_raw_parts_mut(self.as_mut_ptr(), len)
}
}
#[repr(C)]
#[derive(Clone, Copy)]
pub struct _NT_IORING_SUBMISSION_QUEUE {
pub Head: u32,
pub Tail: u32,
pub Flags: NT_IORING_SQ_FLAGS,
pub Entries: __IncompleteArrayField<NT_IORING_SQE>,
}
The implemented __IncompleteArrayField seems right for its semantics of translating with slice and ptr. However, when I called the NtSubmitIoRing API, the returned data inside Field is random same result no matter moe the fiel d for what distance of Head.
在LLVM上用concolic exuction拿到DFG path feed 给fuzzer和santinizer。算法上有很多剪枝优化。还在看实现。
For the HPC system, prefetching both hw/sw requires sophisticated simulation and measurement to perform better.
The purpose of the author is because first, there is not much explanation of how best to insert prefetch intrinsic. Second, not a good understanding of the complex interactions between hardware prefetching and software prefetching.
The target of soft prefetching is found to be short array streams, irregular memory address patterns, L1 cache miss reduction. There is a positive effect, however, since software prefetching trains hardware prefetching, a further part of the situation is a bad effect. Since stream and stride prefetchers are the only two currently implemented commercially, our hardware prefetching strategies are restricted to those.
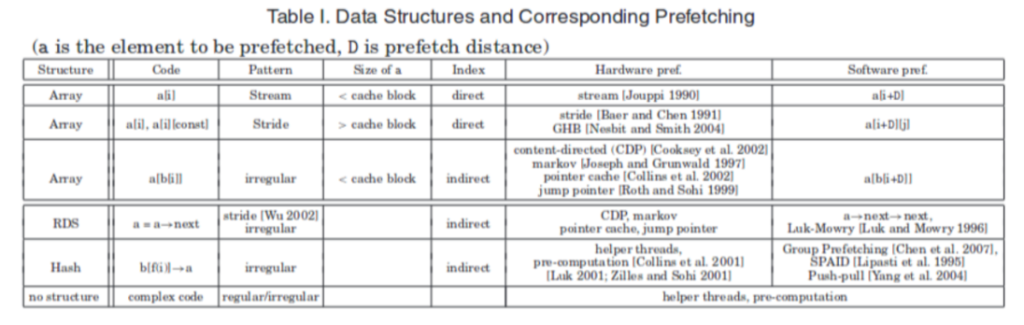
As the picture depicted above, the software can easily anticipate array accesses and prefetch data in advance. Stream means accessing data across a single cache line while stride means accessing across more than two cache lines.
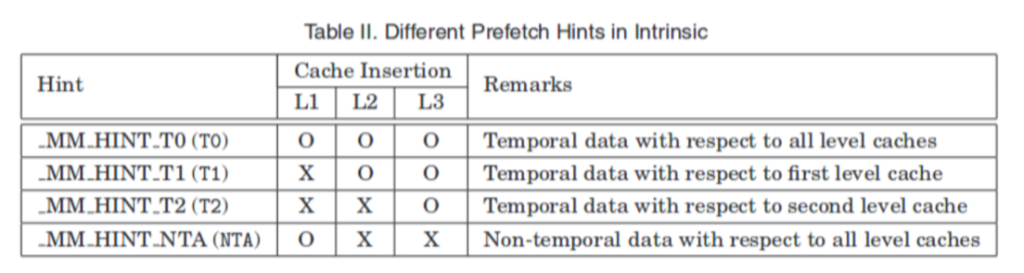
For Software Prefetch Intrinsics, temporal for the use of the data to be used again, so the next layer still have to put, such as L1 have to put L2, L3 are put, so that when the data is kicked out of the L1 cache can still be loaded from L2, L3 and None - temporal for the use of the data no longer used, so L1 put on the good, was kicked out will not be loaded from L2, L3.

In the software prefetch distance graph, prefetching data too early will make the data stay in the cache for too long, and the data will be kicked out of the cache before it is really used, while prefetching data too late causes cache miss latency to occur. The equation $D \geq \left. \ \left\lceil \frac{l}{s} \right.\ \right\rceil$ shows, where l is prefetch latency, and s is the length of the shortest path through the loop body. When D (D is a[i+D] of table) is large enough to cover the cache miss latency but when D is too large it may cause the prefetch to kick out useful data from the cache and the beginning of the array may not prefetch which may cause more cache misses
Indirect memory indexing is dependent on software calculation, so we expect software prefetch will be more effective than hardware prefetch.
Hardware-baselined prefetch mechanism has a stream, GHB, and contend-based algorithm.
The good point of soft prefetch that outweighs hardware prefetch is a large number of streams
short streams, irregular Memory Access, Cache Locality Hint, and possible Loop Bounds. However, the negative impacts of software prefetching lie in increased instruction count because, it actually requires more instruction to calculate the memory offset, static insertion without adaptivity, and code structure change. For antagonistic effects, both of them have negative training and may be harmful to the original program.
In the evaluation part, the author first introduced the prefetch intrinsic insertion algorithm which first quantitatively measured the distance by IPCs and memory latency. The method has been used in C++ static prefetcher. Second, the author implemented different hardware prefetchers by MacSim and use the different programs in SPEC 2006 and compilers icc/gcc etc. to test the effectiveness of those prefetchers. They found one of the restrictions is typically thought to be the requirement to choose a static prefetch distance, The primary metric for selecting a prefetching scheme should be coverage. By using this metric, we can see that data structures with weak stream behavior or regular stride patterns are poor candidates for software prefetching and may even perform worse than hardware prefetching. In contrast, data structures with strong stream behavior or regular stride patterns are good candidates for software prefetching.
用LegoOS和Linux的不同性能对比得出了未来DBMS disaggregation 怎么设计。