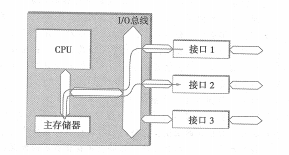
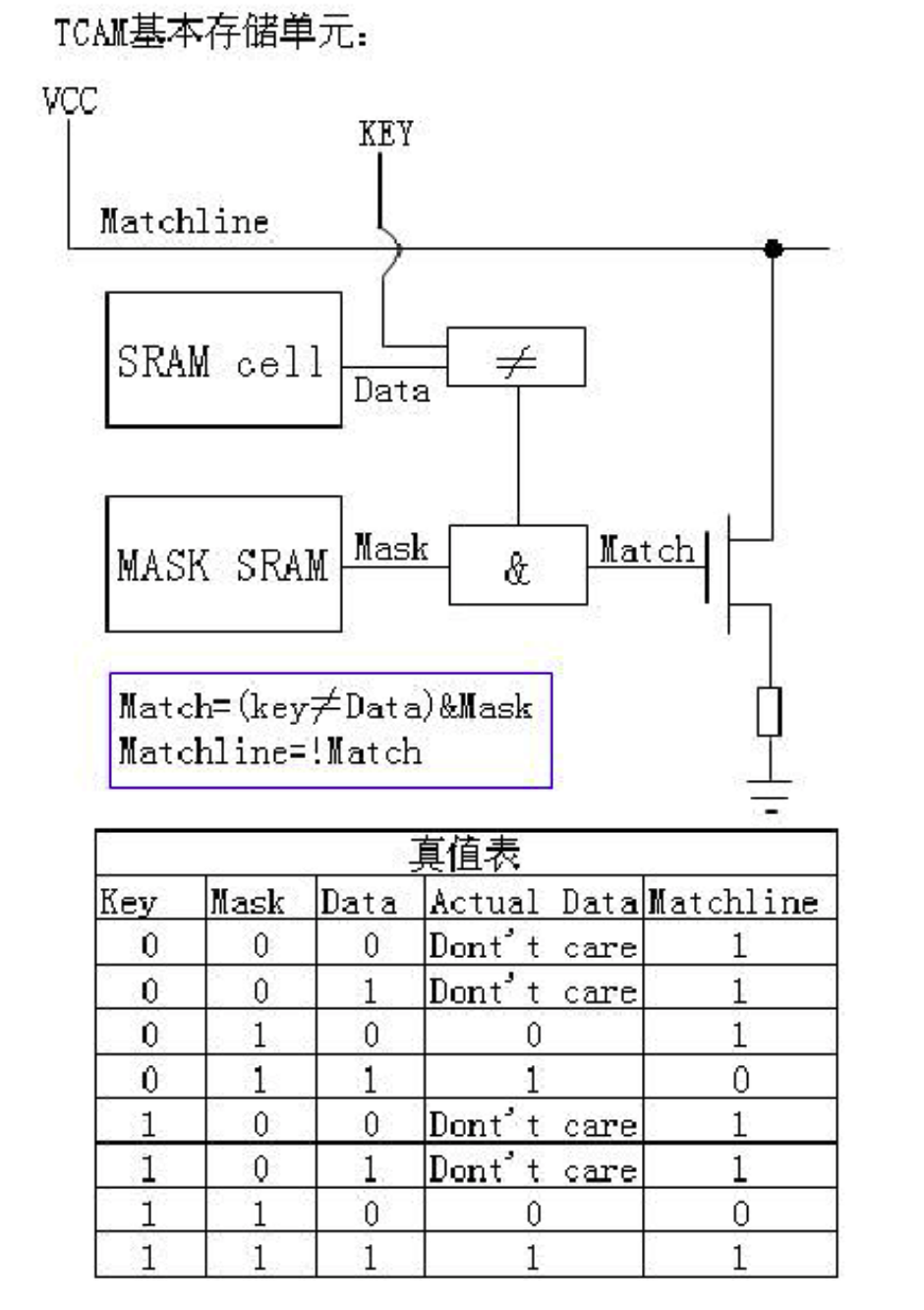
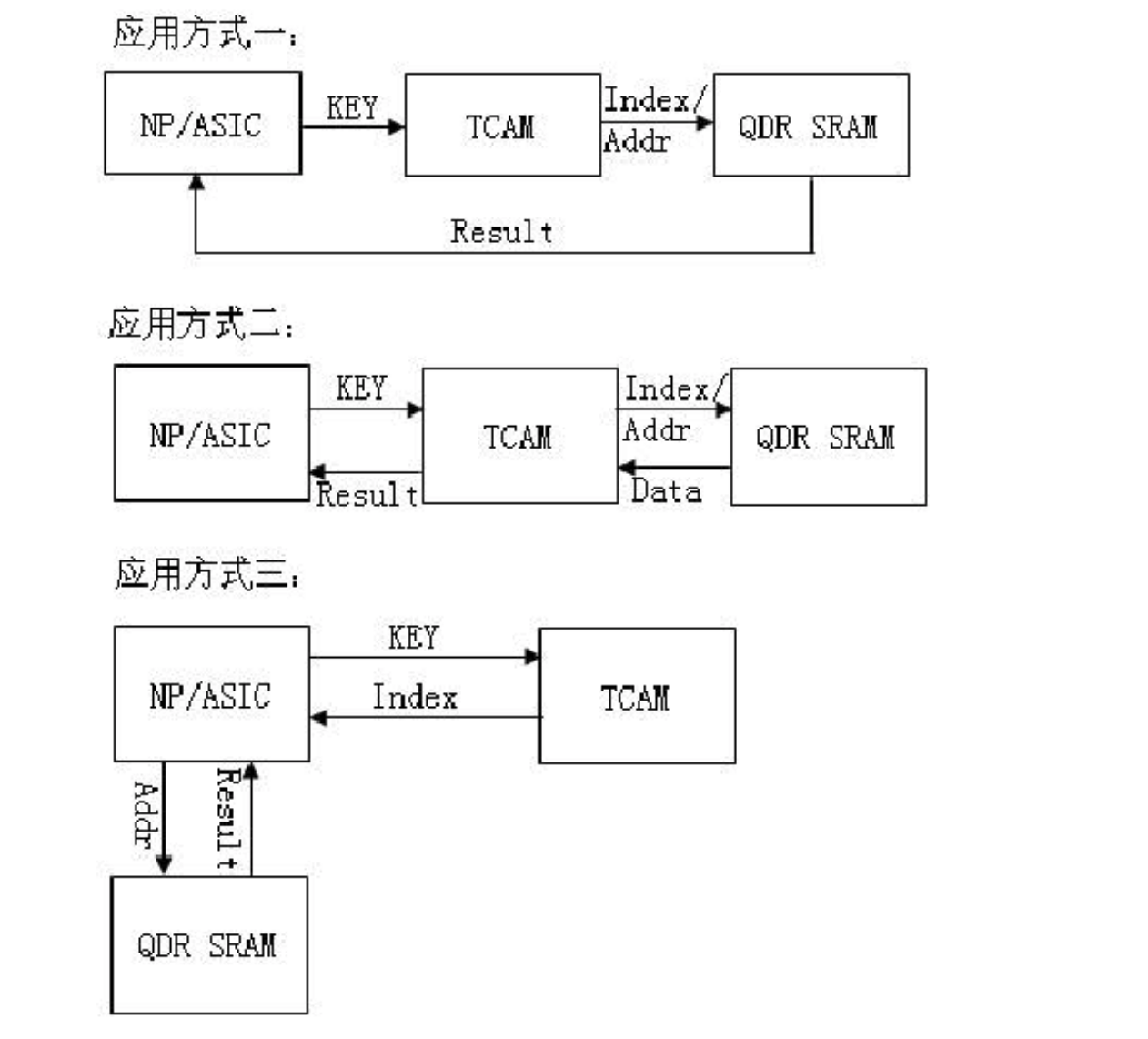
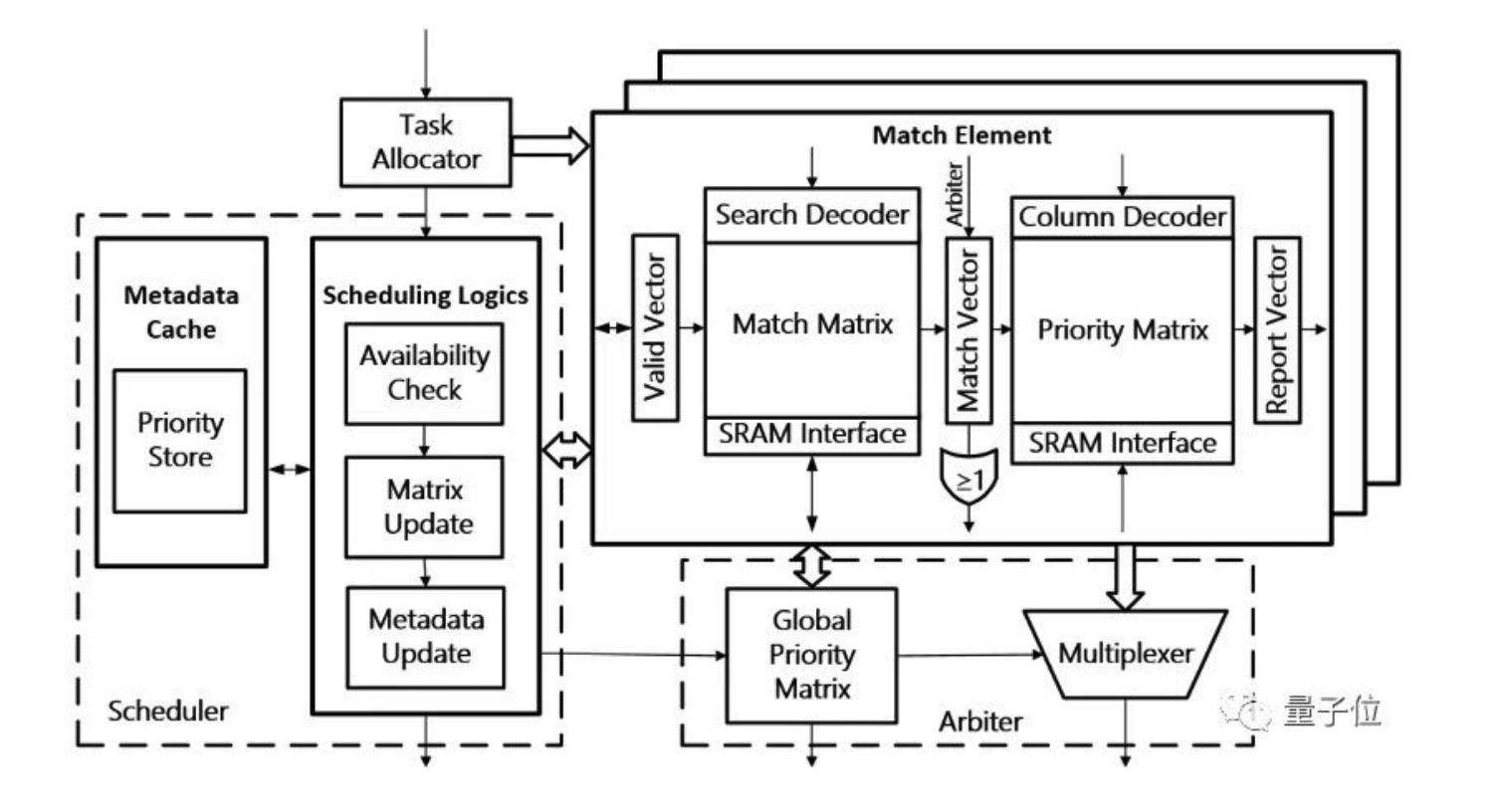
最近帮学长跑实验,同时也是毕业论文的实验,用的 Lustre。然后又重新读了一遍古老的PLFS、PMFS论文。同时用的是AMD超算集群,最多可以到512台node。
[scb5090@ln131%bscc-a6 ~]$ lfs quota -h -u scb5090 /public1
Disk quotas for usr scb5090 (uid 6171):
Filesystem used quota limit grace files quota limit grace
/public1 19.13G 450G 500G - 50865 0 0 -
uid 6171 is using default file quota setting
[scb5090@ln131%bscc-a6 ~]$ lfs quota -h -u scb5090 /public2
lfs quota: cannot resolve path '/public2': No such file or directory (2)
[scb5090@ln131%bscc-a6 ~]$ lfs quota -h -u scb5090 /public3
Disk quotas for usr scb5090 (uid 6171):
Filesystem used quota limit grace files quota limit grace
/public3 0k 0k 0k - 0 0 0 -
uid 6171 is using default block quota setting
uid 6171 is using default file quota setting
大致想干的一件事是把一个读hdf5的程序在并行文件系统上的scalability。