

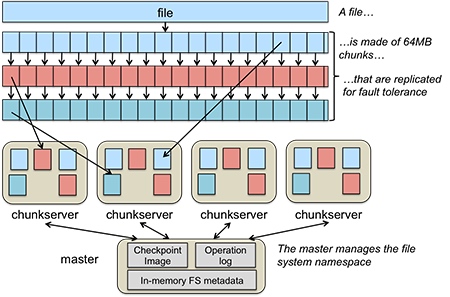
In the resource allocation problem in the Distributed Systems under the High Performance Computer, we don't really know which device like disk, NIC (network interface) is more likely to be worn, or not currently on duty which may trigger delaying a while to get the data ready. The current solution is random or round robin scheduling algorithm in avoidance of wearing and dynamic routing for fastest speed. We can utilize the data collected to make it automatic.
Matured system administrator may know the pattern of the parameter to tweak like stride on the distributed File Systems, network MTUs for Infiniband card and the route to fetch the data. Currently, eBPF(extended Berkeley Packets Filter) can store those information like the IO latency on the storage node, network latency over the topology into the time series data. We can use these data to predict which topology and stride and other parameter may be the best way to seek data.
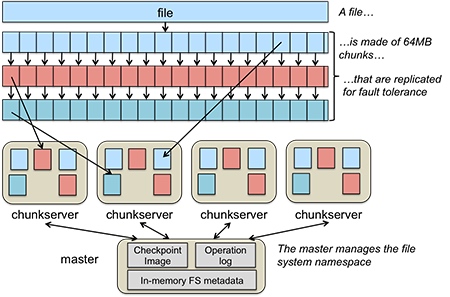
The data is online, and the prediction function can be online reinforce learning. Just like k-arm bandit, the reward can be the function of latency gains and device wearing parameter. The update data can be the real time latency for disks and networks. The information that gives to the RL bots can be where the data locate on disks, which data sought more frequently (DBMS query or random small files) and what frequency the disk make fail.
Benchmarks and evaluation can be the statistical gain of our systems latency and the overall disk wearing after the stress tests.