

The global non-related optimization is based on Dataflow Analysis. The mainstream compiler intermediate representation like LLVM/ Gravvm is based on SSA to do the Dataflow Analysis while Soot on JVM is utilizing Lattice (The classical definition) to do the intraprocedural.
[Program Analysis] Pointer Analysis
The CHA Analysis overly pursues the speed and gives some false positive cases. For must analysis like constant propagation, it's not acceptable. Pointer Analysis computes an over-approximation of the set of which memory locations (objects) a pointer can point to.
Some pitfalls using docker to host Nginx and php-fpm
I'm deploying my WordPress on AWS with Lambda function, all the services are coerced in one container. (I was intended to separate into different services, e.g. MySQL, Nginx, lambda-php-server, but not necessary) And I would get into 504 for Nginx.
My frontend Nginx do a proxy_pass to the backend Lambda function which always shows timeout. I was to think the performance of the chassis is bad, or some cgroup stuff is cast on the service. The log from behind Nginx shows there's setrlimit(RLIMIT_NOFILE, 51200) failed (1: Operation not permitted) I realize I have to give privilege to the Docker runtime. It will setrlimit to the host machine.
docker run -c 1024 --blkio-weight 600 -d -e https_proxy=http://172.17.0.1:1082 -e http_proxy=http://172.17.0.1:1082 -p 8022:22 -p 8443:443 -p 888:888 -p 3306:3306 -p 8888:8888 yangyw12345/wordpress_mainpage sh -c "while true;do echo hello world; sleep 100000;done"
[Program Analysis] LiveVariableAnalysis in Soot
Setup of the Soot
We need to first set up the Soot variables. In target command line tools, the config is passed by args, e.g. java -cp soot-2.5.0.jar soot.Main -pp -f J -cp . Hello. The prepend file is set and the jar interpreter will pass the variable $CLASSPATH. In my implementation, these are passed into Options.v(). Noticeably, I have to switch off the optimization for java ByteCode, or it will do Dead Code Elimination to remove the intermediate process.
CallGraph for Debug
I iterate the CFG before and after the Liveness analysis to see the problem.
for (Unit unit : body.getUnits()) {
System.out.println(unit.toString() + "[entry]" +lva.getFlowBefore(unit));
System.out.println(unit.toString() + "[exit]" +lva.getFlowBefore(unit));
}
LiveVariables
LiveVariableFlowSet
I record all the FlowSet<Local> to a enhanced AbstractBoundedFlowSet<Local> with liveVariable hash set. So that it has clone and record feature.
BackwardFlowAnalysis
The Analysis extends BackwardFlow. The merge logic is union and copy logic is copy. The flowThrough part is first calculates the kill set and makes the difference of kills and destSet; then the gens are merely the union of the iterated kills.
Input and output of file
The soot.Main only accept className, so I remove the "./" and ".class" to pass. And the directory is created in the same folder of the class file to write the output.
Processing-in-Memory Course: Programming PIM Architectures by Onur & Juan
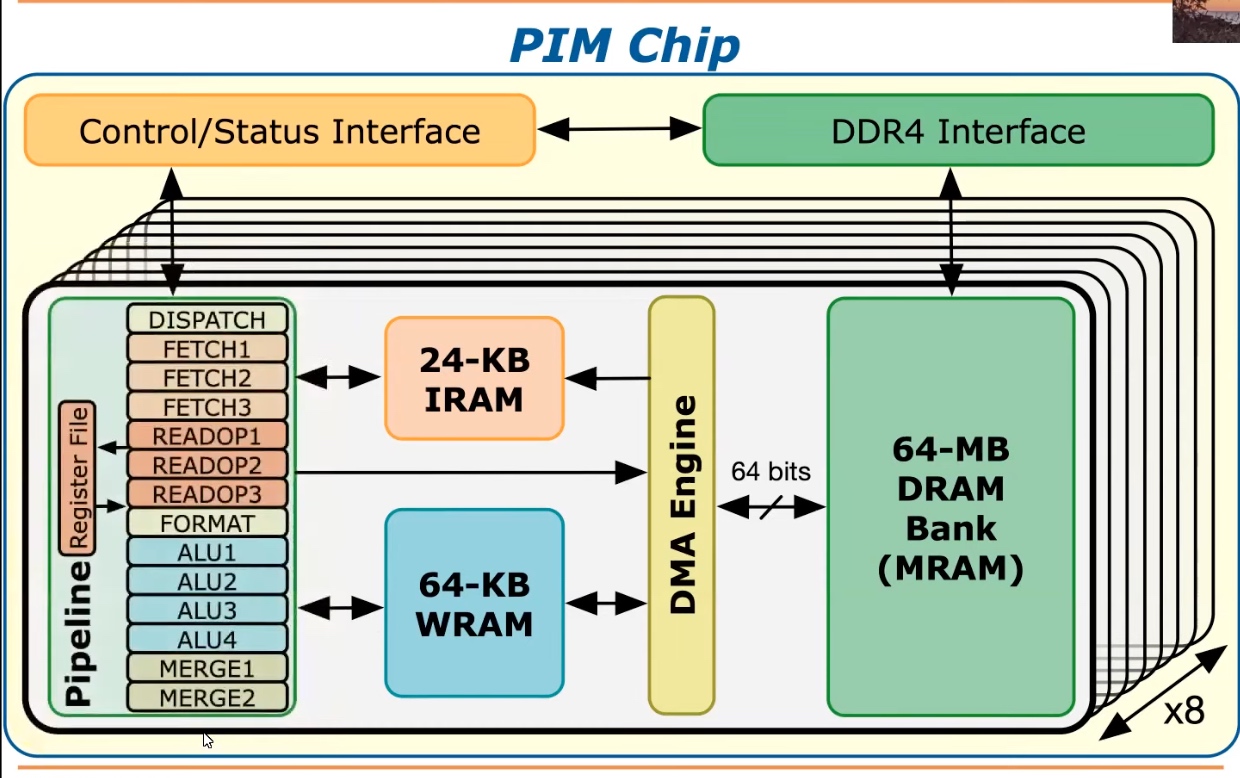
The course provides a software view of PIM Architecture like Intel does in its "Intel Manual for software people".
Also, DRAM Processing Unit is a long discussed topic to utilize the DRAM bandwidth.
UPMEM provides processing in DRAM Engine.
The introduction of PIM is to utilize large memory bandwidth and save cycles of on-chip memory compute.

Setups are DDR R-DIMM with 8GB+128DPUs and 2x-nm DRAM process.
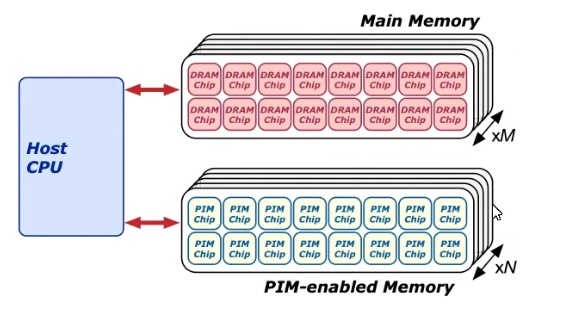
还是有个指令集把代码打到对面的

Reference
- https://www.youtube.com/watch?v=RaOIoOQ5EgE
- ^ ServeTheHome (2021-05-30). "DPU vs SmarNICs vs Exotic FPGAs". ServeTheHome. Retrieved 2022-01-03.
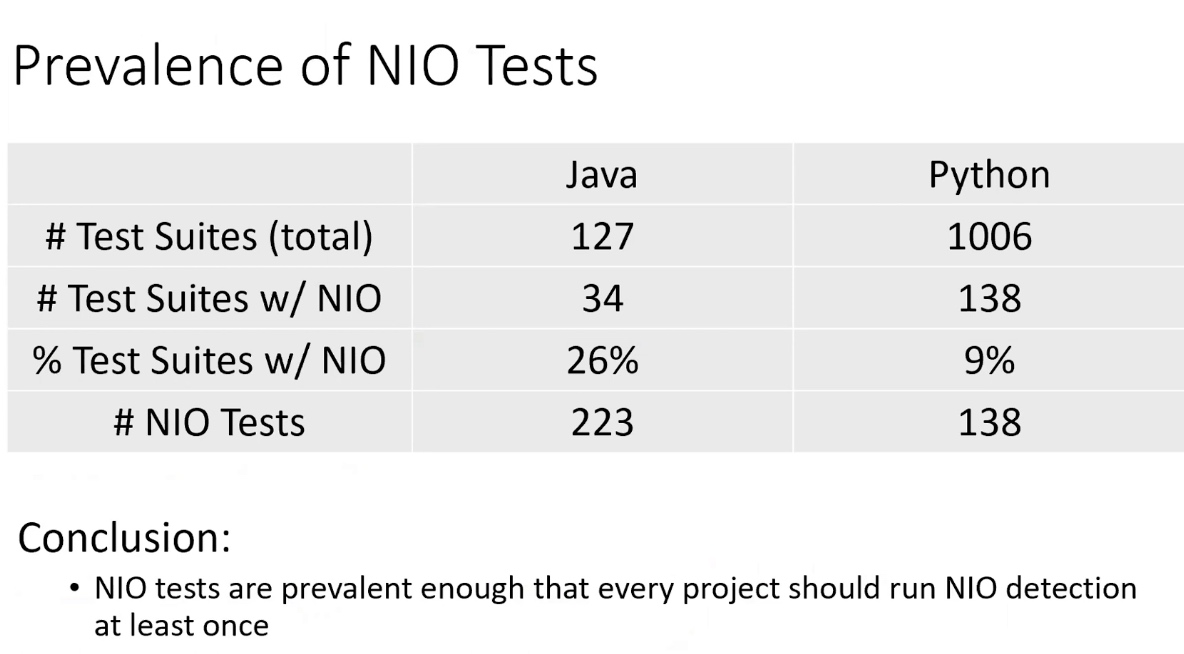
Preempting Flaky Tests via Non-Idempotent-Outcome Tests @ICSE '22

Nonidiomatic test are one of Flaky tests category. In the previous TACAS work, the relation between polluters(modify the shared state) and victims(read from the shared state) are found but there exists a lot false positive for it to have Order dependent variables inside, from our previous tests on these testcases. Also for the latent polluters/victims that potentially read/write the variables. e.g.
//shared variables x,y,z are initialized into 0
void t1(){ assert x==0; } // victim
void t2(){ x = 0; } // polluter
void t3(){ assert y==0; } // latent-victim
void t4(){ z=1; } // latent-polluter
void t5(){ assert w=0;w=1;}
The NIO tests means passes in the first run but fails in the second when run twice consecutively.
The NIO will self pollutes the state that its own assertions depend on
- NIO $\in$ latent-polluter ^ latent-victim $\in$ latent-writer
Examples

Real Examples



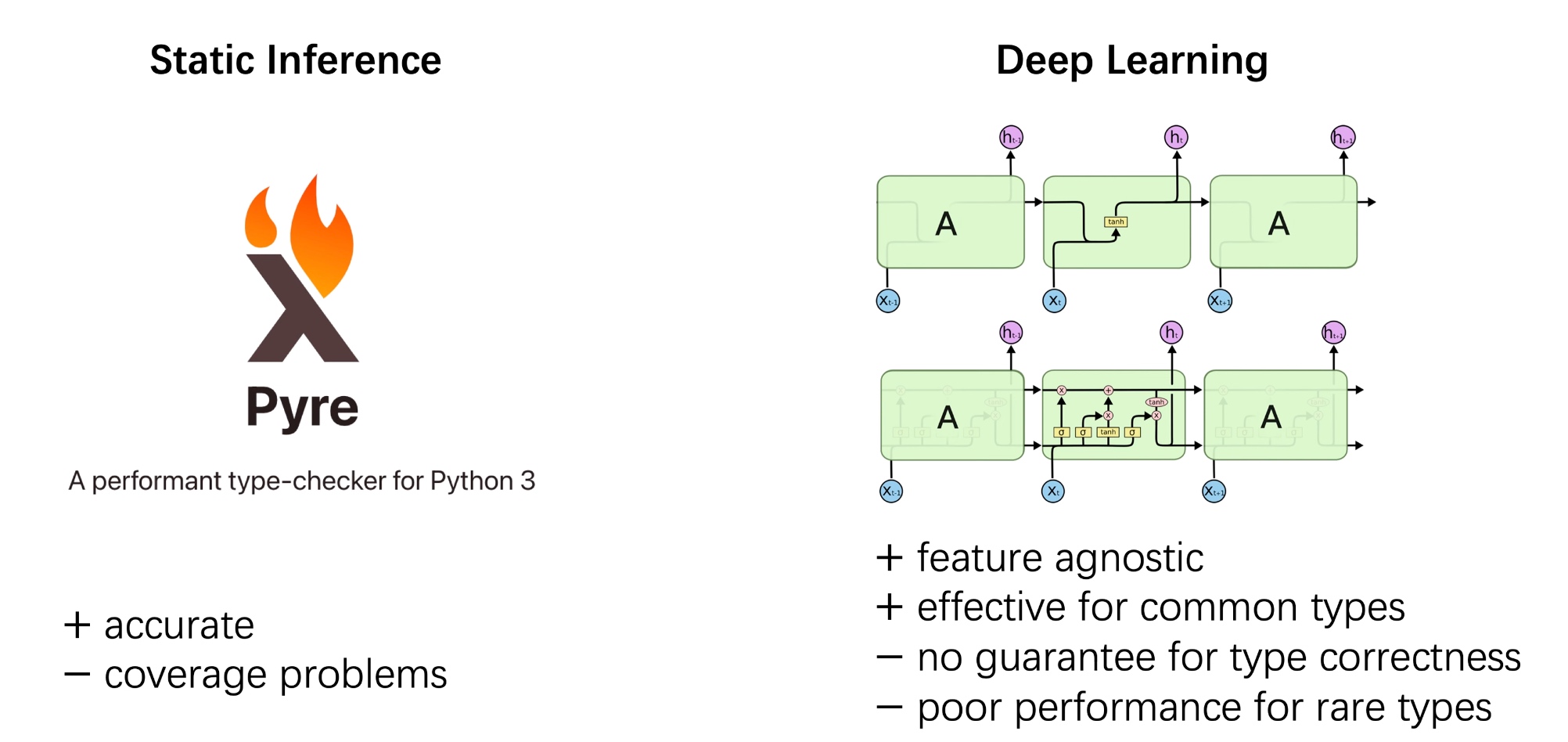
Static Inference Meets Deep Learning: A Hybrid Type Inference Approach for Python @ICSE '22
The type inference in dynamic function in python.

Compared with static inference like Pyre.
Static+DL Approach

先 Type dependency graph,在路径constraint上做验证正确性,最后再验证正确性。其实非动态语言rust的类型推导💥问题也可以这样解决。至少DL给了一个搜索路径。

Framework
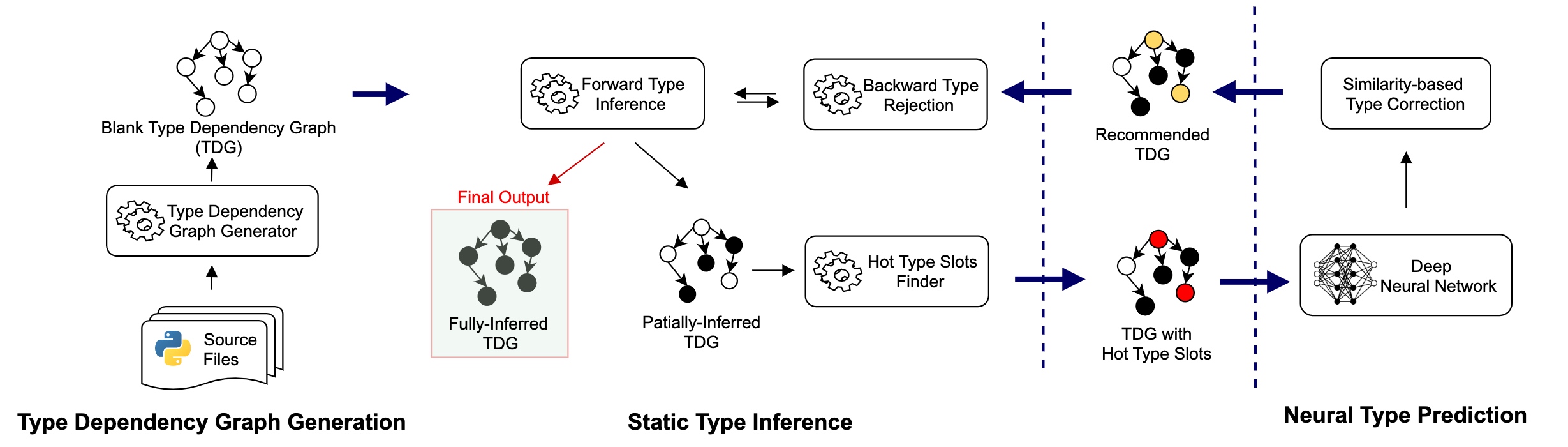

重点就是Backward Type Rejection的语义。

看了下,比如subscript的刻画还是很准确的,但是symbolic value的rejection rule还是会比sound 大一些。

Counter case



Asymmetry-aware Scalable Locking @PPoPP22
They've not been open-sourced! They may have to deploy on Huawei Qunpeng chassis or embed it into the Linux kernel. If I have time, I may reimplement this idea.
Both MCA lock and is not that applicable for heterogeneous cores in asymmetric multicore processors(big/little in Arm, Efficiency/Performance core in Alder Lake).
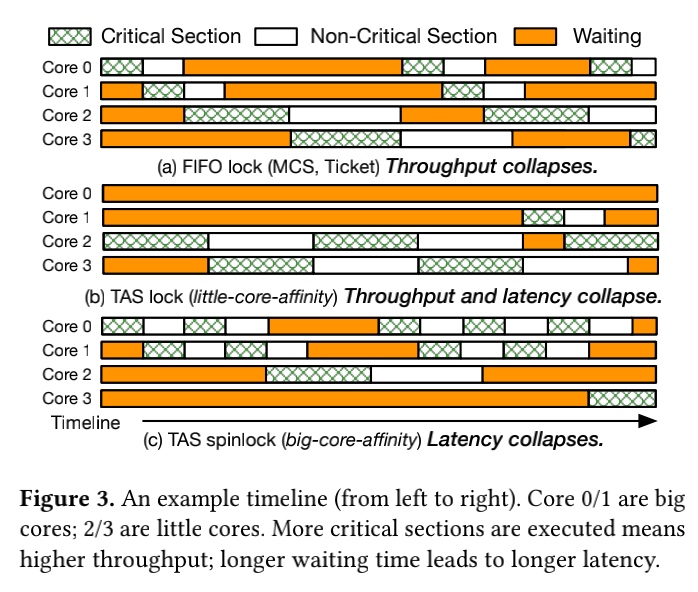
LibASL exposes the reorder capability as a configurable time window. Big cores can only reorder with little cores during that time window. Atop the reorderable lock, LibASL automatically chooses a suitable fine-grained reorder window according to applications' coarse-grained latency requirements through a feedback mechanism.


MCA lock

Basically a FIFO list on the lock bit, which combines the good of array-based queue lock and test_and_set ticket lock.
LibASL
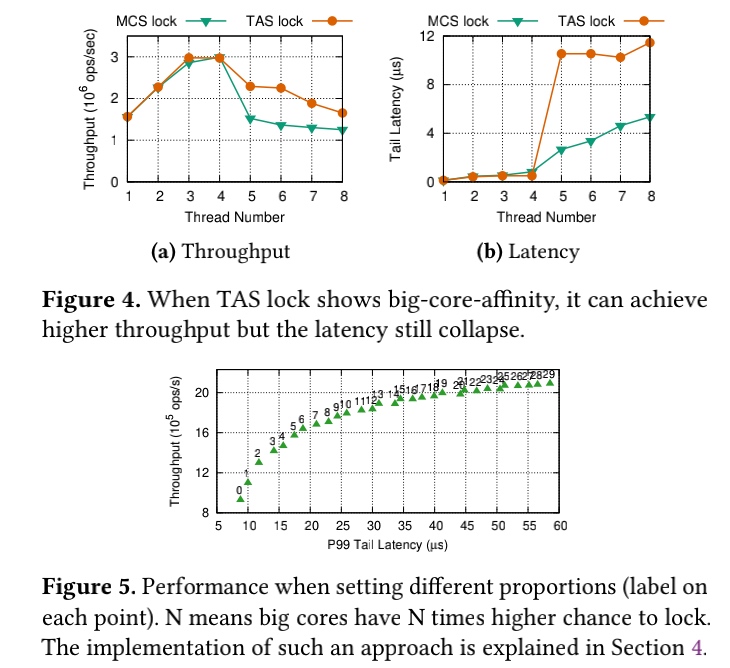
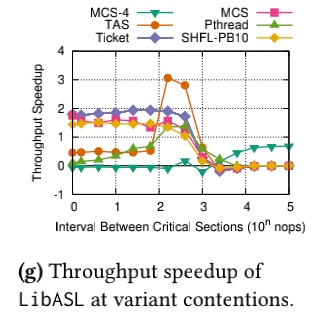
The queue in MCS can be a reorder window aware of the big little cores' latency SLO. Big cores and little cores are not competing for the same lock in big cores. In little cores, LibASL behaves similarly to the backoff spinlock. When they are competing for the same lock with heavy content, little core can be reordered with big cores' lock once the latency SLO is still met. Or the sweet spot will be found to saturate the lock for better throughput.
Refinement
The latency graph can be used to construct a reorder priority queue for the affinity of the big/little core transformation.
Reference
SegCache: a memory-efficient and scalable in-memory key-value cache for small objects NSDI 21'
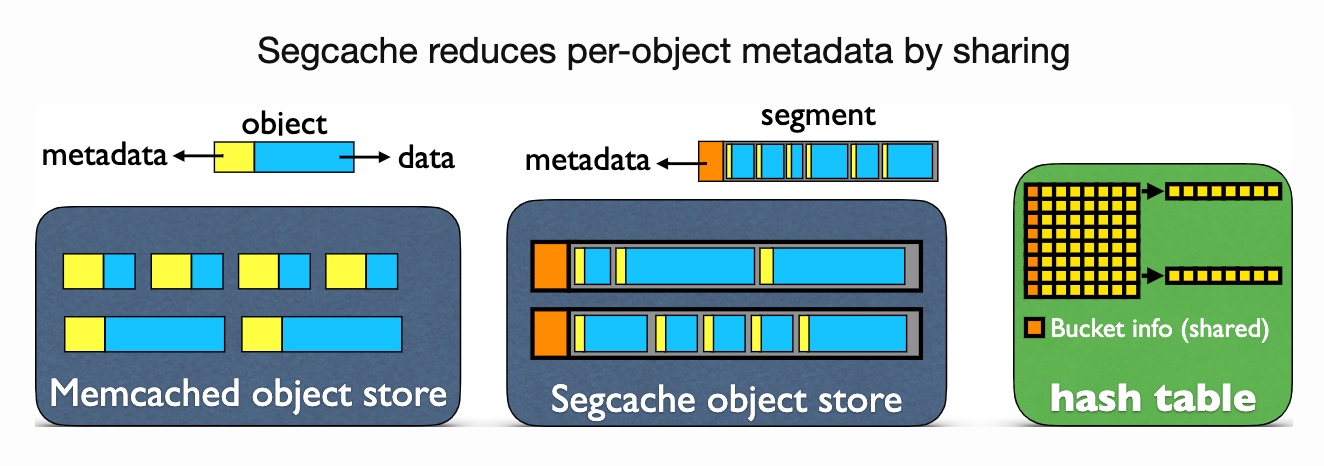
Yue Lu from Twitter, and collaborator Juncheng Yang and Rashmi from CMU. Pelikan (starting 2020), mostly written by Brian Martin(I really like his obsession to rust) is the current production in-memory cache for small data in twitter which is inspired by the traces captured with eBPF last year can do a smaller granularity analysis of memory cache.
EuroSys 22 Atendency

这次花了100💶。还是看看未来可能的合作者的文章长啥样。极其可恶的是我并没有被给予zoom权限,过了两天才拿到。