The foundation of trustzone
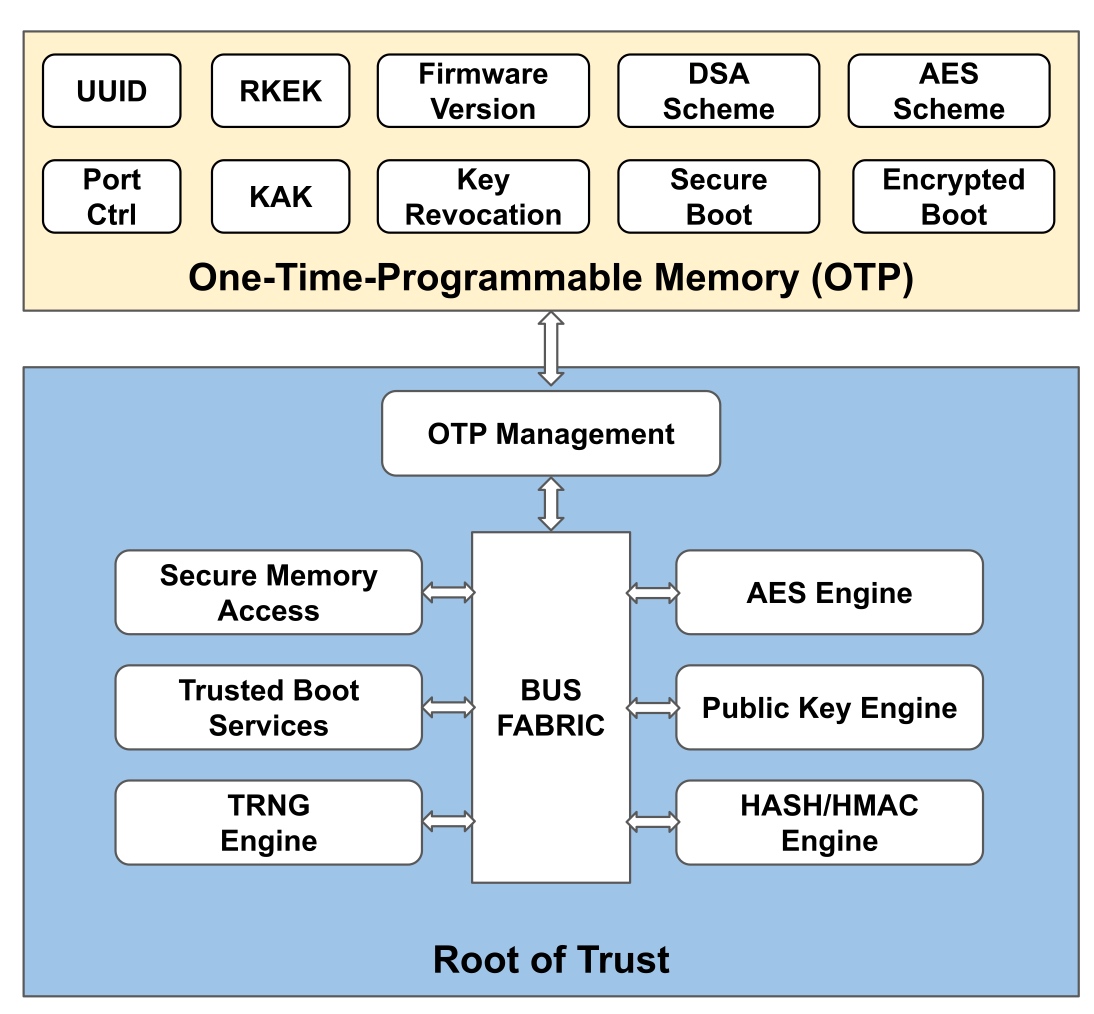
Here's the graph extrated from [1], essentially to tell the root of trust. A secure system depends on every part in the system to cooperate. For SGX, the Trusted Computing Base(Trusted Counter/ RDRAND/ hardware sha/ ECDSA) is the memory region allocated from a reserved memory on the DRAM called the Enclave Page Cache (EPC), which is initialized at the booting time. The EPC is currently limited to 128MB (in IceLake, was raised to 1TB with weakened HW support. Only 96 MB(24K*4KB pages) could be used, 32MB is for various metadata.) To prevent distruptions by physical attack or previledge software attack from cacheline-granularity modification, every cacheline can be assoiciated with a Message Authentication Code(MAC), but this does not prevent replay attack. To extend the trusted region of memory and do not introduce huge overheads, one solution is put the construct the merkle tree, that every cacheline of leaf is assured by MAC and root MAC is stored at EPC. Transaction Memory Abort with SGX can be leveraged to do page fault side-channel. The transaction memory page fault attack on peresistent memory is still under research.
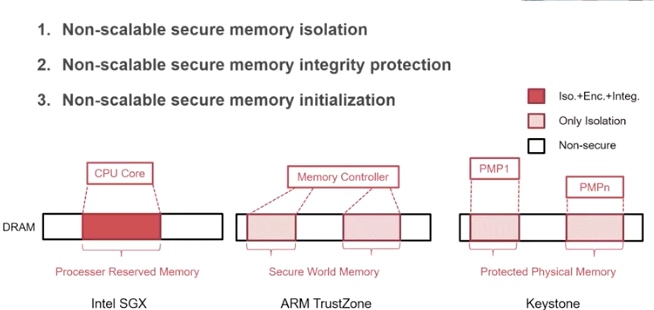
For Riscv, we have currently 2 proposals - Keystone and Penglai for enclave and every vendor has different implementations. Keystone essentially utilize M- mode PMP limited special registers the control permissions of U- mode and S- mode accesses to a specified memory region. The number/priority of PMP could be pre-configured. and the addressing is mode of naturally aligned power-of-2 regions (NAPOT) and base and bound strategy. The machine mode is unavoidable introduce physical memory fragmentation and waste: everytime you enter another enclave, you have to call M- mode once. Good Side is S/U- Mode are both enclaved by M- mode with easy shared buffer and enclave operation throughout all modes. Penglai has upgraded a lot since its debut(from 19 first commit on Xinlai's SoC to OSDI 21). The originality for sPMP is to reduces the TCB in the machine mode and could provides guarded page table(locked cacheline), Mountable Merkle Tree and Shadow Fork to speed up. However, it introduce the double PMPs for OS to handle, and overhead of page table walk could still be high, which makes it hard to be universal.
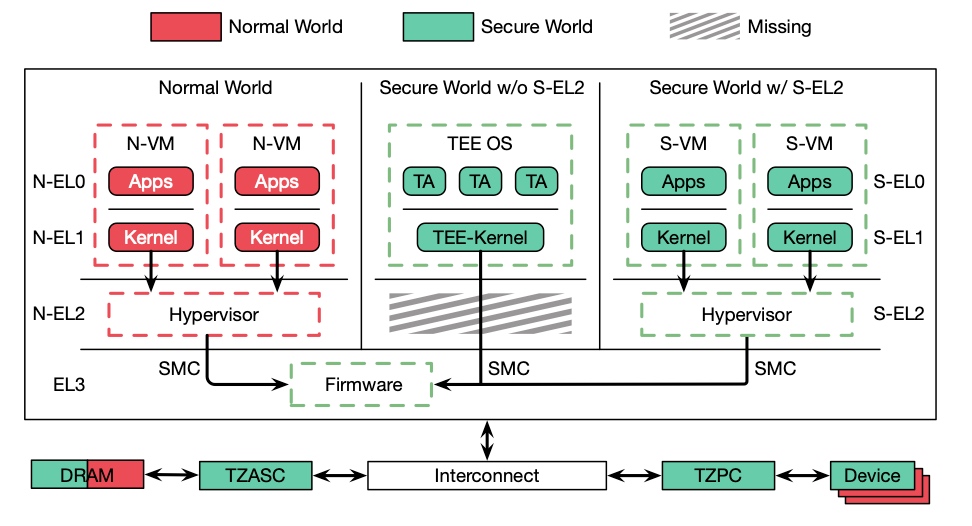
Starting from Penglai, IPADS continuously focus on S- mode Enclaves. One of the application may be the double hypervisor in the secure/non-secure S- Mode. The Armv8.4 introduce the both secure and non-secure mode hypervisor originally to support cloud native secure hypervisor. TwinVisor is to run unmodified VM images both as normal and confidential VMs. Armv9 introduce the Confidential Compute Architecture(CCA), another similar technology. TwinVisor is an pre-opensource implementation of it.
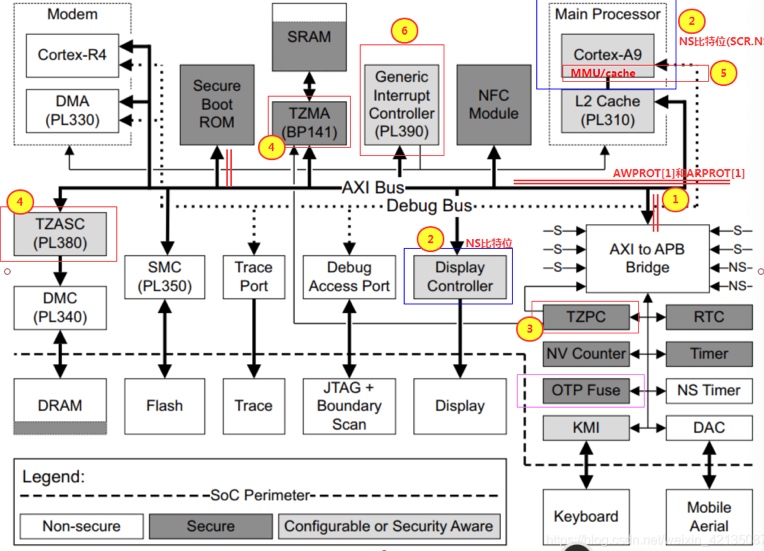
supported trustzone extention starting from Armv7.
- AMBA-AXI bus extension, adding the flags secure read and write address lines: AWPROT and ARPROT.
- extension of controller (or extension of master), adding SCR.NS bits inside ARM Core, so that operations initiated by ARM Core can be marked as "access initiated as secure or access initiated as non-secure".
- TZPC extension, TZPC is added to the AXI-TO-APB side to configure the apb controller privileges (or secure controller).
- TZASC extension, in the DDRC (DMC) on top of the addition of a memory filter.
- MMU support for security extensions:
- TTBRx_EL0, TTBRx_EL1 extension: In Armv7, these two registers are banked for secure and non-secure attributes, that is, there is a set of such registers in the secure and non-secure worlds, so in linux and tee, each can maintain a memory page table of its own. The secureos and monitor could share the page table if they are both 64 bits.
- cache extension: add the (non-)secure attributes.
- VSTTBR_EL2 extension: Since Armv8.4, when the non-secure world uses TTBR_EL2 to translate the address, the entry attribute is checked to be secure and will be translated by itself.

- GIC to secure extensions. The trap is devided into group0, secure group1 and non-secure group1. The group0 and secure group1 will not trap to linux.
Proposed Attack Model
The author mentioned physical attack or previledge software attack from N-VM to S-VM, this can be prevent by controlling the transmission channel.
TACTOC attack led by Shared Pages for General-purpose Registers, check-after-load way [50] by reading register values before checking them.
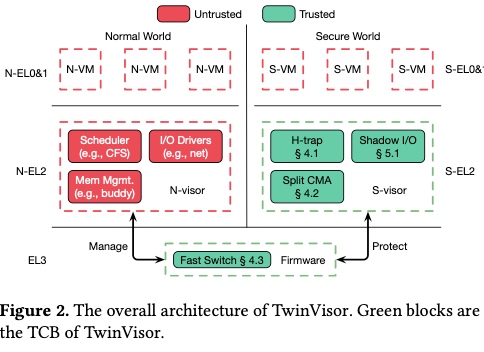
Design
-
Horisontal trap: modifies the N-visor to logically deprivledge N-visor without sharing the data. Exeptional Return(ERET) is the only sensitive instruction affect trusted chain, it intercepted by TZASC and repoted to S-visor.
-
Shadow S2PT: shadow page table of VSTTBR_EL2, used in kvm, too. It has page fault with different status when in different world.

-
Split Continuous Memory Allocation: Tricks to improves utilization and speed up memory management in Twinvisor. In linux, buddy allocator used to decide a continuous memory is big enough for boot and do CMA, this is for better performance of IOMMU that require physical memory to be continuous. (This deterministic algorithm makes it easy for memory probing and memory dump by e.g. row hammer/DRAMA ).
-
Efficient world switch: change NS bit in SCR_EL3 register in EL3, side core polling and shared memory to avoid context switches
-
Shadow PV I/O: use shadow I/O rings and shdow DMA buffer to be transparent to S-VMs. reduce ring overhead by do IRQ only when WFx instructions.
Experiment
Suppose
The world switch does not happen so frequently.
Hardware
Kirin 990. (Not scalable to Big machines, because KunPeng920 is not yet Armv8.4, scability is not convincible)


Reference
- A Survey on RISC-V Security: Hardware and Architecture TAO LU, Marvell Semiconductor Ltd., USA
- MIT 6.888
- ShieldStore: Shielded In-memory Key-value Storage with SGX
- Improving the Performance and Endurance of Encrypted Non-volatile Main Memory through Deduplicating Writes
- RiscV Spec 1.11
- Armv7 TZ
- lwn CMA and IOMMU