

FAAS对resource(CPU/Memory) disaggregation的map-reduce化?这显然是一个完全不考虑NUMA/NIC latency的考虑,就是在说dynamic memory allocation/placement大过latency的tradeoff,重点落在了怎么藏RDMA/NUMA的时延.但是为什么要套一个FAAS呢?然后就和MemTrade没啥大区别,只是多家了一套用户配置.
TMO: Transparent Memory Offloading in datacenters
Both of the papers are from Dimitrios
Memory offloading
Because the memory occupation on a single node is huge, we are required to offload them into far memory.
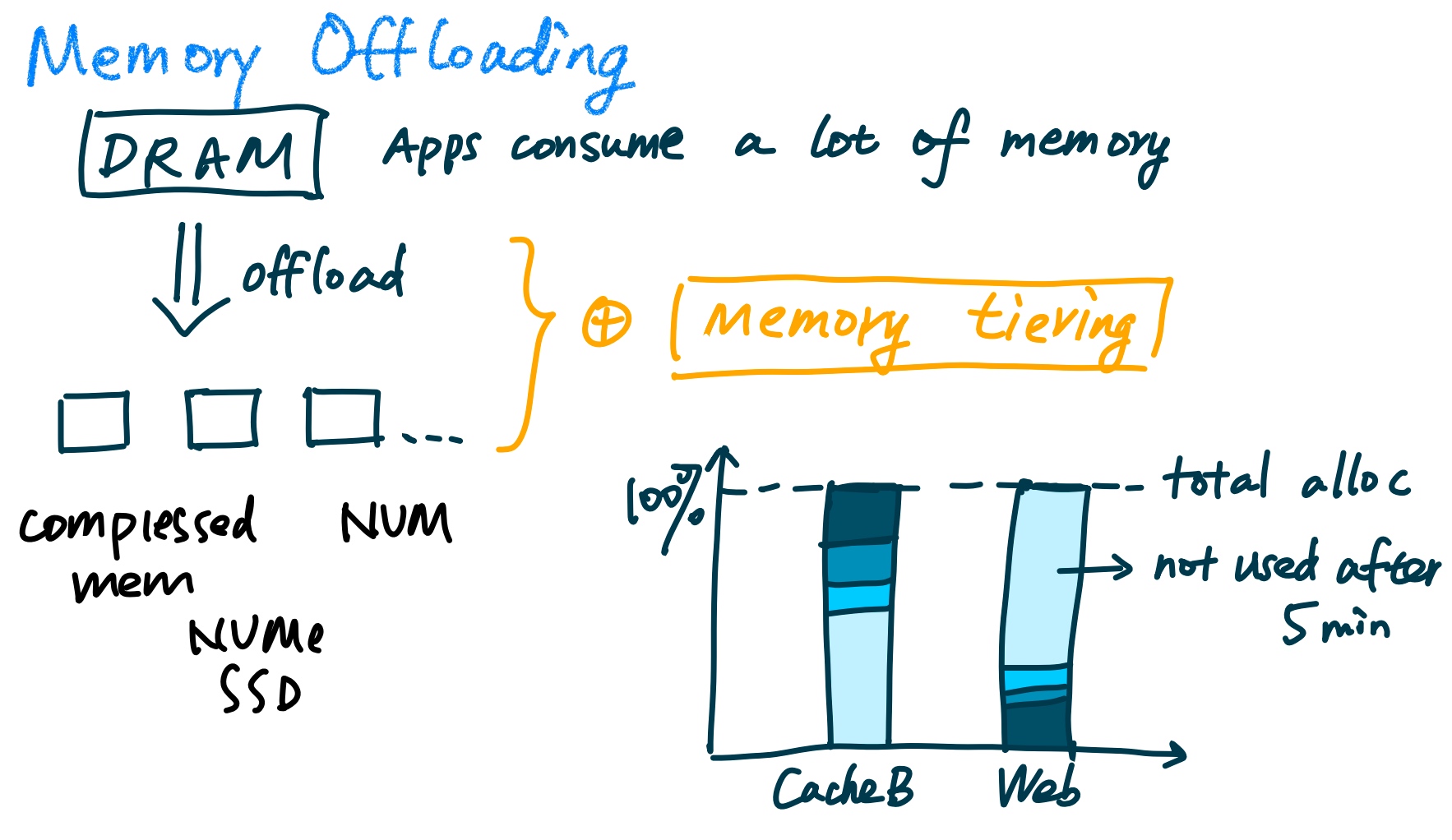
They have to model what the memory footprint is like. And what's shown in the previous work zswap, it only has a single slow memory tier with compressed memory and they only have offline application profiling, which the metric is merely page-promotion rate.
Transparent memory offloading
Memory Tax comes can be triggered by infrastructure-level functions like packaging, logging, and profiling and microservices like routing and proxy. The primary target of offloading is memory tax SLA.
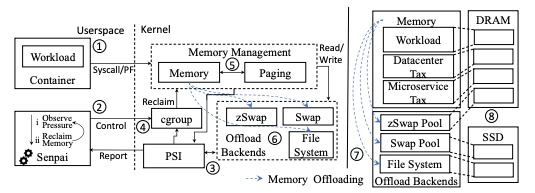
TMO basically sees through the resulting performance info like pressure stall info to predict how much memory to offload.
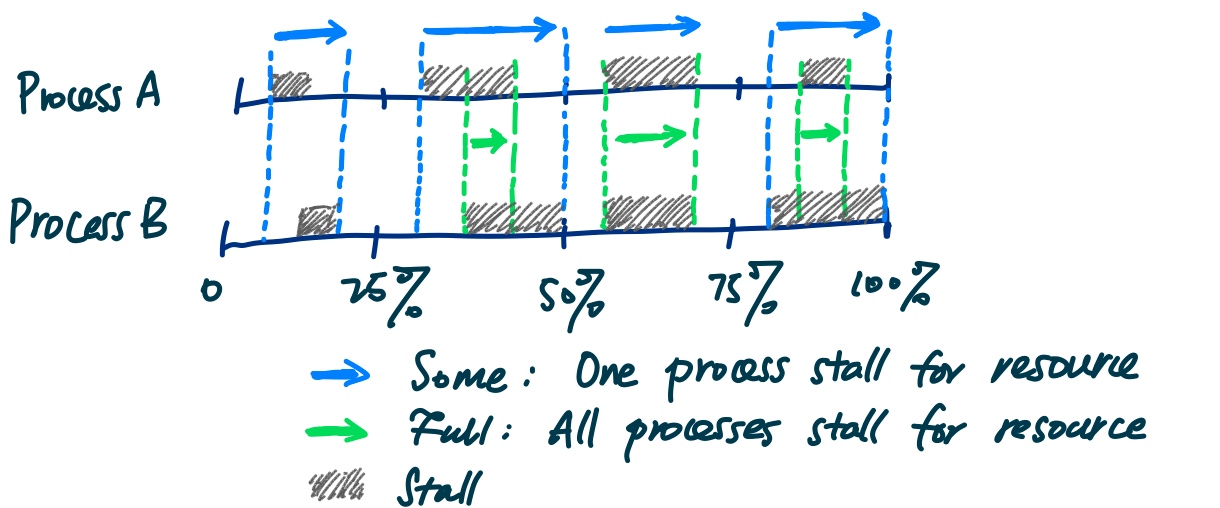
Then they use the PSI tracking to limit the memory/IO/CPU using cgroup, which they called Senpai.
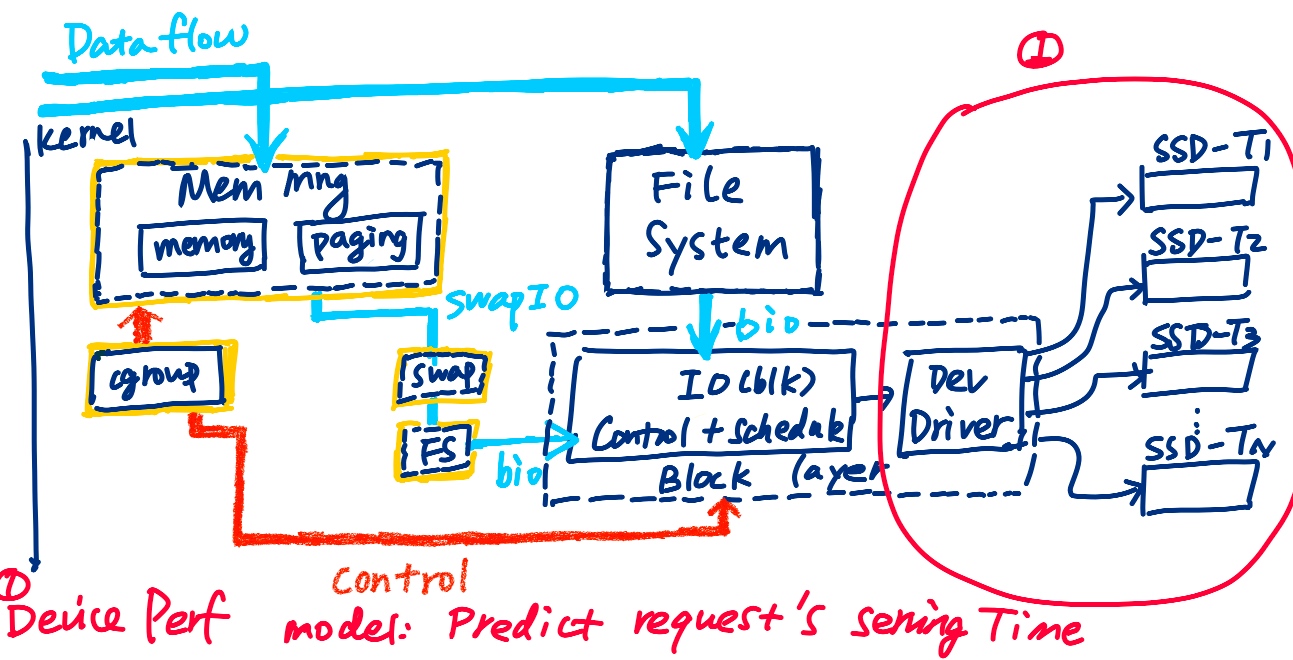
IOCost reclaims not frequently used pages to SSD.
Reference
- Jing Liu's blog
- Software-Defined Far Memory in Warehouse-Scale Computers
- Cerebros: Evading the RPC Tax in Datacenters
- Beyond malloc efficiency to fleet efficiency: a hugepage-aware memory allocator
TPP: Transparent Page Multi-tier CXL-Memory
CXL在这里的作用可以理解为External cache coherent agent,一个带CC的iMC,带宽肯定比NUMA高,但是这个工作只提升了18%,他们的策略是用PMU collect data,然后冷热load 和flush,给个temperature的grading,个人觉得肯定有page coloring那种优秀的算法搞定这件事,比这个数高。
MQSim
最近看的一个高精度multi-queue SSD模拟。
https://blog.csdn.net/Alieon/article/details/109920819
Application-Informed Kernel Synchronization Primitives
一个runtime dynamic profiling/loading guided lock primitive,可以同时兼顾到high/no lock contention的情况。
Continue reading "Application-Informed Kernel Synchronization Primitives"
IOring Windows at first sight and migration to `monoio`
最近在和LemonHX一起写个跨平台下载器,想要的是个延时确定的协程调度器,然后我们就看上了字节开源的monoio,准备贡献一波Windows部分。
主要需要跨平台抽象的部分已经写好了, GAT 刚进主线, 其实感觉贡献这个更经济一点. 字节内好像也没有开始用这个, 只是做了点测试.
Twizzler: a Data-Centric OS for Non-Volatile Memory
A Distributed NVM modeled OS runtime for the arrangement of NVM data structure that
- Does not require explicit (un)loading
- Less serialization (Context available persistent ptr to reduce memcpy).
- Has basic support for security/ share/ crash atomicity
Continue reading "Twizzler: a Data-Centric OS for Non-Volatile Memory"
The A-Z of my Ph.D. Trajectory
On Arrival
- Familiarizing Yourself with Your New Workplace and City. - Move in and buy stuff
- Search for gym/canteen
- good food for celebration/lowering weight food
重读的《Handbook of Model Checking》
此本书大一时就被宋老师隆重推荐,当时还有decision procedure、software foundation和熊英飞老师的程序分析部分。
宇宙中心Ph.D.的经济帐

听说还有人还梦想在计算机宇宙中心加州获得这个世界上最难拿的学位?
这事靠不靠谱?我来给你算一个经济帐。
先说结论,在工资水平方面,我没有我觉得我的博士学位能让我在职业生涯中领先很多。
但是对社会的overall贡献一定是更大的。