When I was browsing keystones‘ paper, they are applying a verification model called UCLID5, a new software toolkit based on z3 written in scala for the formal modeling, specification, verification, and synthesis of computational systems. The augmented efforts are merely making architectural implementations like NAPOT/S mode world change/exceptions in pmp reg mapping policy to Hoare logic and do the verification. To a greater extent, the Y86-64 introduced in CSAPP is verified by UCLID5, too.

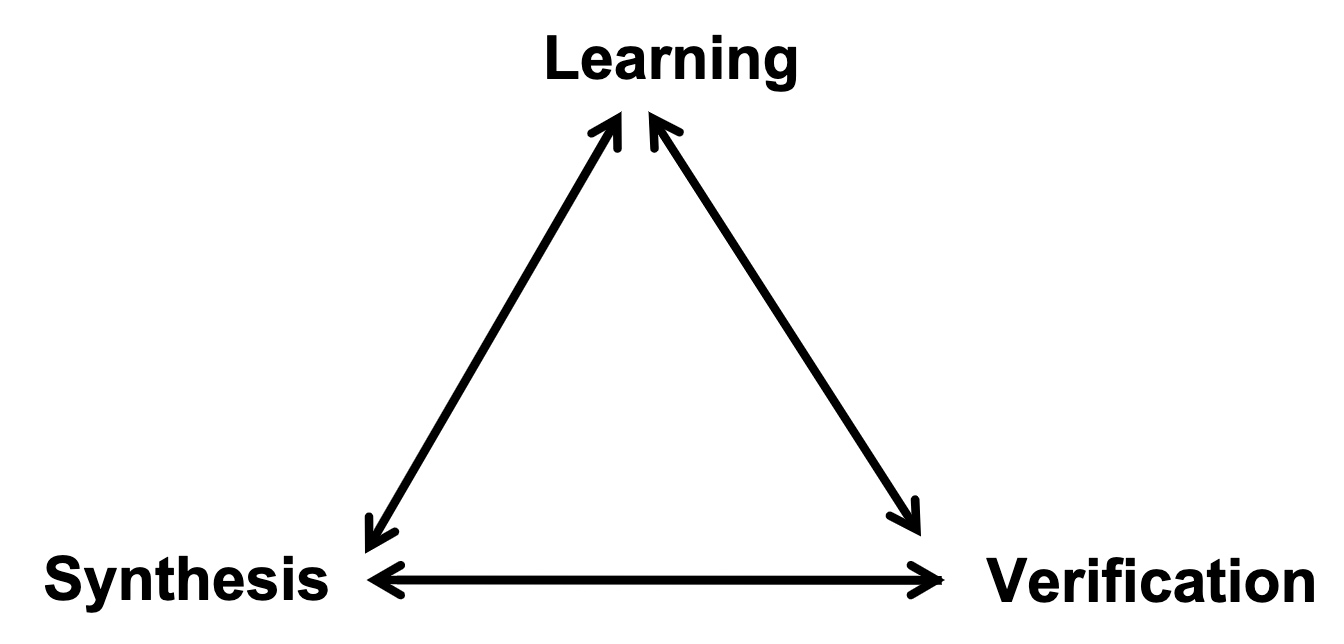
The Goals
- Enabling modular modeling of finite and infinite-state transition systems across a range of concurrency models and background logical theories.
- Performing a highly-automated, compositional verification of a diverse class of specifications, including pre/post conditions, assertions, invariant, LTL, refinement and hyperproperties
- Integrating modeling and verification with algorithmic synthesis and learning.
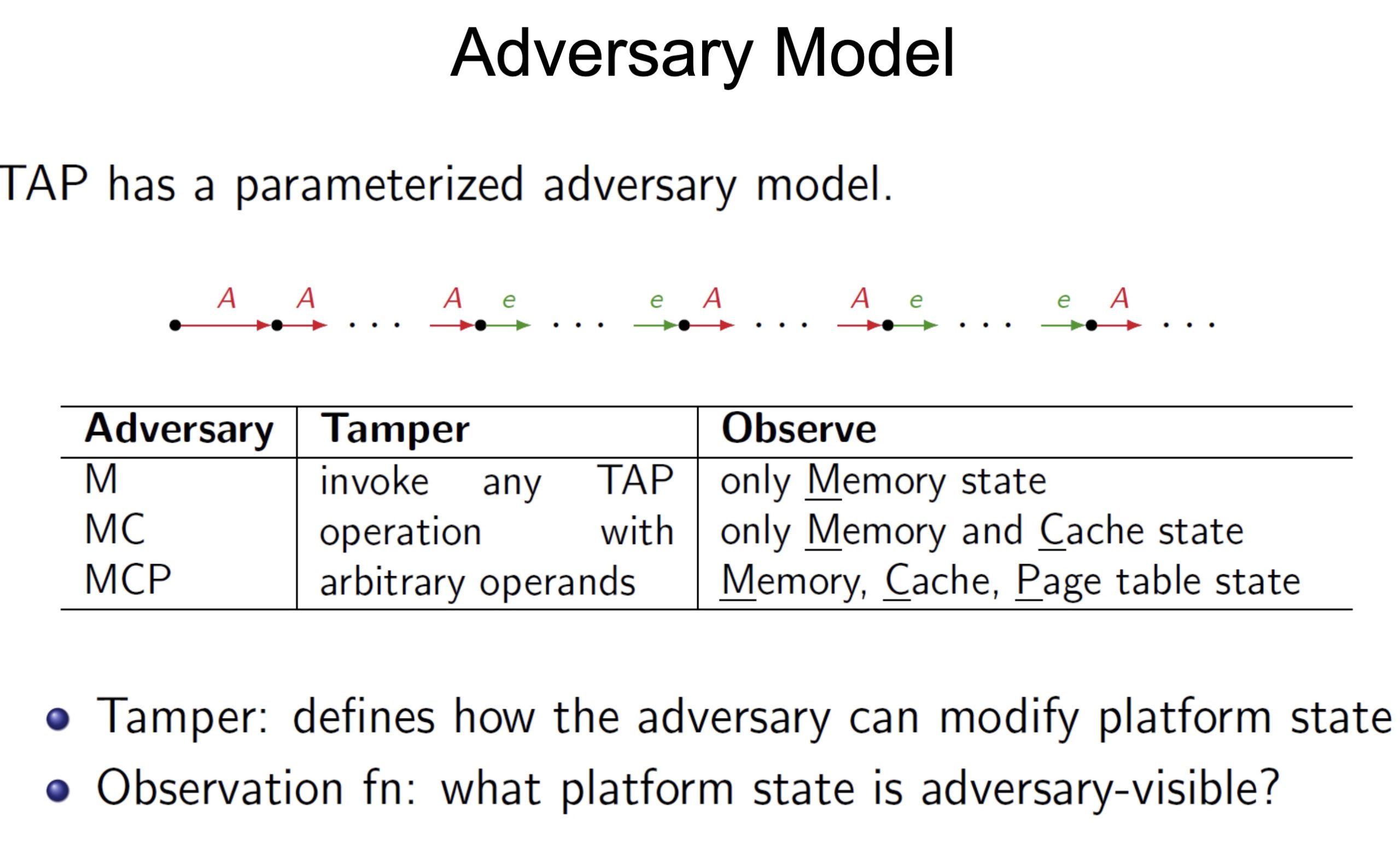
threat models
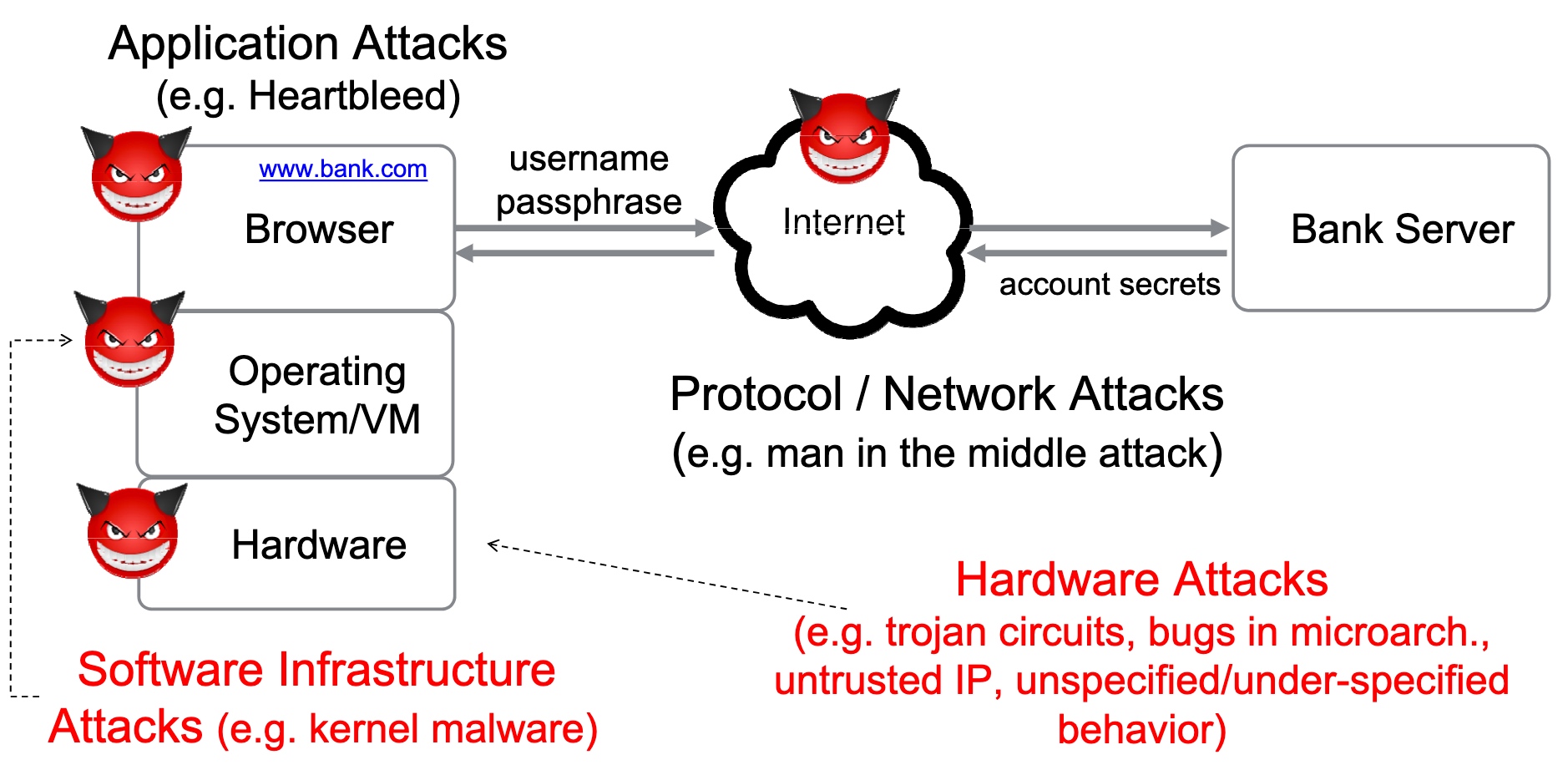
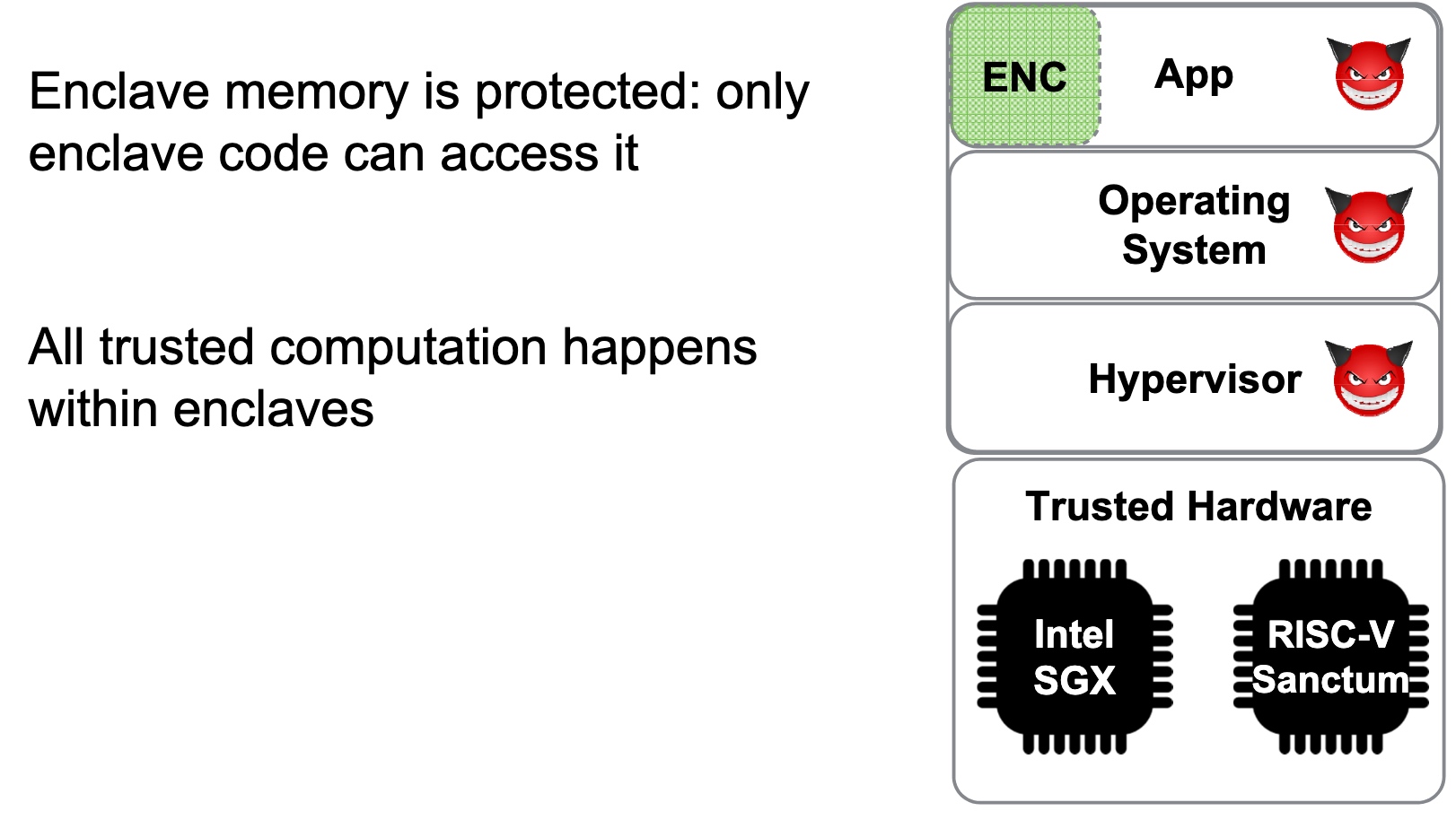
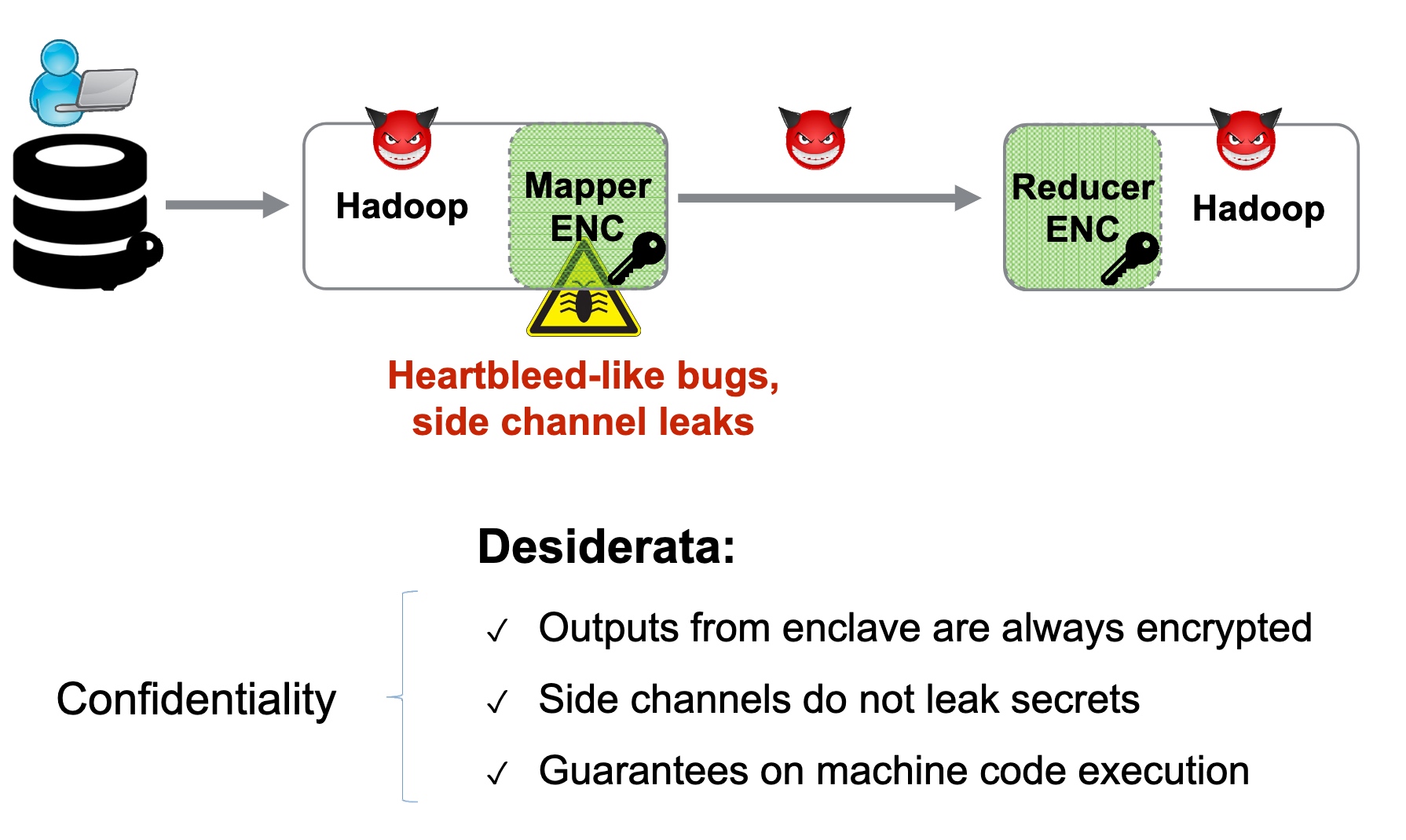
SRE
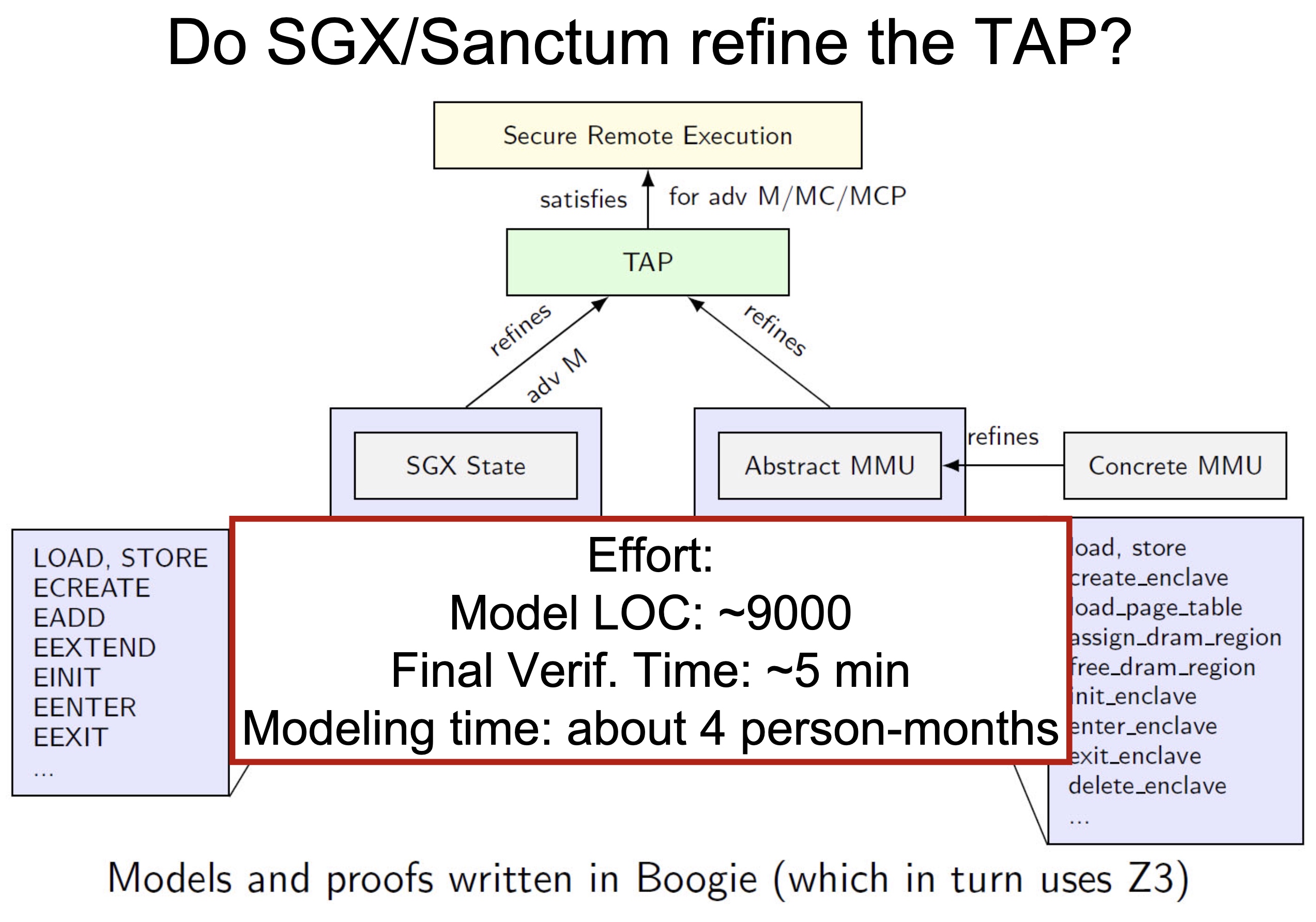
Heartbleed-like attack, side channels, and Meltdown/Spectre are also cast a lot on SGX/TEE. Stuff like secure remote extensions using trusted platforms is introduced. They formalized the enclave platform and made remote execution trustworthy.
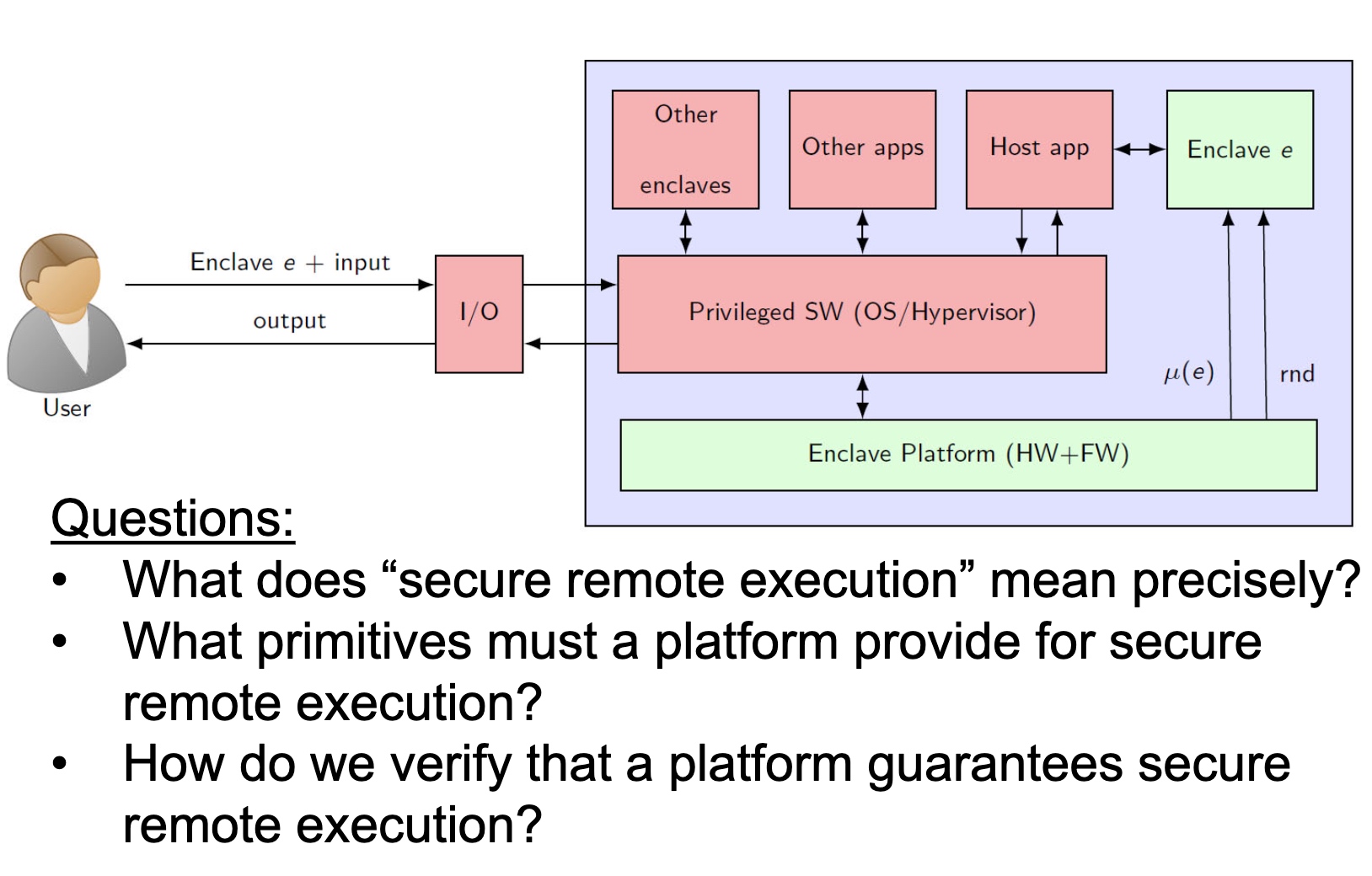
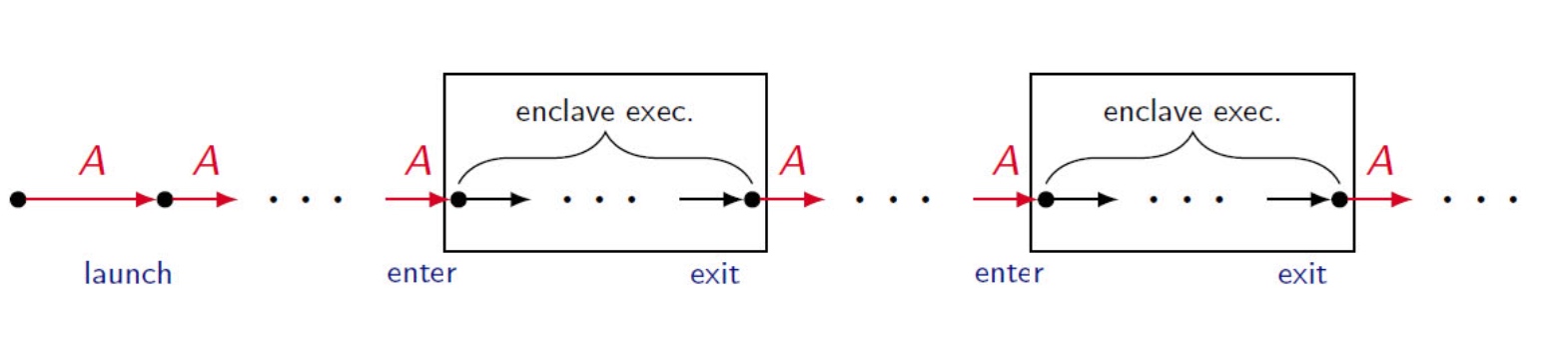
embodying enclave and adversary



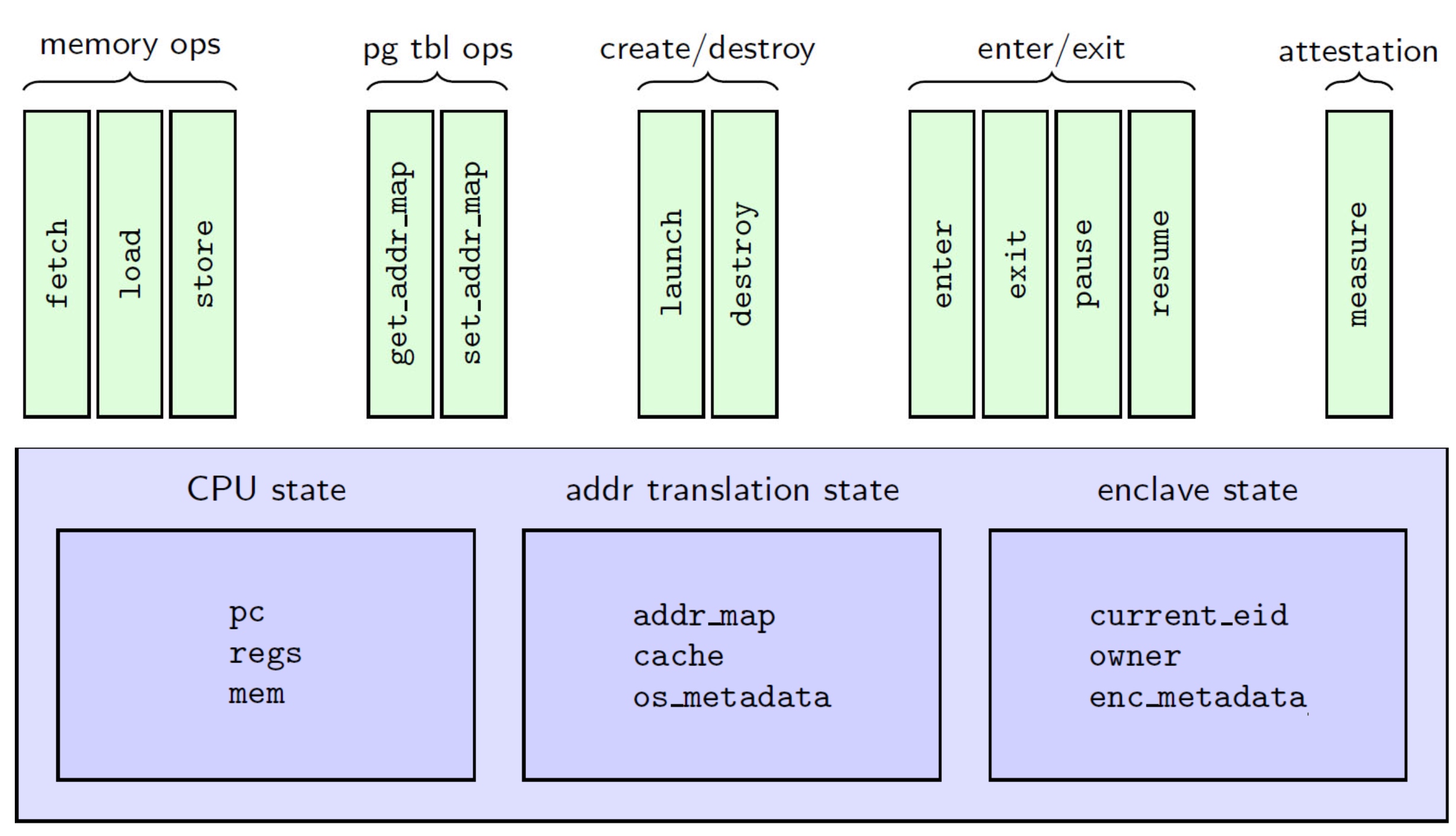
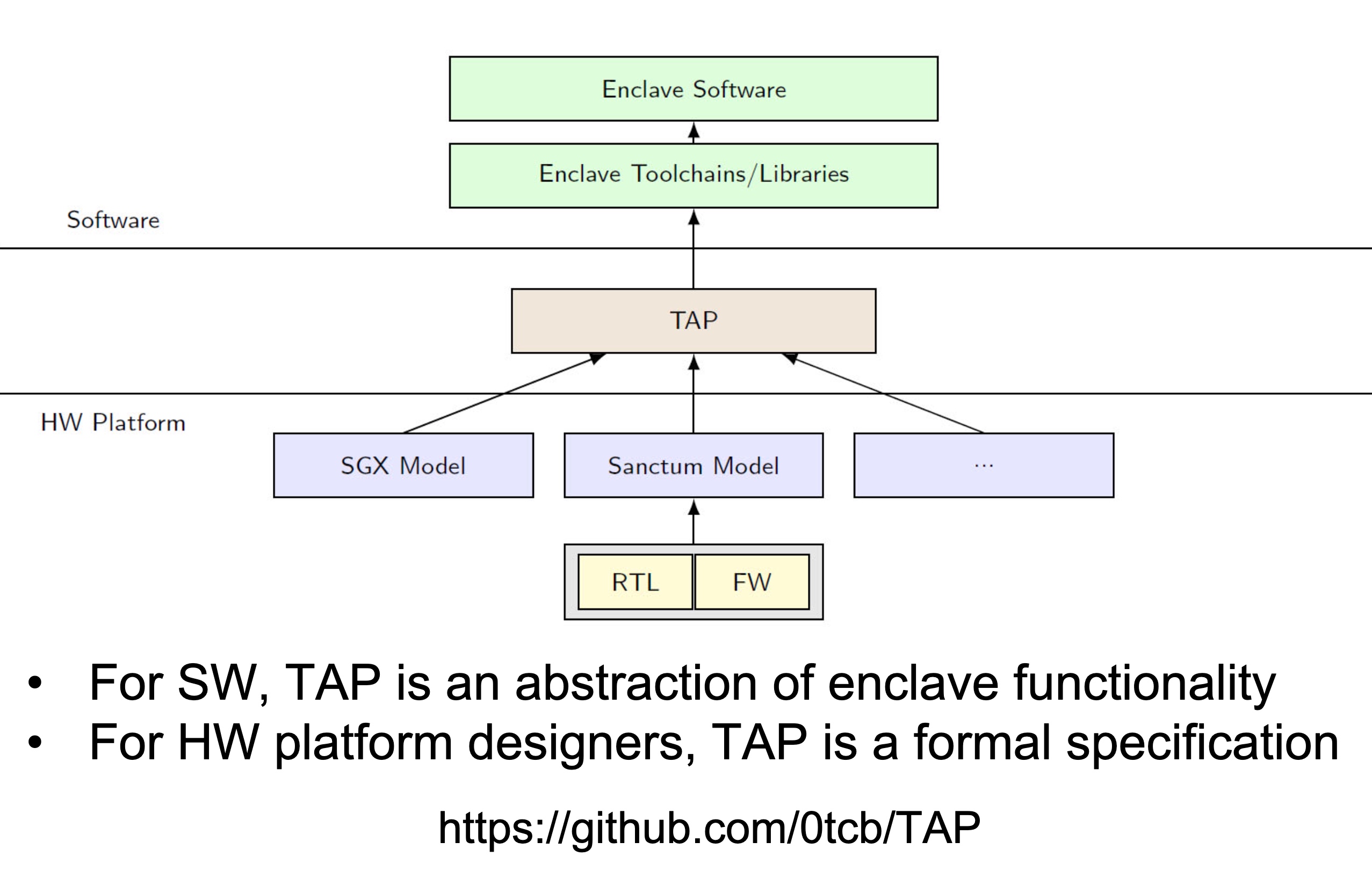

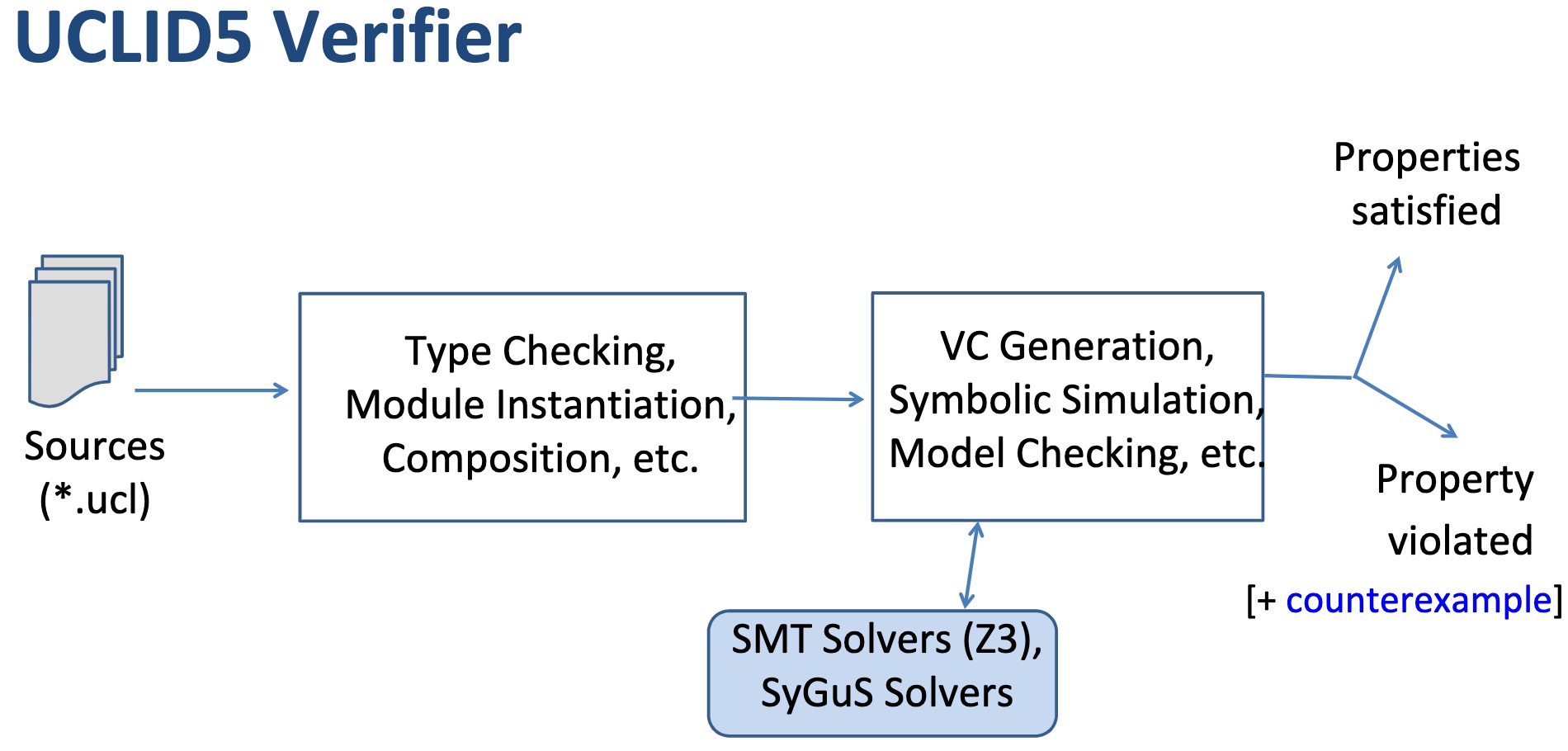
UCLID5 verifier


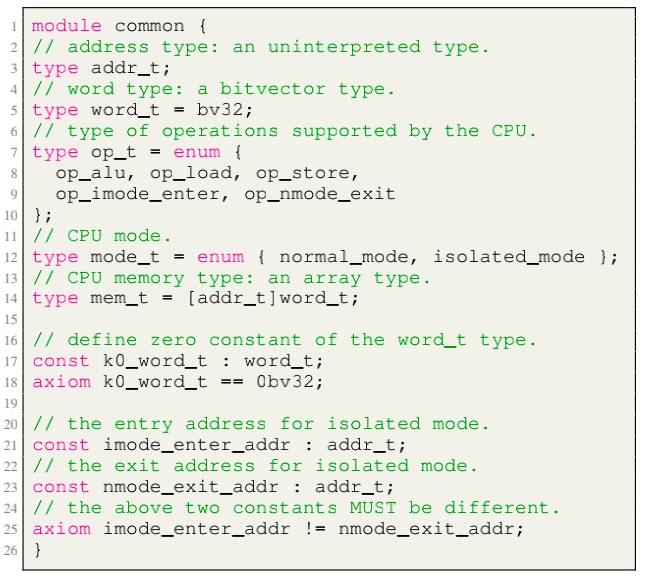
Modules, like LLVM, serve as the unit of re-use when declaring commonly used types, symbolic constants, and uninterpreted functions. The module uses uninterpreted functions to model instruction decoding (inst2op, inst2reg0 etc.) and instruction execution (aluOp and nextPC). Further, the register file index type (regindex_t) and the address type (addr_t) are both uninterpreted types. This abstraction is sufficient to model all kinds of CPU implementation.
Structure of the CPU Model:
- Module common: serves as top-level type definition.
- Module cpu: defining the initial sate like reg/pc/imem/dmem, types are mode_t(isolated/normal) word_t addr_t(a range of addresses between
isolated_rng_loandisolated_rng_hi) init/next/exec_inst defines the transition system.

- Module main: the environmental assumptions for the verification and contains a proof script that proves, via induction, a 2-safety integrity property for the CPU module.

Other features
- Term-Level Abstraction: In term-level abstraction, concrete functions or functional blocks are replaced by uninterpreted functions or partially-interpreted functions. Concrete low-level data types such as Booleans, bit-vectors, and finite-precision integers are abstracted away by uninterpreted symbols or more abstract data types (such as the unbounded integers).
- Blending Sequential and Concurrent System Modeling:
- Diversity in Specification
- Procedure specifications.
- Invariant
- while
- assume
- assert
- LTL
- Hyperproperties(k-safety): composing k copies of the system together and specifying a safety property on the resulting composition
- Procedure specifications.
- Modularity in Modeling and Specification
- Counterexample Generation
- Modular Proof Scripting